ترجمههای کامران بزرگزاد

چه کسانی از این کتاب بهره
میبرند؟
شیوههای بکار رفته در این
کتاب
چه ویژگیهای جدیدی در C++11 وجود دارند؟
اجزاء مختلف برنامه Hello World
عملیات اصلی ورودی و خروجی
با استفاده از std::cin و std::cout
استفاده
از متغیرها و
اعلان ثابتها
اعلان متغیرها برای دسترسی و
استفاده از حافظه
اعلان چند متغیر که همه از
یک گونه هستند و مقداردهی آنها در یک خط
اجرای دستورات شرطی با
استفاده از if
… else
سازماندهی
برنامه با استفاده از توابع
چرا در برنامهنویسی نیاز داریم تا
از توابع استفاده کنیم؟
گونهِ عملگرها و سربارگزاری عملگرها
چرا در میان برخی از برنامهنویسان C++ روشهای
تبدیل گونه سبک-C طرفدار ندارد
استفاده از ماکروی #define برای
تعریف ثابتها
مقدمهای بر کتابخانه
استاندارد الگو (STL)
لزوم استفاده از کلاسهای رشتهای
کلاسهای مربوط به آرایههای پویا در STL
عملیات معمول در کلاس std::vector
کلاسهای list و forward_list در STL
مقدمهای بر کلاسهای set در STL
عملیات اصلی بر روی set و multiset
مقدمهای بر کلاسهای map در STL
عملیات اصلی بر روی map و multimap
چگونه یک عبارت لاندا را تعریف کنیم؟
عبارات لاندا بعنوان یک
تابع یگانه
عبارات لاندا بعنوان یک
محمول یگانه
گنجانههای انطباقی: پُشته و
صَف
استفاده از std::bitset
و اعضای آن
آشنایی
بیشتر با اشارهگرهای
هوشمند
اشارهگرهای هوشمند چگونه پیادهسازی میشوند؟
انواع مختلف اشارهگرهای هوشمند
استفاده
از جریانها برای انجام عملیات
ورودی و خروجی
کلاسها و جریانهای مهم در C++
جلوگیری از اعتراضات توسط try و catch
تفاوت پردازندههای امروزی در چیست؟
سال 2011
برایC++
یک سال ویژه بود. با تصویب استاندارد جدید این زبان،
که C++11
نامیده میشود، شما قادر خواهید بود تا با استفاده از کلیدواژهها (keywords) و سازههایی (constructs)
که جدیداً به این زبان اضافه شده، برنامههای بهتری بسازید که بازدههی آنها به شکل
چشمگیری افزایش یافته. این کتاب شما را یاری خواهد داد
تا با پیمودن قدمهای کوتاه بتوانید C++
را یاد بگرید. کتاب به درسهایی تقسیم شده که اصول این زبان شیءگرا (object-oriented) را با رویکردی عملی
به شما آموزش میدهد. بسته به میزان مهارتی که دارید، شما قادر خواهید بود تا در
ظرف یک ماه، و تنها با صرف یک ساعت وقت، بر C++11
تسلط پیدا کنید.
بهترین
روش برای یادگیری C++11
داشتن یک رویکرد عملی است. بنابراین سعی کنید تا با مثالهای مختلفی که در این
کتاب آمده مهارتهای برنامه نویسی خود را بهتر کنید. این برنامهها توسط دو کامپایلر مهم
این زبان، یعنی
ویژوال C++ 2012 و
GNU
C++ نسخه 4.6 آزمایش شدهاند. هر دو این کامپایلرها، بسیاری از ویژگیهای جدید C++11
را پوشش میدهند.
این کتاب
با اصول ابتدایی C++
شروع میشود. تنها چیزی که برای خواندن این کتاب لازم است
اشتیاق به یادگیری C++ و کنجکاوی برای فهم چگونگی
عملکرد آن است. آشنایی قبلی با این زبان میتواند مزیت مهمی
باشد، اما پیشنیازی برای خواندن کتاب نیست. درصورتی که
قبلاً C++
را یادگرفتهاید، این کتاب میتواند بعنوان مرجعی بحساب آید که شما برای یادگیری
ویژگیهای جدیدِ این زبان به آن مراجعه میکنید. درصورتی که یک برنامهنویس حرفهای
هستید، بخش سوم کتاب با عنوان ”آموزش کتابخانه استاندارد الگو (STL)“ میتواند به شما کمک کند تا برنامههای کاربردی بهتری با C++ بنویسید.
بسته به
میزان مهارت فعلی
شما در C++،
میتوانید خواندن کتاب را از فصل مورد نظرتان شروع کنید. این کتاب به پنج بخش
تقسیم شده:
§
بخش 1، تحت عنوان ”مقدمات“، شما را برای نوشتن
برنامههای ساده به زبان C++
آماده
میکند. این بخش کلیدواژههایی را که در بیشتر برنامههای C++
دیده میشوند به شما معرفی خواهد کرد.
§
بخش 2، تحت عنوان ”اصول برنامهنویس شیءگرا“، مفهوم کلاس را آموزش میدهد. در این
بخش شما یاد میگیرید که چگونه C++
از اصول مهم برنامهنویسی شیءگرا،
مثل بستهبندی (encapsulation)، مجردسازی (abstraction)،
وراثت (inheritance)، و چندریختی (polymorphism)، پشتیبانی میکند. درس 9، با عنوان ”کلاسها و اشیا“، مفهوم ”سازندهِ انتقال“ (move constructor)
را به شما یاد میدهد و بدنبال آن در درس 12، با عنوان ”گونهِ
عملگرها و سربارگزاری عملگرها“ مفهوم ”عملگرِ جابجاکننده نسبتدهی“ (move
assignment operator) مورد بررسی قرار میگیرد. این ویژگیهای جدید موجب کاستن از مراحل ناخواسته و
غیرلازمِ کپی میشوند و در نتیجه اجرا برنامه شما تسریع
خواهد شد. درس 14، با عنوان ”مقدمهای بر ماکروها و الگوها“ شروعی برای نوشتن کدهای
عام (generic) در C++
است.
§
بخش 3، تحت عنوان ”آموزش کتابخانه استاندارد الگو (STL) “، به شما کمک خواهد کرد تا با استفاده از
کلاسِ رشتهای STL،
و همچنین گنجانهها (containers)،
برنامههای عملی و کارآمدی بنویسید. شما یاد خواهید گرفت که
کلاس std::string چگونه عملیات الحاق رشتهها
را سادهتر و ایمنتر میسازد، و اینکه دیگر نیازی به استفاده از
رشتههای سبک-C که بصورت char*
هستند، و در زبان C از آنها استفاده میشود، نخواهد بود. شما میتوانید بجای اینکه خودتان اقدام به ساختن آرایههای پویا و لیستهای پیوندی کنید، از گنجانههای موجود در STL استفاده کنید.
§
بخش چهارم، تحت عنوان ”توضیحات بیشتر در مورد STL“، بر روی الگوریتمها تمرکز میکند. شما یاد خواهید گرفت که چگونه با استفاده از تکرارکنندهها (iterators) عمل مرتبسازی را بر
روی گنجانههایی چون vector انجام دهید. در این بخش شما متوجه خواهید شد که
کلیدواژه جدیدِ
auto
چقدر موجب صرفه جویی در تعریف تکرارکنندههای شما میشود. درس 22 با عنوان ”عبارات لاندا در C++11“،
ویژگی جدید و قدرتمندی به شما معرفی میشود که بکارگیری آن کاهش قابل ملاحظهای در حجم برنامههای نوشته شده بوجود میآورد.
§
بخش پنجم، تحت عنوان ”مفاهیم پیشرفته C++“،
به قابلیتهایی از این زبان میپردازد که کاربردِ آنها در C++
اجباری نیست ولی سهم عمدهای در کیفیت و ثبات برنامه بازی میکنند.
مفاهیمی مثل اشارهگرهای هوشمند (smart pointers)، و رسیدگی به اعتراضات (exception-handling) از این جمله هستند.
این کتاب با ذکر بهترین شیوههایی که میتوان با پیروی از آنها یک برنامه خوب C++11
نوشت پایان خواهد یافت.
شما در متن
درسهای کتاب به عناصر زیر برخورد خواهید کرد که اطلاعات بیشتری درباره موضوع مورد
بحث به شما ارائه میدهند:
C++ 11
این موارد
ویژگیهای جدیدی که در C++11
وارد شده را مورد تاکید قرار
میدهد. ممکن است شما برای بهرهبرداری
از قابلیتهای جدید نیاز داشته باشید تا از نسخههای
جدید کامپایلرها استفاده کنید.
به کتاب خودآموز
C++
در یک ماه، و صرف یک ساعت در روز خوش آمدید. حالا شما آمادهاید تا دوره آموزشی خود را برای اینکه یک
برنامهنویس ماهر C++
شوید شروع کنید.
در این
درس شما یادخواهید گرفت که:
§ چرا زبان C++
یک استاندارد در توسعه نرمافزار محسوب میشود؟
§ چگونه اولین برنامه خود به C++ را وارد، کامپایل، و سپس لینک کنید؟
§ چه ویژگیهای
جدیدی در C++11
وجود دارند؟
هدف یک
زبان برنامهنویسی سهولت بخشیدن به استفاده از منابع کامپیوتری
است. هر چند C++
یک زبان جدید نیست، با اینحال از آن دسته زبانهایی است که هنوز محبوب، و درحال
توسعه است. جدیدترین نسخه این زبان که به تصویب کمیته استاندارد ISO رسیده C++11
نام دارد.
C++، که اولین بار در سال 1979
توسط بییارنه استراستروپ (Bjarne Stroustroup) در آزمایشگاههای شرکت بل توسعه داده شد، به این منظور طراحی شده بود که جانشین زبان C باشد. C یک زبان رویهای (procedural) است، که در آن از
توابع برای انجام کارهای معین استفاده میشوند. از سوی دیگر C++ طوری
طراحی شده بود که یک زبان شیءگرا باشد، و در آن مفاهیمی چون وراثت،
مجردسازی، چندریختی، و بستهبندی پیادهسازی شوند.
در C++
ویژگی جدیدی بنام کلاس وجود دارد که از آن برای نگاهداری عضوهای دادهای (member data) و عضوهای مِتُدی (member methode) استفاده میشود. ”عضوهای مِتُدی“ برروی ”عضوهای دادهای“ عمل میکنند.
این ِمتُدها شبیه توابع در زبان C هستند. حاصل این
رویکرد این است که برنامهنویس تمرکز خود را بر روی دادهها، و آنچه
که میخواهد با آنها انجام شود، میگذارد.
کامپایلرهای C++ بصورت سنتی از زبان C نیز پشتیبانی میکنند.
بدلیل اینکه C++ قادر است با کدهای نوشته شده قدیمی Cسازگار باشد، از این لحاظ برای آن یک مزیت
بشمار میرود؛ ولی از سوی دیگر این عیب را نیز دارد که چون C++
باید سازگاری خود را با کدهای قدیمی C حفظ کند، و در عین حال
کلیه ویژگیهای یک زبان شیءگرای مدرن در آن پیادهسازی
شود، همین باعث میشود تا طراحی کامپایلرهای این زبان به طرز
فزایندهای پیچیدهتر شوند.
C++ یک زبان سطح متوسط
بحساب میآید، و این یعنی C++
نه سطح بالا است و نه سطح پائین. از این زبان میتوان برای نوشتن برنامههای
کاربردی سطح بالا، و همچنین برنامهنویسیهای
سطح پایین، نظیر گردانندههای دستگاه (device driver)، که بصورت نزدیکتری
با سختافزار کار میکنند، استفاده کرد. C++ برای بسیاری از برنامه نویسان تسهیلاتی را فراهم میکند که در آن میتوان
از مزیای یک زبان سطح-بالا بهره بُرد و برنامههای
کاربردی پیچیدهای را تولید کرد، و درعین حال این زبان انعطاف لازم را در اختیار
برنامه نویس قرار میدهد تا با کنترل دقیقِ استفاده از منابع، بهترین کارایی ممکن
را حاصل کند.
علیرغم حضور بسیاری از زبانهای برنامهنویسی جدید، مثل Java، و یا آنهایی که بر پایه .NET
قرار دارند، C++
همچنان مطرح و در حال تکامل است. زبانهای امروزی، ویژگیهای
خاصی مثل مدیریت حافظه از طریق جمعآوری زُباله (garbage collection) را ارائه میدهند که در مؤلفه حیناجرا (runtime)
آنها پیادهسازی شده،
و این باعث میشود تا این زبانها از نظر برخی برنامهنویسان محبوبتر باشند. بااینحال، اغلب این برنامهنویسان وقتی نیاز به کنترل دقیق عملکرد برنامه خود دارند، بازهم C++
را انتخاب میکنند. یک نمونه معمول این مورد، یک برنامه
چند لایه اینترنتی است که در آن سرویس
دهندهِ وب (web server)
به زبان C++
برنامه ریزی میشود، در حالی که برنامه مقدم (front-end) به HTML, Java و یا .NET نوشته میشود.
سالها
تکامل تدریجی C++ باعث شده تا این زبان بصورت گستردهای مورد استقبال قرار
گیرد. هرچند بدلیل وجود انواع مختلف کامپایلرهای آن، که هر یک خصوصیات مخصوص به خود را دارند، شکلهای مختلفی از این زبان وجود دارد. این اشکال مختلف باعث شده تا مشکلات زیادی
در قابلیتِ حملِ برنامههای نوشته شده به این زبان و تبدیل آنها به یکدیگر بوجود
آید. از این رو، نیاز به این پیدا شد که این زبان باید کلاً بصورت استاندارد
درآید.
در سال 1998، اولین استاندارد زبان C++
توسط کمیته ISO
با شماره 14882:1998 به تصویب رسید. بدنبال آن در سال 2003 در
این طرح بازبینیهای بعمل آمد که به (ISO/IEC 14882:2003) معروف شد. نسخه فعلی
استاندارد C++
در ماه اگوست 2011 به تصویب رسید. این نسخه بصورت رسمی C++11
نامیده شد (ISO/IEC 14882:2011)
و حاوی برخی از جاهطلبانهترین
و مترقیترین تغییراتی است که تابحال این زبان به خود دیده
است.
بسیاری از مستندات موجود در اینترنت هنوز هم
به نسخهای
از C++ اشاره میکنند که C++0x نامیده میشود. انتظار میرفت که استاندارد جدید در سال 2008 یا 2009 تصویب شود، و x
هم بجای سال بکار رود. سرانجام استانداردِ جدیدِ پیشنهاد شده در
آگوست 2011 پذیرفته شد وC++11 نام گرفت.
بعبارت دیگر، C++11 همان C++0x است که در سال 2011 تصویب شد.
صرف نظر
از اینکه شما چه کسی باشید و چه کاری انجام میدهید،
خواه یک برنامه نویس حرفهای باشید و خواه کسی که گاه و بیگاه
از کامپیوتر برای مقاصد خاصی استفاده میکند، به احتمال زیاد
بطور پیوسته از برنامهها و کتابخانههای
نوشته شده به زبان C++ استفاده میکنید. از سیسمعاملها گرفته تا گردانندههای دستگاه (device drivers)،
نرمافزارهای اداری، سرویسدهندههای وب، برنامههای مبتنی بر پردازش ابری (cloud-based applications)،
موتورهای جستجو، و یا حتی کامپایلرهای برخی از زبانهای برنامهنویسی
جدید، برای ساختن همه آنها معمولاً از C++ استفاده میشود.
هنگامی که
برنامه Notepad
و یا vi[1] را روی کامپیوتر خود
اجرا میکنید، در واقع شما به پردازنده میگویید که برنامه اجرایی (executable) مربوط به آنها را
اجرا کند. برنامه اجرایی شکل نهایی یک محصول نرمافزاری است که میتواند روی کامپیوتر اجرا شود، و هدف برنامهنویس
هم ایجاد چنین برنامههایی است.
اولین
مرحله از ساخت یک برنامه اجرایی، که نهایتاً میتواند
روی سیستمعامل شما اجرا شود، نوشتن یک برنامه به C++ است. مراحل اصلی ایجاد یک برنامه به C++
بصورت زیر میباشند:
1- کُد نویسی (یا برنامهنویسی) کُدهای C++
با استفاده از یک ویرایشگر متن.
2- کامپایل (ترجمه) کردن کدهای نوشته شده با استفاده از یک کامپایلر (compiler) C++،
که کد مربوطه را به زبان ماشین ترجمه کرده و آن را بصورت یک آبجکت فایل (object file)، یا فایل مقصود،
تحویل میدهد.
3- لینک کردن یا پیوند دادن (linking) فایل خروجی کامپایلر با استفاده از یک لینکر (linker)
و بدست آوردن یک فایل اجرایی (مثلاً یک فایل با پسوند .exe در ویندوز).
توجه
داشته باشید که پردازشگر کامپیوتر نمیتواند فایلهای متنی، یا بعبارتی برنامههای نوشته شده شما، را پردازش کند. کامپایل کردن مرحلهای
است که کدهای C++،
که معمولاً در یک فایل با پسوند .cpp ذخیره شدهاند، به بایت کدهایی (byte codes) تبدیل میشوند که
نهایتاً پردازشگر میتواند آنها را درک کند. کامپایلر هر باری که یک فایل متنی .cpp
را پردازش میکند، یک آبجکت فایل (که
فایلی با پسوند .obj ، یا .o ، و یا .a است) به شما تحویل می دهد. نوع پسوند بستگی به کامپایلری دارد که شما از
آن استفاده میکنید، ولی در ویندوز معمولاً .obj
است. کار دیگری که کامپایلر انجام میدهد نشان دادن وابستگیهایی (dependencies) است که فایل شما
ممکن است با دیگر فایلها داشته باشد. وظیفه لینکر پیوند دادن آبجکت فایلها
به یکدیگر و برطرف کردن وابستگیها است. لینکر، علاوه بر بهم چسباندن آبجک
فایلهای مختلف به یکدیگر، هرگونه وابستگی برطرف نشده را نیز نشان میدهد و درصورتیکه هیچ مشکلی در بهم پیوستن آبجکت فایلها
نبود، یک فایل قابل اجرا به برنامهنویس میدهد که وی میتواند
آن را اجرا کند، و یا نهایتاً آنرا در اختیار کاربران دیگر قرار دهد.
بیشتر
برنامههای پیچیده، خصوصاً آنهایی که بوسیله گروهی از
برنامه نویسان نوشته میشود، بهندرت در همان آغازِ کار درست
کامپایل میشوند و خوب کار می کنند. یک برنامه بزرگ و پیچیده به
هر زبانی که نوشته شود (که C++ هم شامل آن هست)،
اغلب باید بارها و بارها اجرا شود تا مشکلات آن تحلیل و اشکالات آن آشکار شود. هر
بار قسمتی از اشکالات برنامه برطرف میشود و برنامه از نوع ساخته میشود و این
روند ادامه مییابد. بنابراین، درکنار سه مرحله اصلی توسعه
نرمافزار، یعنی: نوشتن برنامه، کامپایل کردن، و لینک
کردن، مرحله دیگری هم وجود دارد که به آن اشکالزدایی (debugging) میگویند، و در طی
آن برنامهنویس با استفاده از دیدهبانها (watches) و دیگر ابزارهای
مربوط به اشکالزدایی، مثل اجرای خط به خط برنامه، ناهنجاریها
و خطاهای برنامه را تحلیل و مشخص میکند.
بسیاری از برنامهنویسان
ترجیح میدهند تا از محیط
یکپارچه توسعه نرمافزار یا IDE
(Integrated
Development Environments) استفاده کنند، که در آن
مراحل مختلف تولید برنامه، از برنامهنویسی گرفته، تا کامپایل کردن، و لینک کردن
بصورت یکپارچه
در درون محیط دوستانهای انجام میشود که قابلیت اشکالزدایی نیز دارد و میتوان
برای پیدا کردن خطاها و برطرف کردن آنها از آن استفاده کرد.
کامپایلرهای زیادی برای C++ موجودند
که هم مجانی هستند و هم شامل IDE میباشند. محبوبترین آنها، نسخه Express
ویژوآل C++ مایکروسافت برای ویندوز، و کامپایلر GNU
C++ برای لینوکس
است، که g++ نامیده میشود. اگر
برنامههای خود را روی لینوکس مینویسید،
شما میتوانید نسخه مجانی Eclipse IDE را روی کامپیوتر خود نصب کنید و از g++
استفاده کنید.
اگر چه در زمان نوشتن این کتاب هنوز هیچ
کامپایلری وجود ندارد که بتواند از کلیه ویژگیهای C++11 پشتیبانی کند، بسیازی از
خصوصیات مهم این استاندارد توسط کامپایلرهای یاد شده پشتیبانی می شوند.
اینکارها
را انجام دهید
• از یک ویرایشگر متنِ ساده مثل notepad و یا gedit (در لینوکس) استفاده کنید، و یا متن برنامههای خود را با استفاده از یک IDE ایجاد کنید.
• فایلهای خود را با پسوند .cpp ذخیره کنید.
اینکارها
را انجام ندهید
• از متن پردازهایی مانند word یا wordpad برای ایجاد برنامههای خود استفاده نکنید، زیرا آنها علاوه بر متنی که شما وارد کردهاید، الگوهای نمایش متن را نیز در فایل ذخیره میکنند.
• از ذخیره کردن فایل خود با پسوند .c خودداری کنید، زیرا بسیاری از کامپایلرها چنین فایلهایی را بعنوان برنامههای c میبینند.
اکنون که
شما با ابزارها و مراحل مربوطه برای ایجاد یک برنامه آشنا شدید، وقت آن است که
اولین برنامه خود را به C++ بنویسید، که طبق سنت شامل
برنامه Hello World
خواهد بود و پیام ” Hello World!“ را روی صفحه شما چاپ
خواهد کرد.
اگر شما
با ویندوز کار میکنید و از ویژوآل C++
استفاده می کنید، میتوانید مراحل زیر را دنبال کنید:
1- از طریق منوی فایل، یک پروژه جدید ایجاد
کنید. (به File،
سپس به New بروید، و بعد Project را انتخاب کنید.
2- نوع برنامه (یا Application)
را Win32 Console انتخاب کنید و گزینه “Use Precompiled Header” را پاک کنید.
3- نام پروژه خود را Hello بگذارید و آنچه را که برنامه
بصورت خودکار برای شما ایجاد کرده با متنی که در لیست 1.1 آمده جایگزین کنید.
درصورتیکه
روی لینوکس برنامهنویسی میکنید،
برای ایجاد فایلهای cpp از یک ویرایشگر ساده متن (مثل gedit) استفاده کنید و آنچه در لیست
1.1 آمده در آن وارد کنید.
لیست 1.1 برنامه Hello.cpp
1: #include
<iostream>
2:
3: int main()
4: {
5: std::cout << "Hello World! " << std::endl;
6: return 0;
7: }
تنها کاری
که این برنامه کوچک انجام می دهد این است که با استفاده از std::cout
یک خط را بر روی صفحه نمایش شما چاپ
میکند. std::endl به cout فرمان میدهد که خط را تمام کند، و برنامه کار خود
را با بازگرداندن مقدار 0 به سیستمعامل به پایان میبرد.
اگر متن برنامهای را پیش خود میخوانید،
درست خواندن آن ممکن است به شما در یادگیری صحیح کلمات و کلیدواژهها کمک کند.
برای نمونه، بسته به اینکه در کدام کشور
زندگی میکنید،
شما میتوانید
#include را بصورت هاش-اینکلود، شارپ-اینکلود، و یا پاند-اینکلود تلفظ کنید.
به همین نحو شما میتوانید std::cout
را بصورت استاندارد-سی-آوت بخوانید.
بخاطر
داشته باشید که همیشه شیطان پشت جزئیات پنهان شده، یعنی شما باید کدهای خود را
دقیقاً به همان صورتی که در لیست آمده و با جزئیات کامل وارد کنید. کامپایلرها
بسیار ایرادگیر هستند و انتظار دارند کدهای وارد شده دقیقاً مطابق با دستور زبان
مورد نظر باشند و از آن عدول نشود. برای مثال، اگر شما سهواً بجای یک ; یک : را
وارد کنید، همه چیز به هم خواهد ریخت.
اگر از
ویژوال C++ استفاده میکنید، برای اجرای مستقیم برنامه خود در IDE دکمه Ctrl+F5 را فشار دهید. با اینکار
برنامه کامپایل، لینک، و اجرا خواهد شد. البته شما میتوانید هر یک از این مراحل
را بصورت جداگانه نیز انجام دهید:
1- روی مورد project راست-کلیک کنید و مورد Build انتخاب کنید تا
فایل اجرایی برای شما ساخته شود.
2- با استفاده از خط فرمان به فولدری بروید که
فایل اجرایی در آن ذخیره شده (معمولاً این فولدر در دایرکتوری Debug پروژه اصلی قرار
دارد).
3- با وارد کردن نام برنامه در خط فرمان،
برنامه را اجرا کنید.
برنامه ساخته شده شما در ویژوال C++
بصورت شکل 1.1 خواهد بود.
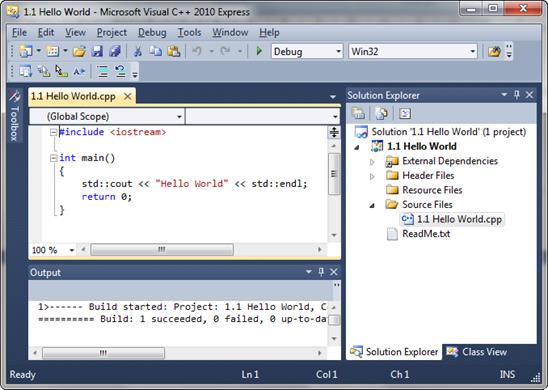
شکل 1.1 یک برنامه ساده “Hello World”
به زبان C++
که در ویژوال C++
نسخه 2010 ایجاد شده.
در
صورتیکه شما با لینوکس کار می کنید، کامپایلر g++ را توسط خط
فرمان احظار کنید.
g++ -o hello Hello.cpp
با وارد
کردن این خط، شما به g++
میگویید تا پس از کامپایل کردن فایل Hello.cpp، یک برنامه اجرایی با نام hello ایجاد کند. با اجرای .\hello روی لینوکس و یا hello.exe بر روی ویندوز،
پیام زیر بر روی صفحه نمایش شما ظاهر می شود:
Hello World!
تبریک میگویم! شما توانستید اولین گام را در یادگیری یکی از محبوبترین و قویترین
زبانهای برنامهنویسی جهان بردارید!
اهمیت استاندارد C++
ISO
همانگونه که میبینید، تطابق با استاندارد
موجب می شود تا برنامه کوچکی که در لیست 1.1 آمده بر روی بسیاری از بسترها و یا
سیستمعاملها قابل اجرا باشد. بنابراین اگر لازم بود تا شما برنامهای را بسازید که
هم بر روی ویندوز و هم بر روی لینوکس کار کند، پیروی از شیوههای برنامهنویسی
استاندارد (که در آن از بکارگیری عبارات منحصر به یک کامپایلر و یا یک بستر خاص
پرهیز میشود) راه کمخرجی را در دسترس شما قرار میدهد که میتواند بدون اینکه نیاز
باشد برای هر محیط برنامه جداگانهای بنویسید، برنامه شما استفاده کنندگان بیشتری
داشته باشد. البته چنین رویکردی وقتی بخوبی عمل میکند که برنامه شما نیازی نداشته
باشد تا تعاملات زیادی در سطح سیستمعامل داشته باشد (و در نتیجه به سیستم عامل
خاصی وابسته باشد).
کامپایلرها
بصورت دردناکی درمورد خطاها دقیق هستند، بااینحال کامپایلرهای خوب به شما خواهند گفت
که در کجا خطایی را مرتکب شدهاید. درصورتی که شما مشکلی در کامپایل کردن
برنامه لیست 1.1 داشته باشید، ممکن است کامپایلر خطایی شبیه زیر را از شما بگیرد (در اینجا
عمداً سمیکُلون خط پنجم پاک شده).
hello.cpp(6): error C2143:
syntax error:missing’;’before ‘return’
این پیامِ
خطا که مربوط به کامپایلر ویژوآل
C++
است، کاملاً گویاست. در اینجا نام فایلی که خطا در آن رخ داده، خطی که خطا در آن
رخ داده (در اینجا 6)، و توضیحی در مورد خود خطا، و کد مربوط به آن (در اینجا C2143) به شما داده میشود. گرچه در مثال فوق سمیکلون از خط پنجم حذف شده بود، خطای گذارش
شده خط ششم را نشان میدهد، و دلیل آن هم این است که کامپایلر تنها
پس از اینکه به عبارت return برخورد کند متوجه میشود که عبارت قبل از آن باید خاتمه یافته باشد. شما میتوانید
در ابتدای خط ششم یک سمیکلون اضافه کنید و خواهید دید که برنامه
بخوبی کامپایل میشود.
آنگونه که در زبانهای مثل Basic
معمول است، پایان یک خط باعث نمیشوند تا عبارات روی خط نیز تمام شده بحساب آید.
در C یا C++ این امکان هست تا یک عبارات
در چند خط نوشته شود.
درصورتی
که شما یک برنامهنویس باتجربه C++ باشید، ممکن است متوجه شده باشید که اصول برنامهنویسی C++ که در لیست 1.1 آمد، نسبت به قبل کوچکترین تغییری نکرده است. گرچه این
درست است که C++11 با نسخههای
قبلی C++ سازگاری دارد، ولی تلاشهای زیادی انجام گرفته تا استفاده از این زبان و برنامهنویسی با آن سادهتر شود.
ویژگیهایی نظیر auto به شما این امکان را میدهد که متغیرهایی را تعریف کنید که نوع آنها بصورت
خودکار توسط کامپایلر تعیین
میگردد، و یا با استفاده از ”توابع لاندا“ (Lambda
functions) توابع بینامی را تعریف کنید که از طول تکرار کنندههای
طویل بکاهد. این ویژگیها به شما اجازه میدهد
تا اشیاِ تابعی (function objects) جمع و جوری بنویسید
که بصورت قابل ملاحظهای از تعداد خطوط برنامه خواهند کاست. C++11
به برنامهنویسان قابلیت نوشتن برنامههایی
قابلحمل (portable)
و چندریسمانه (multithreaded)
را میدهد. این برنامهها هنگامی
که بدرستی ساخته شوند، میتوانند از الگوی اجرای
همزمان (concurrent execution)
پشتیبانی کنند، و بهمین دلیل هنگامی که کاربر قدرت سختافزاری
کامپیوتر خود را با افزودن تعداد هستههای CPU زیاد کند، به همان میزان نیز بر کارایی این برنامهها
افزوده خواهد شد.
بهبودیهای
زیادی در C++11
بعمل آمده که بتدریج در طول این کتاب به آنها اشاره خواهد شد.
در این
درس شما یادگرفتید که چگونه یک برنامه را وارد، کامپایل، لینک، و سپس اجرا کنید.
همچنین در این درس مروری کلی بر تکامل C++ بعمل آمد. همچنین
تاثیر پیروی از استاندارد نشان داد شد و اینکه چگونه میتوان یک برنامه بخصوص را
با استفاده از کامپایلرهای مختلف و در سیستمعاملهای گوناگون کامپایل کرد و برای هر یک از آنها برنامه یکسانی را تولید کرد.
س: آیا من
میتوانم پیامهای هشداردهندهای که
از کامپایلر داده
میشود را نادیده بگیرم؟
ج: در حالتهای خاصی کامپایلر پیامهای
هشداردهندهای (warning messages) از خود بیرون میدهد. هشدارها از این جهت با خطاها فرق دارند که خط از نظر دستوری صحیح است و
میتواند ترجمه شود. اما احتمال این وجود دارد که بتوان
به نحو بهتری آنرا نوشت، و کامپایلرهای خوب به شما توصیههایی
نیز برای اصلاح این خط ارائه میکنند.
این
اصلاحات پیشنهادی میتواند دربردارند روش ایمنتری برای برنامهنویسی باشد، و یا شاید توصیهای باشد تا برنامه شما بتواند با حروف و
نمادهای غیر-لاتین هم کار کند. در کل شما باید به این هشدارها توجه کنید و مطابق
با آنها برنامه خود را بهبود دهید. کامپایلر خود را طوری تنظیم نکنید که این هشدارها را
نمایش ندهد. فقط درصورتی اینکار را انجام دهید که از بیضرر
بودن آنها کاملاً مطمئن هستید.
س: زبانی
که از طریق مفسر ترجمه میشود با زبانی که از طریق کامپایلر ترجمه میشود چه تفاوتی دارد؟
ج: زبانهای مثل ”Windows Script“ حالت تفسیری (interpreted) دارند. در این نوع
زبانها مرحله کامپایل در کار نیست. یک زبان تفسیری از یک مُفسر استفاده میکند که مستقیماً کد برنام را میخواند و عملیات مورد نظر را انجام میدهد. در نتیجه، برای اینکه کد این نوع زبانها
اجرا شود شما باید مفسر آنها را روی کامپیوتر خود نصب کنید. به همین جهت، برآیند
اجرا کد این نوع زبانها پایین است، زیرا خودِ برنامه مفسر بعنوان یک برنامه درحال
اجرا، زمانی از وقت CPU
را به خودش اختصاص میدهد. ولی اینمورد برای زبانهایی مانند C++
که کامپایل میشوند مطرح نیست، زیرا دستورات این نوع
زبانها در زمان کامپایل، و قبل از اجرا ، به زبان ماشین ترجمه شدهاند.
س:
”خطاهای هنگاماجرا“ چیست و چه تفاوتی با ”خطاهای هنگام
کامپایل“ دارند؟
ج: هنگامی که شما برنامه خود را اجرا میکنید و در آن خطایی بروز میکند به آن خطا، خطای هنگاماجرا (runtime errors) میگویند. شما
ممکن است به خطای معروف “Access Violation”
در نسخههای قدیمی ویندوز برخورد کرده باشید، این نمونهای از یک خطای هنگاماجرا است. خطاهای
هنگام کامپایل (Compile-time errors)،
نشاندهنده اشتباهی در برنامهنویسی
هستند و برای کاربرِ نهایی برنامه نمایش داده نمیشوند؛
این خطاها باید تصحیح شوند، وگرنه اصلاً برنامهای
ساخته نمیشود که بتوان آنرا اجرا کرد.
در بخش
کارگاه سئوالات امتحانی مطرح میشود که پاسخ گویی به آنها به شما کمک میکند تا درک خود را نسبت به مواردی که در درسها مورد بحث قرار گرفت افزایش
دهید، تمرینها نیز برای شما شرایطی را فراهم میکند که آنچه را
یادگرفتهاید آزمایش کنید. قبل از اینکه برای یافتن جواب صحیح
به ضمیمه D این کتاب مراجعه
کنید، سعی کنید خودتان به سئوالات و تمرینها پاسخ دهید.
1- تفاوت یک مفسر و یک کامپایلر چیست؟
2- لینکر (پیوند دهنده) چه کاری انجام میدهد؟
3- مراحل مختلف در چرخه تولید یک برنامه معمولی
چیستند؟
4- چگونه استاندارد C++11
توانسته از پردازندههای چندهستهای بهتر پشتیبانی کند؟
تمرینها
1- به برنامه زیر نگاه کنید و بدون اینکه آنرا
اجرا کنید سعی کنید حدس بزنید چه کاری را انجام میدهد:
1: #include
<iostream>
2: int main()
3: {
4: int
x = 8;
5: int y = 6;
6: std::cout << std::endl;
7: std::cout << x - y << " " << x * y << x + y;
8: std::cout << std::endl;
9: return 0;
10:}
2- برنامهای که در تمرین 1 آمده است را وارد کرده و سپس آنرا کامپایل و لینک کنید. این برنامه چه کاری انجام میدهد؟ آیا همان کاری را انجام میدهد که شما حدس زده بودید؟
3- فکر
میکنید اشکال برنامه زیر چیست؟
1: include
<iostream>
2: int main()
3: {
4:
std::cout << "Hello Buggy World \n";
5: return 0;
6: }
4- خطای موجود در برنامه تمرین 3 را برطرف کرده و آنرا کامپایل، لینک، و سپس اجرا کنید. این برنامه چه کاری انجام میدهد؟
برنامههای
C++
شامل کلاسها، توابع، متغیرها، و اجزاء دیگری میباشند. بیشتر این کتاب به توضیح این
اجزاء میپردازد، اما به منظور اینکه درک بهتری از چگونگی جور شدن این اجزاء با
یکدیگر داشته باشید، شما نیاز دارید تا با یک برنامه کامل روبرو شوید.
در این
درس شما یاد خواهید گرفت که:
§
اجزاء یک برنامه C++
§
چگونه این اجزاء با هم کار میکنند
§
تابع چیست و چه کاری انجام میدهد
§
عملیات اصلی ورودی و خروجی چه
هستند
اولین برنامه که شما در درس 1 نوشتید کاری بیش از
چاپ پیام “Hello World” روی صفحه نمایش نمیکرد.
بااینحال این برنامه حاوی برخی از مهمترین و اساسیترین اجزایی است که یک برنامه C++
در خود دارد. شما از لیست 2.1 استفاده میکنید تا کلیه اجزایی که یک برنامه C++
در بر دارد را تجزیه کنید.
لیست 2.1 برنامه HelloWorldAnalysis.cpp: تشریح یک برنامه C++
1: //را در برنامه شامل میکند iostream فایل سرآمدی که فایل
2: #include
<iostream>
3:
4: //شروع میشوند main() همیشه برنامههای شما با
5: int main()
6: {
7: /* نوشتن روی صفحه */
8: std::cout << “Hello World” << std::endl;
9:
10: // بازگرداندن یک مقدار به سیستم عامل
11: return 0;
12: }
تحلیل برنامه▼
این برنامه C++ میتواند بصورت کلی
به دو بخش تقسیم شود: 1- دستورات پیشپردازنده[2] (preprocessor
directives) که با علامت # شروع میشوند،
2- بدنه اصلی برنامه که با int main() شروع میشود.
خطوط 1، 4، 7، و 10 که با // و یا /* شروع
شدهاند توضیحات هستند و کامپایلر آنها را نادیده میگیرد. این توضیحات تنها برای
خواندن انسان هستند.
توضیحات بصورت مفصلتری در بخش بعدی مورد
بررسی قرار میگیرند.
همانطور که
از نام آن معلوم است، پیشپردازنده ابزاری است که پیش از اینکه عمل کامپایل اصلی
صورت گیرد اجرا میشود. دستورات پیشپردازنده، دستوراتی برای پیشپردازش هستند که
همیشه با علامت # شروع میشوند. در خط 2 لیست 2.1، دستور #include
<filename> به پیشپردازنده دستور میدهد که محتوای
فایل خاصی را بگیرد (در اینجا این فایل iostream است) و آنرا از همان خطی که پیشپردازنده روی آن قرار
دارد به داخل متن برنامه تزریق کند. فایل iostream حاوی تعریف std::cout است که در خط 8 عبارت ”Hello World“ را چاپ میکند، این فایل یک فایل سرآیند (header file) استاندارد است که در
برنامه وارد میشود. به عبارت دیگر، دلیل اینکه کامپایلر میتواند خط 8 را که حاوی عبارت std::cout بفهمد این است که ما
قبلاً در خط دوم به پیشپردازنده دستور دادهایم که فایلی که حاوی تعریف std::cout است را به برنامه وارد
کند.
در یک برنامه C++ که بصورت حرفهای نوشته شده
باشد، تمام فایلهای سرآیند، جزء فایلهای سرآیند استاندارد نیستند. برنامههای
پیچیده معمولاً طوری نوشته میشوند که حاوی فایلهای سرآیند متعددی هستند و برخی
از آنها نیاز دارند تا فایلهای دیگری را در داخل خود بگنجانند. پس اگر چیزی در
فایلی بنام A تعریف شده باشد و نیاز باشد
تا از آن در فایلی مثل B استفاده کرد، شما باید فایل A را در فایل B شامل
کنید. معمولاً اینکار را با نوشتن عبارتی در اول فایل B بصورت زیر انجام میدهید.
#include ”Aمسیر فایل \A”
ما در اینجا بجای < > از دابل کوتیشن استفاده کردهایم تا مسیر کامل فایلی را که باید گنجانده شود مشخص کنیم. معمولاً از < > هنگامی استفاده میشوند که بخواهند یکی از فایلهای سرآیند استاندارد را در داخل برنامه بگنجانند.
بدنبال
دستورات پیشپردازش، بدنه اصلی برنامه قرار میگیرد که مشخصه آن تابع main() است. اجرای دیگر یک
برنامه C++ همیشه از همین تابع شروع میشود. این بصورت یک عرف قراردادی درآمده که
تابع main()
با یک int شروع میشود که پیش
از آن میآید. int نشان دهنده گونه (type)
مقدار بازگردانده شده توسط تابع main() است.
در بسیاری از برنامه C++ شما تعریف دیگری را هم برای
تابع main() میبینید که شبیه زیر است:
int main (int argc, char* argv[])
این تعریف نیز مطابق با استاندارد است، زیرا در اینجا هم مقدار بازگردانده شده برای main یک int است. چیزی که مابین پرانتزها قرار گرفته ”پارامترهایی“ است که به تابع داده میشود. چنین روشی به کاربر اجازه میدهد که در خط فرمان، به دنبال نام فایل اجرایی، پارامترهایی را نیز به آن اضافه کند و مثلاً بنویسد:
program.exe /DoSomethingSpecific
/DoSomethingSpecific پارامتری است که توسط سیستم
عامل به برنامه داده میشود، و در تابع main به
آن رسیدگی میشود.
اجازه
دهید تا به خط 8 بپردازیم که وظیفه اصلی این برنامه را انجام میدهد!
std::cout << “Hello World” << std::endl;
cout (یا کُنسول آوت، به معنی خروجی کنسول[3]) عبارتی است که پیام ”Hello World“ را روی صفحه چاپ میکند. cout یک جریان (stream)
است که در یک فضای اسمی (namespace)، که در اینجا std::cout است، تعریف شده و کاری که شما در این خط انجام میدهید
این است که پیام ”Hello World“
را با استفاده از عملگر درجِ جریان (stream
insertion operator)، که علامت آن << است، به جریان وارد میکنید. std::endl
به این منظور بکار میرود که خط را خاتمه دهد و درج آن در جریان مثل بازگشت به
ابتدای سطر است. توجه داشته باشید هر بار که بخواهید چیز جدیدی را در جریان درج یا
وارد کنید، باید از عملگر درج جریان (<<)
استفاده کنید.
چیز خوبی
که در مورد جریانها وجود دارد این است که کار با جریانهای مختلف شباهت زیادی با
یکدیگر دارد، و مثلاً میتوان بجای درج متن در یک جریانِ کنسولی آنرا در یک جریانِ
فایلی وارد کرد. بنابراین کار با جریانها روشن است، و هنگامی که شما به یکی از
آنها خو گرفتید (مثلاً cout
که متنی را در کنسول مینویسد) برای شما ساده خواهد بود تا با انواع دیگر جریانها،
مثل fstream که برای نوشتن متن در
فایلها بکار میرود، کار کنید.
جریانها
با جزئیات بیشتری در درس 27 با عنوان ”استفاده از جریانها برای عملیات ورودی و
خروجی“ مورد بررسی قرار خواهند گرفت.
به متن ”Hello World“، به همراه دابل کوتیشنهای
آن، یک ثابت لفظی رشتهای (literal string) میگویند.
در C++ توابع باید مقداری را بازگردانند، مگر اینکه صریحاً طور دیگری قید شده
باشد[4].
main()
نیز تابعی است که همیشه یک عدد صحیح
را باز میگرداند. این مقدار به سیستمعامل بازگردانده خواهد شد. بسته به ماهیت
برنامه، این مقدار میتواند اطلاعات مفیدی درباره نتیجه برنامه به سیستمعامل بدهد.
در بسیاری از اوقات یک برنامه توسط برنامه دیگری راهاندازی میشود و برنامه والد
(همان که برنامه را راهاندازی کرده) میخواهد بداند که برنامه فرزند (همان که راهاندازی
شده) آیا کار خود را بطور کامل و با موفقیت انجام داده یا نه. برنامهنویس میتواند
از مقدار بازگردانده توسط تابع main()
استفاده کرده و موفقیت و یا خطای پیش آمده را به برنامه والد گذارش کند.
مطابق با عرف، برنامهنویس باید درصورت
موفقیت برنامه مقدار 0، و درصورت بروز خطا مقدار -1 را بازگرداند. ولی بدلیل اینکه
مقدار بازگردانده شده یک عدد صحیح است، برنامهنویس این انتخاب را دارد که از
دامنه وسیع این اعداد استفاده کرده و برای هر یک از حالتهای مختلفی که برنامه با
آن روبرو میشود مقادیر دیگری را بازگرداند.
C++ زبانی است که نسبت به حروف کوچک و بزرگ حساس است. بنابراین اگر مثلاً بجای اینکه int را تایپ کنید، Int را تایپ کردید، یا بجای void تایپ کردید Void، باید انتظار داشته باشید تا
کامپایلر از شما خطا بگیرید.
دلیل
اینکه شما بجای اینکه فقط تایپ کنید cout،
تایپ میکنید std::cout،
این است که تعریف آن cout که شما به آن اشاره میکنید در یک فضای
اسمی (namespace)
قرار دارد، و نام این فضای اسمی std
است.
ولی این
فضاهای اسمی چه هستند؟
فرض کنید
که شما از توصیفکننده (qualifier) فضای اسمی برای فراخوانی cout استفاده نمیکردید، و نیز فرض
کنید که در دو جا از برنامه شما هم دو cout وجود دارد (مثلاً در دو فایل مختلف با تعاریفی مختلف).
اگر شما cout را فراخوانی کنید،
کامپایلر از
کجا بداند که منظور شما کدام cout است؟ این باعث ناسازگاری میشود و عملیات کامپایل با شکست مواجه خواهد شد.
در اینجا است که فضاهای اسمی بکار میآیند. فضاهای اسمی نامهایی (اسامی) هستند که
به قسمتهای مختلف برنامه داده میشود و از ناسازگاریهای بلقوهای که بین اسامی
مشابه وجود داد جلوگیری میکند. با فراخوانی std::cout، شما به کامپایلر میگویید که
منظورتان آن cout
است که در فضای اسمی std
تعریف شده.
شما وقتی فضای اسمی std (بخوانید استاندارد) را بکار
میبرید که بخواهید از توابع، جریانها، و تسهیلاتی استفاده کنید که توسط کمیته
استاندارد ISO تایید شده، و در نتیجه در این فضای اسمی قرار گرفتهاند.
خیلی از برنامهنویسان وقتی میخواهند از cout، و یا دیگر ویژگیهایی که در
فضای اسمی استاندارد
وجود دارد استفاده کنند، از اینکه بطور دائم باید حتماً std را تایپ کنند نارحت هستند.
استفاده از دستور using که فضای اسمی را تعیین میکند، میتواند کار را برای این
دسته از برنامهنویسان آسانتر کند. در لیست 2.2 شما طریقه کاربرد using
برای پرهیز از تکرار std
را میبینید:
لیست 2.2 استفاده از using برای اعلان فضای اسمی
1: // دستورات پیشپردازنده
2: #include
<iostream>
3:
4: // Start
of your program
5: int main()
6: {
7: // به کامپایلر میگویید از چه فضای اسمی استفاده کند
8: using namespace std;
9:
10: /*روی صفحه نمایش چیزی را چاپ میکنید std::cout با استفاده از*/
11: cout << “Hello World” << endl;
12:
13: //را به سیستم عامل باز میگردانید 0 مقدار
14: return 0;
15: }
تحلیل
برنامه▼
به خط 8
توجه کنید. در اینجا به کامپایلر گفته
میشود که شما در حال استفاده از فضای اسمی std هستید. در اینجا دیگر نیازی نیست که در
خط 11 بطور صریح بنویسد std::cout
یا std::endl.
نوع
مقیدتر برنامه فوق در لیست 2.3 نشان داده شده که در آن شما بصورت کامل نام فضای
اسمی را
نیاوردهاید. در اینجا شما تنها به آن چیزهایی اشاره کردهاید که میخواهید در
برنامه خود از آنها استفاده کنید.
لیست 2.3 استفاده دیگری از کلیدواژه using
1: // دستورات پیشپردازنده
2: #include
<iostream>
3:
4: // Start
of your program
5: int main()
6: {
7: using std::cout;
8: using std::endl;
9:
10: /*روی صفحه نمایش چیزی را چاپ میکنید std::cout با استفاده از */
11: cout << “Hello World” << endl;
12:
13: ////را به سیستم عامل باز میگردانید 0 مقدار
14: return 0;
15: }
تحلیل
برنامه▼
حالا خط 8 لیست 2.2 با خطوط 7 و 8 لیست 2.3 جایگزین شده. تفاوت بین ”using namespace std“ و ”using std::cout“ در این است که اولی اجازه میدهد، بدون اینکه نیازی باشد تا std:: را نوشت، از کلیه چیزهایی که در فضای اسمی std قرار دارند استفاده کرد، ولی در دومی چیزهای که میتوان بدون نوشتن std:: از آنها استفاده کرد فقط cout و endl است.
خطوط 1،
4، 10، و 13 لیست 2.3 حاوی متنهایی است که به یک زبان انسانی (در اینجا فارسی)
نوشته شده و این متنها هیچگونه مداخلهای در روند کامپایل برنامه نمیکنند. آنها
همچنین هیچ تاثیری در خروجی برنامه ندارند. چنین خطوطی توضیحات (comments) نامیده میشوند.
توضیحات ازنظر کامپایلر نادیده
گرفته میشوند و بطور گستردهای توسط برنامهنویسان برای تشریح برنامههای آنها بکار
میرود. چون این توضیحات باید توسط انسانها فهمیده شود و نه ماشین، آنها به زبان
انسانی نوشته میشوند[5].
§
برای مثال، خط زیر نشاندهنده
یک توضیح است
// This is a comment
§
عباراتی که مابین /*
*/قرار گیرند نیز جزء توضیحات حساب میشوند، حتی اگر چند خط را اشغال
کنند، مثل عبارت زیر:
/* این یک توضیح است
که
بر روی دو خط نوشته شده */
ممکن است عجیب بنظر برسد که یک برنامهنویس نیاز داشته باشد تا درباره برنامهای که خودش نوشته توضیح بدهد. ولی مشکلات هنگامی خود را نشان میدهند که برنامهها بزرگتر و بزرگتر شوند و یا بیش از یک نفر در نوشتن آنها دخیل باشد. در چنین مواقعی، چیزی که مهم است نوشتن برنامههایی است که به آسانی درک شوند. مهم است که با نوشتن توضیحاتی خوب، نشان داده شود که چه کاری در حال انجام است و چرا به این شکل انجام میشود.
اینکارها را انجام دهید
• همیشه برای تشریح کارکرد الگوریتمهای پیچیده و قسمتهای دشوار توضیحاتی را به متن برنامه اضافه کنید.
• توضیحات را به شکلی ارائه کنید که همکاران برنامهنویس شما بتوانند آنها را درک کنند.
اینکارها را انجام ندهید
• از توضیح چیزهایی که واضح و یا تکراری هستند پرهیز کنید.
• فراموش نکنید که اضافه کردن توضیات، نوشتن برنامههای مبهم را توجیح نمیکند.
• فراموش نکنید هنگامی که در برنامه تغییراتی پدید میآید ممکن است نیاز باشد تا توضیحات مربوطه نیز تغییر کنند.
توابع C++
نیز مانند توابع C
هستند. توابع چیزهای هستند که شما را قادر میکنند تا محتوای برنامه خود را به
واحدهای کوچکتری به نام تابع تقسیم کنید، و این توابع میتوانند به ترتیبی که مورد
نظر شماست فراخوانی شوند. هنگامی که یک تابع فراخوانده میشود، معمولاً به تابعی
که آنرا فراخوانده مقداری را باز میگرداند. معروفترین تابع درزبان C و C++
تابع main() است. کامپایلر میداند که این تابع نقطه شروع برنامه شما
است و مقداری را هم که بازمیگرداند یک int (یعنی عدد صحیح) است.
شما بعنوان یک برنامهنویس این انتخاب را دارید تا
توابع گوناگونی را برای کارهای مختلف خود بسازید. لیست 2.4 یک برنامه ساده را نشان
می دهد که از تابع برای نمایش یک عبارت بر روی صفحه استفاده میکند.
لیست 24.2 اعلان،
تعریف، و فراخوانی یک تابع که برخی از قابلیتهای std::cout را نشان میدهد.
1: #include
<iostream>
2: using
namespace std;
3:
4: // اعلان تابع
5: int DemoConsoleOutput();
6:
7: int main()
8: {
9: // فراخوانی یا احضار تابع
10: DemoConsoleOutput();
11:
12: return 0;
13: }
14:
15: // تعریف تابع
16: int DemoConsoleOutput()
17: {
18: cout << “This is a simple string literal” << endl;
19: cout << “Writing number five: “ << 5 << endl;
20: cout << “Performing division 10/5 = “ << 10 / 5 << endl;
21: cout << “Pi when approximated is 22/7 = “<< 22/7 << endl;
22: cout << “Pi more accurately is 22/7=“ <<22.0 / 7 << endl;
23:
24: return 0;
25: }
خروجی
برنامه▼
This is a simple string literal
Writing number five: 5
Performing division 10 / 5 = 2
Pi when approximated is 22 / 7 = 3
Pi more accurately is 22 / 7 = 3.14286
تحلیل
برنامه▼
چیزی که
برای ما جالب است خطوط 5، 10، و 15 تا 25 برنامه است. خط 5، اعلان تابع (function declaration) نامیده میشود.
اساساً این خط به کامپایلر میگوید
که شما بعداً تابعی به نام DemoConsoleOutput را ایجاد خواهید کرد و این تابع یک int (عدد صحیح) را
بازخواهد گرداند. بخاطر وجود همین خط است که کامپایلر ایرادی به خط 10 نمیگیرد و
آن را کامپایل میکند. کامپایلر فرض میکند تعریف این تابع بعداً خواهد آمد. این
تعریف در خطوط 15 تا 25 برنامه آمده است.
در واقع
کاری که این تابع انجام میدهد نمایش قابلیتهای مختلف cout است. در اینجا
نه فقط مانند موارد قبلی پیام ”Hello World“ نمایش داده میشود، بلکه نتیجه محاسبات ساده عددی نیز
نمایش داده شده. خط 21 و 22 هر دو سعی میکنند که عدد پی را که به (7/22 ) نزدیک است نمایش دهند، ولی دومی این عدد را با دقت بیشتری نمایش میدهد زیرا
با تقسیم 22.0 بر عدد 7 شما به کامپایلر میگویید که حاصل را بعنوان یک عدد حقیقی
تعبیر کند (به زبان C++ به این نوع اعداد float
میگویند) و نه یک عدد صحیح.
توجه کنید
که تابع شما یک عدد صحیح را بازمیگرداند (عدد 0). بدلیل اینکه دراین
تابع شرایط دیگری وجود ندارد، نیازی هم نخواهد بود تا مقدار دیگری بازگردانده شود.
به همین شکل، تابع main
هم مقدار 0 را بازمیگرداند. حال که تابع main کلیه وظایف خود را به گردن
تابع DemoConsoleOutput
انداخته، همانگونه که در لیست 2.5 نشان داده شده بهتر است شما هم از مقدار
بازگردانده شده از این تابع برای آن چیزی که تابع main باز میگرداند استفاده کنید.
لیست 2.5 استفاده
از مقدار بازگشتی یک
تابع
1: #include
<iostream>
2: using
namespace std;
3:
4: // اعلان و تعریف یک تابع
5: int DemoConsoleOutput()
6: {
7: cout << “This is a simple string literal” << endl;
8: cout << “Writing number five: “ << 5 << endl;
9: cout << “Performing division 10/5 = “ << 10 / 5 << endl;
10: cout << “Pi when approximated is 22/7=“ << 22 / 7<< endl;
11: cout << “Pi more accurately is 22/7= “ << 22.0/7 << endl;
12:
13: return 0;
14: }
15:
16: int main()
17: {
18: // فراخوانی تابع و استفاده از مقدار بازگشتی آن
19: return DemoConsoleOutput();
20: }
تحلیل
برنامه▼
خروجی این
برنامه مانند برنامه قبلی است. بااینحال تغیرات مختصری در نحوه نوشتن آن بوجود
آمده. یکی این است که شما تابع فراخوانده شده را در خط 5، و قبل از تابع main، تعریف کردهاید. از این نظر نیازی نبوده تا
وجود چنین تابعی را اعلان کنید. کامپایلرهای جدید C++
خط 5 را هم بعنوان اعلان تابع و
هم نقطه شروع تعریف آن قلمداد میکنند. در خط 19 تابع DemoConsoleOutput فراخوانی شده و در
همین حال از مقدار بازگشته از آن بعنوان مقدار بازگردانده شده تابع main
استفاده شده.
در حالتهای شبیه به این، که نیازی نیست از
روی نتیجه تابع تصمیمی گرفته شود، و یا تابع نیاز ندارد تا مقادیر مختلفی را برای
موفقیت و یا شکست خود بازگرداند، شما میتوانید به تابع بگویید که هیچ چیزی را باز
نگرداند. اینکار با قرار دادن void بعنوان گونه بازگردانده شده
تعریف میشود:
void DemoConsoleOutput()
این تابع نمیتواند مقداری را بازگرداند، و
اجرای توابعی که void را بازمیگرداند (در حقیقت
چیزی بازنمیگردانند) نمیتواند در تصمیم گیری بکار رود
توابع میتوانند پارامترهایی را داشته باشند، و یا دارای حالت بازگشتی (recursive) باشند، میتوانند حاوی چندین عبارت بازگشتی باشند، میتوانند سربارگذاری (overloaded) شوند، میتوانند توسط کامپایلر بصورت در-خط در تمام برنامه گسترده شود (expanded in-line)، و خیلی کارهای دیگر. این مفاهیم با جزئیات بیشتری در درس 7 با عنوان ”سازماندهی برنامه با توابع“ مورد بررسی قرار میگیرد.
شما میتوانید
با برنامهها به طرق مختلفی تعامل کنید و همچنین برنامهها نیز با شما به طرق
مختلفی تعامل میکنند. شما میتوانید با تمام برنامهها بوسیله کیبورد و یا ماوس
تعامل کنید. شما میتوانید اطلاعات را بشکل متون ساده، و یا گرافیکهای پیچیده، روی صفحه نمایش خود داشته باشید، و یا آنها
را بوسیله چاپگر روی کاغذ چاپ کنید، و یا خیلی ساده آنها را بصورت یک فایل برای
مصارف بعدی ذخیره کنید. در این قسمت روشهای ساده ورودی و خروجی با استفاده از
کنسول در C++
مورد بررسی قرار می گیرند.
شما از std::cout برای نوشتن یک داده
متنی بر روی کنسول استفاده میکنید، و همینطور برای خواندن متن و اعدادی که بوسیله
کیبورد به برنامه وارد میشوند نیز از std::cin (استاندارد سیاین) استفاده میکنید. در شما حقیقت قبلاً
هم برای نمایش عبارت ”Hello World“ بر روی صفحه از cout استفاده کردید. در خط 8 این
برنامه در لیست 2.1 آمده بود:
8: std::cout
<< “Hello World” << std::endl;
این عبارت نشان می دهد که به دنبال cout یک عملگر درج (>>) آمده، بدنبال آن ثابت رشتهای که باید روی
صفحه نمایش داده شود، یعنی ”Hello
World“، و نهایتاً خاتمه دهنده خط، یعنی std::endl، آمده است.
استفاده
از cin نیز ساده است. cin برای ورود و ذخیره اطلاعات بکار میرود. طریقه
کاربرد آن به این صورت است که باید نام متغییری را که میخواهید اطلاعات در آن
ذخیره شود را بدنبال عملگر اخذ (extraction operator)
بیاورید:
std::cin >> Variable;
دراینجا <<
نشاندهنده عملگر اخذ میباشد (یعنی اطلاعات را از جریان ورودی کنسول اخذ میکند)، و بدنبال آن نام
متغیری آمده که باید اطلاعات واردشده را در خود ذخیره کند. اگر نیاز باشد تا
کاربر دو چیز مختلف را وارد کند که بوسیله فاصله از هم جدا میشوند، شما میتوانید از عبارتی
مثل زیر استفاده کنید:
std::cin >> Variable1 >> Variable2;
توجه داشته باشید همانطور که در لیست 2.6 نشان داده
شده،
از cin هم برای ورود متن، و
هم برای ورود اعداد استفاده میشود.
لیست 2.6 استفاده از cin و cout برای نمایش عدد و متنی که کاربر وارد کرده
است.
1: #include
<iostream>
2: #include
<string>
3: using
namespace std;
4:
5: int main()
6: {
7: // اعلان متغیری که باید عددی که کاربر وارد میکند را در خود ذخیره کند
8: int InputNumber;
9:
10: cout << "Enter an integer: ";
11:
12: // گرفتن و ذخیره عدد وارد شده
13: cin >> InputNumber;
14:
15: // همان کار را برای دادههای رشتهای انجام بده
16: cout << "Enter your name: ";
17: string InputName;
18: cin >> InputName;
19:
20: cout << InputName << " entered " << InputNumber << endl;
21:
22: return 0;
23: }
خروجی
برنامه▼
Enter an integer: 2011
Enter your name: Siddhartha
Siddhartha entered 2011
تحلیل
برنامه▼
خط 8 نشان میدهد که چگونه متغییری بنام InputNumber برای ذخیره یک داده از نوع int تعریف شده. در خط 10 با استفاده از cout از کاربر خواسته میشود تا عددی را وارد کند، و در خط 13 عدد وارد شده بوسیله cin در یک متغیر از نوع int ذخیره میشود. همین کار دوباره تکرار میشود ولی اینبار بجای یک عدد، از کار بر خواسته میشود تا نام خود را وارد کند، که البته این نمیتواند در یک متغیر عددی ذخیره شود و همانگونه که در خطوط 17 و 18 دیده میشود برای اینکار نوع دیگری از متغیر نیاز است که string نامیده میشود. دلیل اینکه شما #include <string> را در خط دوم وارد کردهاید این است که بعداً بتوانید در داخل تابع main از گونه string استفاده کنید. بالاخره در خط 20 از یک عبارت cout استفاده شده تا نام و عددی را که من وارد کردم (Siddhartha entered 2011) چاپ کند.
این مثال
سادهای از اصول عملیات ورودی و خروجی در C++ است. اگر مفهوم متغیر
برای شما روشن نیست زیاد نگران نباشید، زیرا من بطور مفصلتر در درس 3 با عنوان
”استفاده از متغیرها و
اعلان ثابتها“ آنها را برایتان شرح خواهم داد.
این درس
شما را با بخشهای مختلف یک برنامه ساده C++ آشنا کرد. شما
فهمیدید که main()
چیست، با مقدمات فضاهای اسمی آشنا شدید، و اصول عملیات ورودی و خروجی کنسولی را
یاد گرفتید. حالا شما میتوانید بصورت گسترده در هر برنامهای که مینویسید از
آنها استفاده کنید.
س: #include
چه کاری را انجام میدهد؟
ج: یک دستور (یا یک هدایتگر) برای پیشپردازش
است که وقتی شما کامپایلر خود
را فراخوانی میکنید انجام میشود. این نوع بخصوص از هدایتگر موجب میشود تا
محتوای فایلی که نام آن در میان < > نوشته شده در همان خط تزریق شود، بصورتی که انگار از آن خط به بعد محتوای
فایل را خودتان تایپ کردهاید.
س: چه
تفاوتی میان توضیحاتی که با // نوشته میشود و توضیحاتی که با /*
*/ نوشته میشود وجود دارد؟
ج: توضیحاتی که با // شروع میشوند باید فقط تا
پایان خط ادامه یابند، به اینها توضیحات تک-خطی میگویند. توضیحاتی که بین /*
*/ قرار گرفتهاند میتوانند روی چندین خط قرار گیرند، به اینها
توضیحات چند-خطی میگویند. فراموش نکنید حتی انتهای تابع هم در توضیحاتی که با /*
شروع میشوند پایان توضیحات قلمداد نمیشود و شما باید حتماً آنرا با */
ببندید وگرنه کامپایلر از
شما خطا خواهد گرفت.
س: چه
مواقعی شما نیاز دارید تا از پارامترهای خط فرمان استفاده کنید؟
ج: در مواقعی که بخواهیم عملکرد برنامه توسط
کاربر تغییر کند. برای مثال دستور ls
در لینوکس و دستور dir
در ویندوز شما را قادر میکند تا محتوای دایرکتوری یا فولدر جاری را مشاهده کنید.
برای مشاهده فایلهایی که در فولدرهای دیگری هستند، شما باید مسیر آنها را توسط
پارامترهای خط فرمان به برنامه وارد کنید، مثلا وارد کنید:
ls /home
dir c:\mydir
در بخش کارگاه
سئوالات امتحانی مطرح میشود که پاسخ گویی به آنها به شما کمک میکند تا درک خود
نسبت به مواردی که در درسها مورد بحث قرار گرفته را افزایش دهید، تمرینها نیز
برای شما شرایطی را فراهم میکند که آنچه را یادگرفتهاید آزمایش کنید. قبل از
اینکه برای یافتن جواب صحیح به ضمیمه D
این کتاب مراجعه کنید، سعی کنید خودتان به سئوالات و تمرینها پاسخ دهید.
1- چه اشکالی دارد اگر ما تابع main را به اینصورت Int main() اعلان کنیم؟
2- آیا توضیحات میتوانند از یک خط بیشتر باشند؟
تمرینها
1- رفع اشکال برنامه
: برنامهای که در زیر آمد وارد کرده و آنرا کامپایل
کنید. چرا برنامه کامپایل نمیشود؟ چگونه میتوان اشکال آنرا برطرف کرد؟
1: #include
<iostream>
2: void main()
3: {
4:
std::Cout << Is there a bug here?”;
5: }
2- اشکال برنامه قبلی را برطرف کرده و آنرا کامپایل، لینک، و اجرا کنید.
3- برنامهای
که در لیست 2.4 آمده بود را طوری تغییر دهید که با استفاده از – عمل تفریق، و با استفاده از *
عمل ضرب را نمایش دهد.
متغیرها (Variables) ابزارهایی هستند که
به برنامهنویس کمک میکنند تا دادهها را بصورت موقت، و برای مدت معینی در حافظه
کامپیوتر ذخیره کند. ثابتها (Constants) ابزارهایی هستند که
به برنامهنویس کمک میکند چیزهای را تعریف کند که اجازه تغییر کردن ندارند.
در این
درس شما یاد میگیرید که:
§
چگونه از کلیدواژههای جدید C++11
یعنی auto
و constexpr استفاده کنید
§
چگونه متغیرها و ثابتها را اعلان و تعریف کنید
§
چگونه مقادیری را به متغیرها نسبت دهید و آن مقادیر را تغییر دهید
§
چگونه مقدار یک متغیر را روی
صفحه نمایش چاپ کنید
درواقع
پیش از اینکه شما به کاربرد متغیرها در
یک زبان برنامهنویسی بپردازید، بهتر است یک مرحله به عقب باز گردید و ابتدا
ببینید که چه اجزایی داخل کامپیوتر هستند و چگونه کار میکنند.
کلیه کامپیوترها،
از گوشیهای هوشمند گرفته تا سوپرکامپیوترهای بزرگ، دارای پردازنده (CPU)،
و مقدار معینی حافظه برای کارهای موقتی خود هستند که به آن [6]RAM میگویند. علاوه براین، دستگاههای دیگری مانند هارد دیسک نیز در برخی
کامپیوتر وجود دارند که اجازه میدهند تا دادهها بصورت بادوام (persistent) روی آنها ذخیره شود.
پردازنده برنامه شما را اجرا میکند، و در این راه با RAM کامپیوتر تماس دارد. تماس CPU و RAM برای دو منظور است، یکی برای
اینکه CPU برنامه را از RAM گرفته و به داخل خودش منتقل و
آنرا اجرا کند و دیگر اینکه دادههای وابسته به آن (مثلاً آنچه روی صفحه نمایش
داده، و یا توسط کاربر وارد میشود) را پردازش کند.
RAM
را میتوان شبیه کمدهای موجود در یک رختکن تصور کرد، که هر کمد برای خود یک شماره
دارد (که همان آدرسش است). برای دستیابی به یک مکان خاص از حافظه، مثلاً خانه
شماره 578، پردازنده نیاز دارد تا با دستوری که به آن داده میشود
آن مقدار را از آنجا خوانده و یا مقداری را در آن بنویسد.
مثال بعدی
به شما کمک خواهد کرد تا بفهمید متغیر چیست. فرض کنید شما میخواهید برنامهای
بنویسید که دو عدد را که کاربر وارد میکند در هم ضرب کند. از کاربر خواسته خواهد
شد که دو عدد را یکی بعد از دیگری به کامپیوتر بدهد، و شما نیاز دارید این دو عدد
را ذخیره کنید تا بعداً بتوانید آنها را درهم ضرب کنید. صرف نظر از اینکه شما با
حاصل ضرب چه کاری میخواهید انجام دهید، بهتر است آن را درجایی ذخیره کنید تا بعداً
مورد استفاده قرار گیرد. اگر شما بطور صریح آدرس آن خانه از حافظه را به برنامه
بدهید که قرار است این اعداد در آن ذخیره شوند (مثلاً بگوید در خانه 578
و 579 آنها را ذخیره کن)، چنین روشی آهسته و مستعد-خطا خواهد
بود، زیرا همیشه باید نگران آن باشید که قبلاً چیزی در آن خانهها نباشد تا شما با
نوشتن اطلاعات خود آنها را پاک کنید.
هنگامی که
در زبانهای مثل C++
برنامه می نویسید، شما متغیرهایی را تعریف میکنید که آن مقادیر را در خود ذخیره میکنند.
تعریف یک متغیر بسیار ساده است و از الگوی زیر پیروی میکند:
گونه_متغیر نام_متغیر ;
یا
گونه_متغیر نام_متغیر =
مقدار_اولیه;
گونه (یا
نوع) متغیر، از ماهیت دادهای که متغیر میتواند در خود ذخیره کند به کامپایلر اطلاع میدهد، و کامپایلر نیز متناسب با
گونه مشخص شده فضای لازم را برای آن کنار میگذارد. نامی که توسط برنامهنویس برای
متغیر انتخاب میشود، درحقیقت نام دیگری برای آدرس (عددی) حافظهای است که داده در
آنجا ذخیره میشود. شما نمیتوانید در آغاز از محتوای حافظهای که کامپایلر برای
متغیر شما کنار میگذارد مطمئن باشید، مگر اینکه از همان ابتدا یک مقدار اولیه نیز
برای آن درنظر بگیرید. از متغیری که هنوز مقدار دهی نشده استفاده نکنید، زیرا
معلوم نیست محتوای آن چه باشد. بنابراین اگرچه دادن مقدار اولیه به متغیر در شروع
تعریف اجباری نیست، ولی غالباً شیوه خوبی برای برنامهنویسی محسوب میشود. در لیست
3.1 نشان داده شده که متغیرها چگونه
اعلان میشوند، مقدار اولیه میگیرند، و چگونه در برنامهای که دو عدد را درهم ضرب
میکند از آنها استفاده میشود.
لیست 3.1 استفاده
از متغیرها برای
ذخیره دو عدد و حاصل ضرب آنها
1: #include
<iostream>
2: using namespace std;
3:
4: int main
()
5: {
6: cout<<“This program will help you multiply two numbers” << endl;
7:
8: cout << “Enter the first number: “;
9: int FirstNumber = 0;
10: cin >> FirstNumber;
11:
12: cout << “Enter the second number: “;
13: int SecondNumber = 0;
14: cin >> SecondNumber;
15:
16: // دو عدد را درهم ضرب کن و نتیجه را در یک متغیر ذخیره کن
17: int MultiplicationResult = FirstNumber * SecondNumber;
18:
19: // نتیجه را نمایش بده
20: cout << FirstNumber << “ x “ << SecondNumber;
21: cout << “ = “ << MultiplicationResult << endl;
22:
23: return 0;
24: }
خروجی
برنامه▼
This program will help you multiply two numbers
Enter the first number: 51
Enter the second number: 24
51 x 24 = 1224
تحلیل
برنامه▼
این
برنامه از کاربر میخواهد که دو عدد را وارد کند. برنامه این دو عدد را درهم ضرب و
نتیجه را نمایش میدهد. به منظور اینکه برنامه از اعداد وارد شده توسط کاربر
استفاده کند نیاز دارد تا آنها را در حافظه دخیره کند. متغیرهای FirstNumber و SecondNumber
که در خطوط 9 و 13 اعلان شدهاند کار ذخیره موقتی مقادیری که توسط کاربر وارد شده
را انجام میدهند. شما در خط 10 و 14 از std:cin برای گرفتن متغیرها استفاده کرده و آنها را در دو متغیر که از
نوع int
هستند ذخیره میکنید. در خط 21 برای نمایش حاصل ضرب بر روی کنسول از عبارت cout استفاده شده است.
بیایید تا
به اعلان متغیر نگاه بیشتری بکنیم:
9: int
FirstNumber = 0;
چیزی که
در این خط اعلان میشود یک متغیر از گونه int است، که نمایانگر
اعداد صحیح میباشند. نام متغیر FirstNumber است، و صفر نیز مقدار اولیهای است که به این متغیر داده میشود.
بنابراین
درمقایسه با زبان برنامه نویسی اسمبلی (assembly)، که در آن شما باید
بطور صریحی مشخص کنید که اعداد در چه جایی از حافظه ذخیره شوند، C++
شما را قادر میکند تا توسط متغیرهایی که نامهای قابل فهمی چون FirstNumber دارند به خانههای
حافظه دسترسی داشته باشد. کامپایلر برای
شما کار تبدیل این نامها به خانههای حافظه و سازماندهی کلی آنها را به عهده میگیرد.
بنابراین
برنامهنویس با اسامی قابل درک انسانی سر و کار خواهد داشت، و کار تبدیل متغیر به
آدرس حافظه، و ایجاد دستورات لازم برای پردازنده، را به کامپایلر محول می کند.
نامگذاری متغیرها اهمیت
خاصی برای نوشتن برنامههایی خوب، قابل درک، و ماندگار دارند.
نام متغیرها میتواند
حرفیعدد (alphanumeric) باشد، ولی شروع آن نباید با
یک عدد باشد. آنها نمیتوانند حاوی فاصله خالی باشند و نمیتوانند
حاوی عملگرهای حسابی (+, -, *, /) باشند. شما میتوانید برای جدا کردن کلماتی که در
نام متغیرها وجود دارد از علامت ‘_’، که زیرینخط (underscore) نامیده میشود، استفاده کنید.
نام متغیرها نمیتواند
یکی از کلیدواژههای زبان C++ باشد. برای مثال اگر شما متغیری بنام return در برنامه خود تعریف کنید
کامپایلر از شما خطا خواهد گرفت.
در لیست
3.1 متغیرهای FirstNumber،
SecondNumber و MultiplicationResult همه از یک گونه هستند (همه عدد صحیح هستند)
و در سه خط مجزا اعلان شدهاند. درصورتی که بخواهید میتوانید اعلان این سه متغیر
را کوتاهتر کرده و آنرا بصورت زیر در یک خط جای دهید:
int FirstNumber = 0,
SecondNumber = 0, MultiplicationResult = 0;
همانطور که میبینید C++ این امکان را به شما میدهد که چند متغیر که از یک نوع هستند را با هم اعلان کنید، و حتی همه آنها را در شروع تابع اعلان کنید. بااینحال بهترین شیوه برای اعلان یک متغیر، درست در جایی است که برای اولین بار به این متغیر نیاز دارید، زیرا پیروی از این شیوه برنامه را خواناتر میکند، و بدلیل اینکه مکان اعلان متغیر به مکان کاربرد آن نزدیک است، کسانی که آنرا میخوانند میتوانند سریعاً به گونه آن پیببرند.
داده موجود در متغیرها در RAM کامپیوتر ذخیره میشود. این دادهها با خاتمه برنامه، و یا خاموش
شدن کامپیوتر، از دست خواهند رفت، مگر اینکه برنامهنویس صریحاً برنامه را طوری
نوشته باشد که مقادیر موجود در متغیرها بصورت یک فایل در هارد دیسک کامپیوتر ذخیره
شوند.
ذخیره فایلها روی دیسک در درس 27 با عنوان
”استفاده از جریانها برای ورودی و خروجی“ مورد بررسی قرار میگیرد.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
در درسهای
قبلی متغیرهایی که اعلان میکردید تنها حاوی یک مقدار بود. ولی شما ممکن است بخواهید جمعی از اشیا،
مثلا بیست int و یا چند رشته، را اعلان کنید.
در این
درس شما یاد خواهید گرفت که:
§
آرایهها چه هستند و چگونه میتوان
آنها را اعلان کرد و بکار برد
§
رشتهها چه هستند و چگونه میتوان
از آرایههای حرفی برای ساختن آنها استفاده کرد
§
آشنایی مختصری با std::string
تعریفی که
در فرهنگ لغت برای
آرایه (array)
آمده با درکی که ما نسبت به آن داریم نزدیک است. مطابق با تعریفی که در فرهنگ لغت
وبستر آمده، یک آرایه یعنی ”گروهی از اعضا، که یک واحد کاملتر را تشکیل میدهند،
مثل آرایهای از صفحات خورشیدی“.
موارد زیر
مشخصههای یک آرایه هستند:
§
یک آرایه از جمعی از عضوها تشکیل شده است.
§
کلیه اعضای یک آرایه از یک گونه هستند.
§
این اعضا یک مجموعه کامل را تشکیل میدهند.
شما
بوسیله آرایهها میتوانید عناصر یک گونه خاص را، بصورت متوالی و مرتب، در حافظه
ذخیره کنید.
تصور کنید
برنامهای مینویسید که در آن کاربر
پنج عدد را وارد میکند و شما هم آنها را برای او نمایش میدهید. یک روش برای انجام
اینکار این است که شما پنج متغیر متمایز را برای این منظور اعلان کنید و از آنها
برای ذخیره و نمایش اعداد وارد شده استفاده کنید. چنین روشی شبیه زیر خواهد بود:
int FirstNumber = 0;
int SecondNumber = 0;
int ThirdNumber = 0;
int FourthNumber = 0;
int FifthNumber = 0;
اگر کاربر این برنامه بخواهد 500 عدد را وارد کند، آنگاه با این روش شما به اعلان 500 متغیر نیاز خواهید داشت. ولی بااینحال اگر به اندازه کافی وقت صرف کنید، اینکار امکانپذیر است. ولی تصور کنید که از شما بخواهند اینکار را بجای 5 عدد، برای 5,000,000 عدد انجام دهید. دراینصورت شما چه کار خواهید کرد؟
اگر
بخواهید کار را به روش درست و هوشمند آن انجام دهید، کافی است بجای 5 متغیر جداگانه، یک متغیر آرایهای تعریف کنید که میتواند پنج عدد را در خود
ذخیره کند. اعلان چنین متغیری، و مقدار اولیه دهی آن، بصورت زیر است:
int MyNumbers [5] = {0};
اگر از
شما خواسته شد اینکار را برای 5,000,000 عدد انجام دهید، تنها
کافیست تا اندازه آرایه را
بصورت زیر بالا ببرید:
int ManyNumbers [5000000] =
{0};
یک آرایه
که از پنج حرف تشکیل شده بصورت زیر تعریف میشود:
char MyCharacters [5];
به آرایههایی
که در بالا تعریف شد آرایههای ایستا (static
arrays) میگویند، زیرا تعداد اعضایی که این آرایهها
میتوانند در برداشته باشند، و نیز حافظهای که مصرف میکنند، هر دو در زمان
کامپایل تعیین میشوند و ثابت هستند[7].
در خطوط
قبلی شما آرایهای به نام MyNumbers
را اعلان کردید که حاوی پنج int
(یا همان اعداد صحیح) بود و همه آنها
با عدد 0 مقدار دهی شده بودند. بنابراین اعلان یک
متغیر در C++
از نحوه زیر پیروی میکند:
گونه_اعضای_آرایه نام_آرایه [تعداد_اعضای
آرایه] = {مقدار اولیه اختیاری};
شما حتی
میتوانید آرایهای را اعلان کنید و هر یک از اعضای آنرا جداگانه مقدار دهی کنید،
مانند آرایه زیر
که هر یک از پنج عضو آن توسط پنج عدد مختلف مقدار دهی شده است:
int MyNumbers [5] = {34, 56,
-21, 5002, 365};
شما میتوانید
کلیه اعضای یک آرایه را
با یک مقدار پر کنید، مانند زیر:
int MyNumbers [5] = {100}; //
100 مقداردهی کلیه اعضا به
شما
همچنین میتوانید چند عضو ابتدای یک آرایه را مقدار دهی کنید:
int MyNumbers [5] = {34, 56};
// مقداردهی دو عضو اول آرایه
شما
میتوانید طول یک آرایه (که
همان تعداد عضوهای آن باشد) را بصورت یک ثابت تعریف کنید، و از آن برای تعریف
آرایه خود استفاده کنید:
const int ARRAY_LENGTH = 5;
int MyNumbers [ARRAY_LENGTH] =
{34, 56, -21, 5002, 365};
چنین تعریفی
بویژه وقتی مفید است که نیاز باشد تا شما به طول یک آرایه در جاهای مختلفی از برنامه دسترسی داشته
باشید، مثلاً موقعی که اعضای یک آرایه را یک به یک بررسی میکنید، و یا در جایی که
نیاز باشد طول آرایه تغییر کند، شما بدون اینکه نیاز باشد تک تک جاهایی که در آنها
به طول آرایه اشاره شده را تغییر دهید، تنها کافیست مقداری را که بصورت const
برای طول آرایه اعلان کرده بودید تغییر دهید.
هنگامی که شما فقط قسمتهای ابتدایی یک آرایه را مقدار دهی میکنید، ممکن
است آن اعضایی که توسط شما مقدار دهی نشدهاند، با 0 مقدار دهی شوند.
اگر طول
یک آرایه با
تعداد مقادیر اولیهای که برای آن مشخص میکنید برابر باشد، میتوانید جای آنرا
خالی بگذارید و کامپایلر طول
این آرایه را برابر با تعداد مقادیر اولیه در نظر خواهد گرفت:
int MyNumbers [] = {2011,
2052, -525};
کد قبلی آرایهای
با طول سه ایجاد میکند و به آنها مقادیر 2011, 2052, و 525- را میدهد.
آرایههایی که تا اینجا تعریف شد همه از نوع ایستا
هستند، زیرا طول آرایه از قبل توسط برنامه نویس مشخص شده در زمان-کامپایل
معلوم و ثابت است. این نوع از آریایهها نمیتوانند بیش از ظرفیتی که برنامهنویس
برای آنها مشخص کرده در خود داده ذخیره کنند. همچنین اگر از کلیه اعضای آنها
استفاده نشود، این باعث نمیشود تا حافظه کمتری را مصرف کنند.
کتابهایی را تصور کنید که در یک ردیف پهلوی یکدیگر
قرار گرفتهاند. این نمونهای از یک آرایه یک بعدی است، زیرا فقط از یک جهت گسترش مییابد، و
آنهم از جهتی که شماره کتابها مشخص میکند. هر کتاب عضوی از یک آرایه است، و آن
ردیفی که کتابها در آن چیده شده شبیه حافظهای است که برای جادادن این مجموعه از کتابها آن استفاده شده. به شکل 4.1 نگاه
کنید.
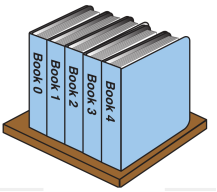
شکل 4.1 کتابهای قرار داده شده در یک ردیف: نمونهای از یک
آرایه یک
بعدی
هیچ
اشکالی نخواهد بود اگر شماره کتابها را از 0 شروع شود. همانگونه
که بعداً خواهید دید، اندیس (index)
در زبان C++
از 0 شروع میشود و نه از 1.
مشابه با 5 کتاب موجود در ردیف، آرایه MyNumbers هم که پنج عدد صحیح
را در خود جا میدهد بسیار شبیه شکل 4.2 است.
توجه کنید فضایی که آرایه اشغال کرده، از پنج بلوک تشکیل شده، که
اندازه همه آنها با هم برابر است. و این اندازه از روی گونه دادهای که قرار است
در آرایه ذخیره شود (و در اینجا اعداد صحیح هستند) تعیین میگردد. اگر بخاطر داشته
باشید، در درس 3 شما با مفهوم اندازه اعداد آشنا شدید. بنابراین مقدار حافظهای که
توسط کامپایلر برای
آرایه MyNumbers
کنار گذاشته میشود برابر است با
5*sizeof(int). بطور کلی، مقدار حافظهای که
توسط کامپایلر برای یک آرایه کنار گذاشته میشود از قاعده کلی زیر پیروی میکند:
تعداد بایتهایی که
بوسیله یک آرایه اشغال میشود
= sizeof(گونه آرایه) * تعداد اعضای آرایه
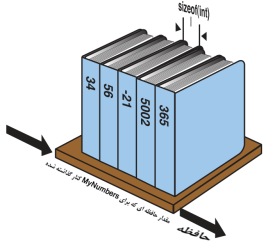
شکل 4.2 سازماندهی یک آرایه بنام MyNumbers در حافظه، که از پنج int
تشکیل شده.
...........................................
برای ادامه مطالعه این فصل نسخه
کامل PDF کتاب را تهیه کنید.
قلب یک برنامه
را دستوراتی تشکیل میدهند که باید بطور متوالی اجرا شوند. این دستورات بصورت عبارات (statement)
بیان میشود. در عبارات نیز برای انجام محاسبات و یا عملیات خاص دیگر، از عملگرها (operators)
استفاده میشود.
در این
درس شما یاد میگیرید که:
§
عبارات چه هستند
§
بلوکها یا عبارات ترکیبی چه
هستند
§
عملگرها چه هستند
§
چگونه عملیات حسابی و منطقی
ساده را انجام دهیم
زبانها،
چه انسانی باشند و چه کامپیوتری، از عباراتی ساخته میشوند که یکی بعد از دیگری
اجرا میشوند. اجازه دهید تا اولین عبارتی که شما در این کتاب یادگرفتید را با هم
تحلیل کنیم.
Cout << “Hello World” << end;
در بالا
عبارتی نشان داده شده که با استفاده از cout متنی را بر روی صفحه نشان میدهد. کلیه عبارات در C++
با سمیکلون (;) خاتمه مییابند، که حد و مرز عبارت را نیز تعیین میکند. عملکرد این علامت به
نقطه شباهت دارد که وقتی شما در بیشتر زبانهای انسانی آن را به یک جمله اضافه
کنید، نشانه پایان آن است. جمله بعدی را میتوان بلافاصله پس از سمیکلون شروع کرد،
ولی به منظور راحتی و خوانایی بهتر، شما معمولاً عبارات مختلف را در خطوط مختلف مینویسید.
البته، مانند آنچه در زیر نشان داده شده، میتوان چند عبارت را روی یک خط هم نوشت:
cout
<< “Hello World” << endl; cout << “Another hello” <<
endl; // یک خط، دو دستور
فضاهای خالی (Whitespaces) شامل حرف فاصله، حرف جدول (Tab)، حرف تعویض خط (line feed)، حرف بازگشت خط (carriage return) و غیره میشود. بطور کلی چنین حروفی از نظر کامپایلر پنهان هستند. هر چند استفاده از اینگونه فضاهای خالی در رشتههای لفظی موجب میشود تا خروجی برنامه متفاوت بنظر برسد.
نوشتن
عبارت زیر
معتبر نیست و کامپایلر به
آن ایراد میگیرد:
cout << “Hello
World” << endl; // new line in string literal not
allowed
نوشتن کُد
بالا معمولاً به خطا منجر میشود. خطایی مبنی بر اینکه که یا شما فراموش کردهاید
خط اول را با دابلکوتیشن (") ببندید، و یا اینکه عبارت خط اول را با یک سمیکلون (;)
پایان ندادهاید. درصورتیکه نیاز داشته باشید تا یک عبارت را روی دو (یا چند) خط
بنویسید، شما میتوانید خطوط مختلف را با حرف بکاسلَش (\) که در آخر آنها میآید
از هم جدا کنید. مثلاً عبارت بالا را بصورت زیر بنویسید:
cout << “Hello \
World” << endl; // split to two lines is OK
راه دیگری
که میتوانید عبارت قبلی
را روی دو خط بنویسید این است که بجای 1 رشته، از 2 رشته استفاده کنید:
cout << “Hello “
“World”
<< endl; // two string literals is also OK
در مثال
قبل، کامپایلر دو
رشته لفظی متوالی
هم را میبیند و آنها را برای شما به هم الحاق میکند.
هنگامی که شما با عبارت پیچیده که شامل چندین
متغیر است، و یا عناصر متنی طولانی سر و کار دارید، چند قسمت کردن عبارت بسیار
مفید خواهد بود، زیرا خواناتر است.
هنگامی که
عبارات را در میان علامت {…} قرار میدهید، شما
درحقیقت یک عبارت مرکب
یا بلوکی میسازید.
{
int Number = 365;
cout << “This
block contains an integer and a cout statement” << endl;
}
معمولاً یک بلوک چندین عبارات را دربر میگیرد تا نشان دهد آنها به یکدیگر تعلق دارند. بلوکها بویژه برای برنامهریزی عبارات شرطی و حلقهها مفید هستند و ما در درس 6 با عنوان ”کنترل روند برنامه“ بطور مفصل به آنها خواهیم پرداخت.
عملگرها
ابزارهایی هستند که C++ برای شما فراهم آورده تا
بتوانید با دادهها کار کنید، آنها را انتقال دهید، آنها را پردازش کنید، و
احتمالاً براساس آنها تصمیمگیری کنید.
در این
کتاب شما بدون آگاهی قبلی بارها از عملگر نسبت دهی (assignment)
استفاده کردهاید:
int MyInteger = 101;
در عبارت فوق از عملگر نسبت دهی استفاده شده تا به یک متغیر مقدار
101 را نسبت دهد. عملگر نسبت دهی مقداری را که در سمت چپ آن قرار دارد، و مقدار-سمت-چپی (l-value) نامیده میشود، با
مقداری را که در سمت راست آن قرار دارد، و مقدار-سمت-راستی (r-value) نامیده میشود،
جایگزین میکند.
غالباً l-valueها (یا مقادیر-سمت-چپی) مکانهایی در حافظه هستند. در مثال قبل، متغیری مانند MyInteger در واقع نامی برای
مکانی در حافظه است و بنابراین یک l-value محسوب میشود. درمقابل r-valueها (یا
مقادیر-سمت-راستی) هم میتوانند مقادیری ثابت باشند و هم میتوانند به مکانی از
حافظه اشاره کنند.
بنابراین
کلیه مقادیر-سمت-چپی میتوانند مقادیر-سمت-راستی باشند، ولی اینطور نیست که همه
مقادیر-سمت-راستی بتوانند مقادیر-سمت-چپی باشند. برای فهم بهتر این مورد، به مثال
زیر نگاه کنید، که اصلاً هیچ معنی ندارد و کامپایل هم نمیشود:
101 =
MyInteger;
101 یک ثابت است و جزء
دسته مقادیر-سمت-راستی بحساب میآید و در نتیجه نمیتواند در سمت چپ عملگر نسبت دهی ظاهر شود.
شما میتوانید
بر روی دو عملوند (operand) عملیات حسابی انجام
دهید، مثلاً با (+) آنها را باهم جمع کنید، با (-) دومی را از اولی کم کنید، با (*)
آنها را در هم ضرب کنید، با (/) اولی را بر دومی تقسیم کنید، و با (%) باقیمانده
تقسیم اولی بر دومی را حساب کنید.
int Num1 = 22;
int Num2 = 5;
int addition = Num1 + Num2; //
27
int subtraction = Num1 – Num2;
// 17
int multiplication = Num1 * Num2; // 110
int division = Num1 / Num2; // 4
int modulo = Num1 % Num2; // 2
دقت داشته
باشید که عملگر تقسیم
(/)، حاصل تقسیم دو عملوند را
بدست میدهد. ولی اگر هر دو عملوند اعداد صحیح باشند و حاصل تقسیم واقعی این دو
عدد یک عدد اعشاری باشد، در اینجا نتیجه تقسیم هیچ جزء اعشاری نخواهد داشت، زیرا
اعداد صحیح نمیتوانند جزء اعشاری داشته باشند (همچنین، حاصل تقسیم آنها هم نمیتواند
جزء اعشاری داشته باشد). عملگر باقیماندهگیری، باقیمانده تقسیم عملوندها را نشان
میدهد و تنها میتواند در مورد گونههای صحیح بکار گرفته شود. در لیست 5.1 برنامهای
آمده که عملیات حسابی را بر روی دو عدد که توسط کاربر وارد میشوند انجام میدهد.
لیست 5.1 نمایش انجام عملیات
حسابی بر روی اعدادی که توسط کاربر وارد میشوند
0: #include
<iostream>
1: using
namespace std;
2:
3: int main()
4: {
5: cout << “Enter two integers:” << endl;
6: int Num1 = 0, Num2 = 0;
7: cin >> Num1;
8: cin >> Num2;
9:
10: cout << Num1 << “ + “ << Num2<<“ = “ << Num1 + Num2 << endl;
11: cout << Num1 << “ - “ << Num2<<“ = “ << Num1 - Num2 << endl;
12: cout << Num1 << “ * “ << Num2<<“ = “ << Num1 * Num2 << endl;
13: cout << Num1 << “ / “ << Num2<<“ = “ << Num1 / Num2 << endl;
14: cout << Num1 << “ % “ << Num2<<“ = “ << Num1 % Num2 << endl;
15:
16: return 0;
17: }
خروجی
برنامه▼
Enter two integers:
365
25
365 + 25 = 390
365 - 25 = 340
365 * 25 = 9125
365 / 25 = 14
365 % 25 = 15
تحلیل
برنامه▼
برنامه به
اندازه کافی گویا هست. خطی که احتمالاً جالبتر از بقیه است، آن است که از عملگر باقیماندهگیری (%) استفاده شده (خط
14). کاری که در اینجا انجام میشود این است که اگر کاربر دو عدد 365 و 25 را وارد
کرده باشد، باقیمانده این دو نمایش داده میشود (15).
...........................................
برای ادامه مطالعه این فصل نسخه
کامل PDF کتاب را تهیه کنید.
بیشتر
برنامهها نیاز دارند در شرایط مختلف، و یا بر اساس آنچه کاربر وارد میکند،
عملیات متفاوتی را انجام دهند. به منظور اینکه برنامه خود را طوری طرح ریزی کنید
که عملیات مختلفی را انجام دهد، شما نیاز دارید از عبارات شرطی استفاده کنید تا در
موقعیتهای مختلف دستورات مختلفی را اجرا کند.
در این
درس شما یاد خواهید گرفت که:
§
چگونه برنامه را وادار کنیم تا
در شرایط مختلف رفتار متفاوتی داشته باشد
§
چگونه دستوراتی را که در یک
حلقه قرار دارند تکرار کنیم
§
چگونه روند اجرای برنامه را در
یک حلقه را بهتر کنیم
برنامههایی
که تا بحال با آنها مواجه شدید، به ترتیب متوالی اجرا میشدند (از بالا به پائین).
این یعنی همه خطوط اجرا میشدند و هیچ خطی نادیده گرفته نمیشد. ولی در بیشتر
برنامهها کمتر اتفاق میافتد که دستورات برنامه به چنین ترتیبی، از بالا به
پائین، اجرا شوند.
مثلاً فرض کنید اگر کاربر دکمه m را فشار دهد، برنامه دو عدد
را در هم ضرب کند، و اگر هر دکمه دیگری را فشار دهد آنها را با یکدیگر جمع کند.
همانگونه که در شکل 6.1 میبینید، اینطور نیست که با هر بار اجرای برنامه کلیه
خطوط آن اجرا شوند. اگر استفاده کننده چیزی به جز m را وارد کند، آن قسمتی از
برنامه اجرا میشود که اعداد را با هم جمع میکند. هیچ حالتی وجود ندارد که هر دو
قسمت برنامه بتوانند اجرا شوند.
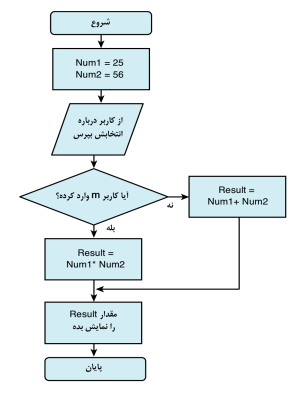
شکل 6.1 نمونهای از پردازشهای شرطی که براساس ورودی
کاربر صورت میگیرد.
اجرای
شرطی دستورات با استفاده از سازه if … else بصورت زیر است:
if (عبارت شرتی)
درصورتی که عبارت فوق صحیح ارزیابی شوداین دستورات را
انجام بده;
else // اختیاری
اگر عبارت فوق غلط ارزیابی شود
این
دستورات را انجام بده;
بنابراین سازه if … else که در زیر نشان داده شده، درصورتی که کاربر m را وارد کند اعداد در هم ضرب، و در غیر این صورت آنها را با هم جمع میکند.
if (UserSelection == ‘m’)
Result
= Num1 * Num2; // ضرب
else
Result
= Num1 + Num2; // جمع
توجه کنید که صحیح ارزیابی شدنِ یک عبارت در C++ به این معنی است که عبارت مورد نظر غلط (false) ارزیابی نشود. مقدار false برابر صفر است، و از این جهت برای اینکه یک عبارت false نباشد (یا true باشد)، کافیست که مقدار آن غیر-صفر باشد، مثبت و منفی بودن آن هم تفاوتی نمیکند.
اجازه
دهید در لیست 6.1 این سازه را بیشتر بررسی کنیم. در اینجا کاربر قادر است تا بر
اساس آنچه وارد میکند از میان جمع و ضرب یکی را انتخاب کند.
لیست 6.1 ضرب یا جمع دو عدد
بر اساس ورودی کاربر
0: #include
<iostream>
1: using
namespace std;
2:
3: int main()
4: {
5: cout << “Enter two integers: “ << endl;
6: int Num1 = 0, Num2 = 0;
7: cin >> Num1;
8: cin >> Num2;
9:
10: cout << “Enter \’m\’ to multiply, anything else to add: “;
11: char UserSelection = ‘\0’;
12: cin >> UserSelection;
13:
14: int Result = 0;
15: if (UserSelection == ‘m’)
16: Result = Num1 * Num2;
17: else
18: Result = Num1 + Num2;
19:
20: cout << “Result is: “ << Result << endl;
21:
22: return 0;
23: }
خروجی
برنامه▼
Enter two integers:
25
56
Enter ‘m’ to multiply, anything else to add: m
Result is: 1400
دور بعدی اجرای برنامه:
Enter two integers:
25
56
Enter ‘m’ to multiply, anything else to add: a
Result is: 81
تحلیل
برنامه▼
به کاربرد
if
در خط 15 و else در خط 17 توجه کنید. ما به کامپایلر میگوییم که اگر عبارت شرطی که پس از if در خط 15 آمده
(UserSelection == ‘m’ )
به true
ارزیابی شود آنگاه دو عدد در هم ضرب، و در غیر اینصورت آنها را با هم جمع کند.
(UserSelection == ‘m’ ) عبارتی است که فقط
درصورتی به true
ارزیابی میشود که کاربر حرف m
(حرف کوچک ام) را وارد کند، در غیر اینصورت به false ارزیابی میشود.
بنابراین این برنامه آنچه که در فلوچارت (flowchart) 6.1 نشان داده شده
را قالب بندی میکند و نشان میدهد که چگونه برنامه شما میتواند در شرایط مختلف رفتار
متفاوتی را از خود بروز دهد.
کاربرد else در سازه if … else اختیاری است، و در صورت غلط ارزیابی شدن عبارط شرطی و نداشتن حالت دیگری برای اجرای برنامه، نیازی هم به کاربرد else نیست.
اگر خط 15 لیست 6.1 بصورت زیر نوشته شود:
15: if (UserSelection
== ‘m’);
آنگاه سازه if بیمعنی خواهد بود، زیرا بدلیل وجود (سمیکلون) در
آخر خط، این خط با یک عبارت خالی خاتمه پیدا کرده. بدلیل اینکه چنین عبارتی از نظر دستوری خطا بحساب
نمیآید، کامپایلر هم به برنامه شما خطا نمیگیرد، بنابراین دقت کنید تا از چنین چیزهایی
پرهیز کنید.
برخی کامپایلرهای خوب در چنین مواقعی به شما
اخطار ”empty control statement“ را میدهند.
اگر
درصورت برآورده شدن یک شرط، بجای یک عبارت، بخواهید چندین عبارت را اجرا کنید،
باید آنها را بصورت بلوک درآورید. اساساً این کار با محصور کردن عبارتی که باید
اجرا شوند در کروشه {
... } انجام میگیرد. برای مثال:
if (عبارت شرطی)
{
// درصورت برآورده شدن شرط
عبارت 1;
عبارت 2;
}
else
{
// درصورت برآورده نشدن شرط
عبارت 3;
عبارت 4;
}
به چنین بلوکهایی عبارات مرکب نیز گفته میشود.
در درس 4
با عنوان ” کار با آرایهها و رشتهها“، شما با خطرات استفاده از آرایههای ایستا
و تجاوز از محدوده تعریف آنها آشنا شدید. این مشکل بیش از هرجای دیگری خود را در
آرایههای حرفی نشان میدهد. هنگامی که یک رشته در یک آرایه حرفی نوشته، یا در آن کپی میشود، مهم است
که بررسی شود تا ببینیم آرایه مورد نظر به اندازه کافی بزرگ هست که بتواند این
حروف را در خود جای دهد یا نه. در لیست 6.2 نشان داده میشود که چگونه با این
بررسی مهم میتوانید از بروز خطای ”سریز بافر“ جلو گیری کنید.
لیست 6.2 بررسی ظرفیت یک
آرایه قبل
از کپی کردن یک رشته در آن
0: #include
<iostream>
1: #include
<string>
2: using
namespace std;
3:
4: int main()
5: {
6: char Buffer[20] = {‘\0’};
7:
8: cout << “Enter a line of text: “ << endl;
9: string LineEntered;
10: getline (cin, LineEntered);
11:
12: if (LineEntered.length() < 20)
13: {
14: strcpy(Buffer, LineEntered.c_str());
15: cout << “Buffer contains: “ << Buffer << endl;
16: }
17:
18: return 0;
19: }
خروجی برنامه▼
Enter a line of text:
This fits buffer!
Buffer contains: This fits buffer!
تحلیل برنامه▼
توجه کنید
که چگونه در خط 12 قبل از اینکه رشته در بافر کپی شود، طول رشته با طول بافر
مقایسه میشود. چیز بخصوصی که درباره این if وجود دارد حضور یک
عبارت مرکب
است که از خط 13 تا 16 ادامه دارد.
توجه داشته باشید که نیازی نیست تا در آخر
خطی که در آن (شرط)if آمده سمیکلون گذاشته شود. این مورد عمداً در زبان C++ گنجانده شده تا تضمین کند
درصورت صحیح بودن شرط، عبارتی که بعد از if میآید اجرا شود.
بنابراین خطوط زیر
if(شرط);
statement;
هرچند کامپایلر به
آنها ایرادی نمیگیرد و کامپایل میشوند، ولی نتیجه مورد نظر از آن حاصل نمیشود،
زیرا If بوسیله سمیکلونی که در آخر
خط آمده خاتمه یافته و خطی که بعد از آن آمده (صرف نظر از اینکه نتیجه عبارت شرطی درست باشد یا نه) همیشه اجرا میشود.
خیلی از اوقات
پیش میآید که شما نیاز دارید شرایطی را بررسی کنید که نتایج هر یک از آنها به
شرایط پیشین بستگی دارند. به این منظور C++ به شما اجازه میدهد
تا از عبارت if بصورت تو در تو (nested) استفاده کنید.
عبارات if تو در تو شبیه زیر است:
if (عبارت1)
{
اجرای
دستور 1;
if(عبارت2)
اجرای دستور 2;
else
اجرای دستور دیگر 2;
}
else
اجرای دستور دیگر 1;
برنامهای را درنظر بگیرید که شبیه لیست 6.1 باشد و کاربر بتواند به برنامه فرمان دهد که اگر او حرف d را وارد کرده باشد، عمل تقسیم دو عدد، و اگر m را وارد کرده باشد، عمل ضرب آنها را انجام دهد. همانطور که میدانید عمل تقسیم تنها در مواقعی مجاز است که مقسومعلیه صفر نباشد. پس در چنین برنامهای ما علاوه براینکه باید بدانیم کاربر چه کاری میخواهد انجام دهد (ضرب یا تقسیم) باید مطمئن شویم که عددی را که بعنوان مقسومعلیه وارد کرده صفر نباشد. برای اینکار در لیست 6.3 از سازه if تو در تو استفاده شده.
لیست 6.3 استفاده از if تو در تو برای برنامه ضرب و تقسیم
0: #include
<iostream>
1: using
namespace std;
2:
3: int main()
4: {
5: cout << “Enter two numbers: “ << endl;
6: float Num1 = 0, Num2 = 0;
7: cin >> Num1;
8: cin >> Num2;
9:
10: cout << “Enter ‘d’ to divide, anything else to multiply: “;
11: char UserSelection = ‘\0’;
12: cin >> UserSelection;
13:
14: if (UserSelection == ‘d’)
15: {
16: cout << “You want division!” << endl;
17: if (Num2 != 0)
18: {
19: cout << “No div-by-zero, proceeding to calculate” << endl;
20: cout << Num1 << “ / “ << Num2 << “ = “ << Num1 / Num2 << endl;
21: }
22: else
23: cout << “Division by zero is not allowed” << endl;
24: }
25: else
26: {
27: cout << “You want multiplication!” << endl;
28: cout << Num1 << “ x “ << Num2 << “ = “ << Num1 * Num2 << endl;
29: }
30:
31: return 0;
32: }
خروجی برنامه▼
Enter two numbers:
45
9
Enter ‘d’ to divide, anything else to multiply: m
You want multiplication!
45 x 9 = 405
دور بعدی اجرای برنامه
Enter two numbers:
22
7
Enter ‘d’ to divide, anything
else to multiply: d
You want division!
No div-by-zero, proceeding to calculate
22 / 7 = 3.14286
دور آخر اجرای برنامه
Enter two numbers:
365
0
Enter ‘d’ to divide, anything
else to multiply: d
You want division!
Division by zero is not allowed
تحلیل برنامه▼
خروجی برنامه
حاصل سه بار اجرای مکرر آن با ورودیهای مختلف است، و همانگونه که میبینید برنامه
هر بار مسیرهای مختلفی را طی میکند. در این برنامه نسبت به لیست 6.1 تغییراتی
بوجود آمده:
§
به منظور اینکه بتوان در تقسیم
اعداد جزء اعشاری را هم نمایش داد، این بار بجای اعداد صحیح از اعداد ممیز-شناور
استفاده شده.
§
شرط if با آنچه در لیست 6.1 آمده تفاوت دارد. اینبار شما بررسی نمیکنید که
ببینید آیا کاربر دکمه m را فشار داده؛ در عوض خط 14 حاوی عبارت (UserSelection
== ‘d’) است و هنگامیکه کاربر d را وارد میکند این عبارت هم
به true
ارزیابی میشود. اگر چنین باشد آنگاه روند انجام تقسیم دو عدد دنبال خواهد شد.
§
بشرط اینکه انتخاب کاربر انجام
عمل تقسیم باشد، در اینصورت مهم خواهد بود تا مقسومعلیه صفر نباشد. بررسی این
مورد در خط 17 انجام میشود.
بنابراین
برنامه نشان میدهد در مواقعی که انجام یک عمل خاص، به ارزیابی پارامترهای
گوناگونی وابسته باشد، چگونه سازههای if تو در تو میتوانند به ما کمک کند.
فاصلهگذاریهایی که در برنامه قبلی بصورت تو
در تو انجام گرفته اختیاری است، ولی انجام اینکار باعث میشود تا هنگامی که از ifهای تو در تو استفاده میکنید خوانایی برنامه شما
به میزان زیادی بالا رود.
توجه داشته باشید که سازههای if … else
نیز میتوانند با یکدیگر گروهبندی شوند. در لیست 6.4 برنامهای نشان داده شده که
از کاربر میخواهد تا شماره یکی از روزهای هفته را وارد کند، و سپس با استفاده از
سازههای if
… else، که با یکدیگر گروهبندی شدهاند، نام اجرام آسمانی که به آن روز هفته نسبت داده شده را نمایش
میدهد.
لیست 6.4 نمایش نام اجرام
آسمانی که به روزهای هفته نسبت داده شدهاند
0: #include
<iostream>
1: using
namespace std;
2:
3: int main()
4: {
5: enum DaysOfWeek
6: {
7: Sunday = 0,
8: Monday,
9: Tuesday,
10: Wednesday,
11: Thursday,
12: Friday,
13: Saturday
14: };
15:
16: cout << “Find what days of the week are named after!” << endl;
17: cout << “Enter a number for a day (Sunday = 0): “;
18:
19: int Day = Sunday; // Initialize to Sunday
20: cin >> Day;
21:
22: if (Day == Sunday)
23: cout << “Sunday was named after the Sun” << endl;
24: else if (Day == Monday)
25: cout << “Monday was named after the Moon” << endl;
26: else if (Day == Tuesday)
27: cout << “Tuesday was named after Mars” << endl;
28: else if (Day == Wednesday)
29: cout << “Wednesday was named after Mercury” << endl;
30: else if (Day == Thursday)
31: cout << “Thursday was named after Jupiter” << endl;
32: else if (Day == Friday)
33: cout << “Friday was named after Venus” << endl;
34: else if (Day == Saturday)
35: cout << “Saturday was named after Saturn” << endl;
36: else
37: cout << “Wrong input, execute again” << endl;
38:
39: return 0;
40: }
...........................................
برای ادامه مطالعه این فصل نسخه
کامل PDF کتاب را تهیه کنید.
تا اینجای کتاب شما برنامههای سادهای
را مشاهده کردید که کلیه فعالیتهای
برنامه فقط در یک تابع، که ()main نام دارد، جا
میگرفت. این برای انجام کارهای کوچک مشکلی ایجاد نمیکند و برنامه میتواند
بخوبی از پس انجام وظایف خود برآید. ولی هر چقدر برنامه شما پیچیدهتر و بزرگتر شود،
محتوای تابع main()
نیز بزرگتر میشود، مگر اینکه طوری ساختار برنامه خود را تغییر دهید که در آن از
توابع متعدد استفاده شود.
توابع این
امکان را در اختیار شما قرار میدهند تا برنامه خود را به بخشهای کوچکتری تقسیم
کنید، و نیز شما را قادر میکند تا محتوای برنامه خود را به بلوکهای منطقی تقسیم
کنید که بصورت متوالی فراخوانده میشوند.
بنابراین
یک تابع، زیربرنامهای (subprogram) است که بصورت
اختیاری پارامترهایی را میگیرد و در مقابل مقداری را بازمیگرداند. برای اینکه
تابع چنین کاری را انجام دهد باید فراخوانی شود.
در این
درس شما یاد خواهید گرفت که:
§
چرا نیاز داریم تا در برنامهنویسی
از توابع استفاده کنیم
§
گونههای توابع و چگونگی تعریف
توابع
§
فرستادن پارامترها به توابع و
بازگرداندن مقادیر از آنها
§
سربارگزاری توابع
§
توابع بازگشتی
§
توابع لاندا در C++11
برنامهای را درنظر بگیرید که در آن از کاربر خواسته
میشود شعاع یک دایره را وارد کند و سپس توسط آن، محیط و مساحت دایره را محاسبه
کند. یک راه برای انجام اینکار این است که همه عملیات را در داخل تابع main() انجام دهیم. روش دیگر
این است که این برنامه را به بلوکهای منطقی تقسیم کنیم، بویژه آن دو قسمتی که
محیط و مساحت دایره را حساب میکند. چنین برنامهای در لیست 7.1 آمده است.
لیست 7.1 دو تابع که با داشتن شعاع یک دایره، محیط و مساحت آن را حساب میکنند
0: #include
<iostream>
1: using
namespace std;
2:
3: const
double Pi = 3.14159;
4:
5: // اعلان توابع (یا تعریف پیش نمونه آنها)
6: double Area(double InputRadius);
7: double Circumference(double InputRadius);
8:
9: int main()
10:{
11: cout << “Enter radius: “;
12: double Radius = 0;
13: cin >> Radius;
14:
15: // “Area” فراخوانی تابع
16: cout << “Area is: “ << Area(Radius) << endl;
17:
18: // “Circumference” فراخوانی تابع
19: cout << “Circumference is: “ << Circumference(Radius)<< endl;
20:
21: return 0;
22: }
23:
24: // تعریف تابع (که به آن پیاده سازی نیز گفته میشود)
25: double Area(double InputRadius)
26: {
27: return Pi * InputRadius * InputRadius;
28: }
29:
30: double Circumference(double InputRadius)
31: {
32: return 2 * Pi * InputRadius;
33: }
خروجی برنامه▼
Enter radius: 6.5
Area is: 132.732
Circumference is: 40.8407
تحلیل برنامه▼
در نگاه اول
این برنامه شبیه برنامههای قبلی بنظر میرسد، ولی در یک بسته بندی متفاوت. شما از
اینکه میبینید برنامه برای محاسبه محیط و مساحت دایره به توابع متفاوتی تقسیم
شده، راضی خواهید بود، زیرا میتوانید هر موقعی که بخواهید مکرراً این توابع را
فراخوانی کنید. main()، که خود نیز یک تابع است،
خیلی کوچک و جمع و جور شده و کارهای اصلی را بر دوش توابعی مثل Area
و Circumference
گذاشته که به ترتیب در خطوط 16 و 19 فراخوانی میشوند.
برنامه
فوق دربردارند مواردی درباره استفاده از توابع در برنامهنویسی است، از جمله
اینکه:
§
پیشنمونه توابع در خطوط 6 و 7 تعریف شدهاند، به همین
دلیل کامپایلر میداند
چیزهای مانند Area
و Circumference
که در بدنه اصلی main()
بکار رفتهاند چه هستند.
§
تابع Area() و Circumference() در خطوط 16 و 19 در main() فراخوانی (invoked) یا احضار میشوند.
§
تابع Area() در خطوط 25 الی 28، و تابع Circumference() در خطوط 30 الی
33 تعریف (define)
شدهاند.
اجازه
دهید تا به لیست 7.1 نگاه دوبارهای بیاندازیم، بویژه خطوط 6 و 7:
6: double Area(double InputRadius);
7: double Circumference(double InputRadius);
شکل 7.1 نشان میدهد که پیشنمونه یک تابع از چه چیزهایی تشکیل شده است:

شکل 7.1 قسمتهای مختلف پیشنمونه یک تابع
اساساً
پیشنمونه یک
تابع (prototype)[8]
این موارد را مشخص میکند: 1- نام تابع (در مثال بالا Area)، 2- فهرست پارامترهای تابع
(در مثال بالا تابع فقط یک پارامتر از گونه double قبول میکند که InputRadius نامیده میشود)، و 3-
گونهِ مقدار بازگردانده شده از تابع.
اگر در
برنامه قبلی از پیشنمونه تابع
استفاده نشده بود، آنگاه در خطوط 16 و 19 تابع main، کامپایلر نمیدانست که عباراتی نظیر Area
و Circumference چه هستند. پیشنمونه
تابع به کامپایلر خواهد گفت که Area
و Circumference
تابع هستند، توابعی که یک پارامتر از نوع double را گرفته و همچنین یک
مقدار از نوع double
را باز میگردانند. به همین دلیل است که کامپایلر این عبارات را معتبر ارزیابی میکند.
کار پیوند دادن این
توابع با پیادهسازی (implementation) آنها، و همچنین
اطمینان از اینکه در هنگام اجرای برنامه این توابع فراخوانی میشوند، اینها همه
وظیفه لینکر (linker)
است.
یک تابع بعنوان ورودی خود میتواند
پارامترهای متعددی داشته باشد که با کاما از یکدیگر جدا میشوند، ولی در مقابل
برای خروجی خود تنها میتواند یک مقدار را باز گرداند.
هنگامی که تابعی را مینویسید که نیازی به
بازگرداندن چیزی ندارد، گونه بازگردانده شده آن را void تعریف کنید.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
علاوه بر
اینکه C++ شما را قادر میکند تا برنامههای سطح-بالایی بنویسید که عملکرد آنها کاملاً
مستقل از ماشین است، همچنین یکی از مزیتهای مهم آن این است که میتوانید با آن
برنامههایی بنویسید که در سطح-پایین با سخت افزار کامپیوتر در ارتباط هستند.
حقیقتاً C++
شما را قادر میکند تا روند اجرای برنامه خود را در سطحِ ”بیتها و بایتها“ در
دست بگیرید.
درک اشارهگرها
و ارجاعات باعث میشود تا بتوانید برنامههایی بنویسید که مصرف منابع در آنها
بهینه شدهاند.
در این
درس شما یاد خواهید گرفت که:
§
اشارهگرها چیستند
§
فضای آزاد چیست
§
چگونه برای تخصیص حافظه از
عملگرهای new
و delete
استفاده کنید
§
چگونه با استفاده از اشارهگرها،
و تخصیص حافظه به روش پویا، برنامههای پایداری بنویسید
§
ارجاعات چه هستند
§
تفاوت بین یک اشارهگر و یک ارجاع
§
چه موقع از اشارهگر استفاده کنیم و چه موقع از ارجاع
اگر بخواهیم بطور خلاصه بگوییم، یک اشارهگر (pointer) متغیری است که آدرسهای حافظه را در خود
ذخیره میکند. همانطور که متغیری از گونه int برای ذخیره یک عدد صحیح
بکار میرود، یک متغیر اشارهگر نیز حاوی آدرسهای حافظه است.
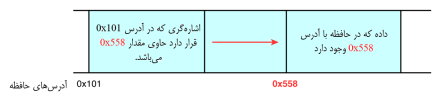
شکل 8.1 تجسم یک اشارهگر
بنابراین
یک اشارهگر یک
متغیر است، و مانند کلیه متغیرها قسمتی
از حافظه را اشغال می کند (در مورد شکل 8.1 آدرس این قسمت از حافظه 0x101 است). چیز خاصی که در مورد اشارهگرها وجود
دارد این است که از مقداری که در آنها قرار دارد (در مورد مثال قبلی، 0x558) بعنوان یک آدرس حافظه تعبیر
میشود. بنابراین اشارهگر متغیر خاصی است که به مکانی از حافظه اشاره میکند.
بدلیل
اینکه اشارهگر یک
متغیر محسوب میشود، مانند هر متغیر دیگری باید آن را اعلان کنید. شما معمولاً یک
اشارهگر را طوری اعلان میکنید که به گونه خاصی اشاره کند (برای مثال به یک int).
این یعنی آدرسی که در اشارهگر قرار دارد به مکانی از حافظه اشاره میکند که یک
عدد صحیح (int)
را در خود نگاه میدارد. شما همچنین میتوانید اشارهگرهایی را اعلان کنید که به
گونه خاصی وابسته نباشند و در عوض به یک بلوک از حافظه اشاره کنند. به اینگونه
اشارهگرها، اشارهگرهای void گفته میشود.
مانند
کلیه متغیرهای دیگر، یک متغیر اشارهگر نیز باید اعلان شود:
گونهاشارهگر * نام_متغیر_اشارهگر;
مانند هر
متغیر دیگری، اگر شما مقدار اولیه معینی را برای اشارهگرها تعیین نکنید، آنها
حاوی مقادیر تصادفی و نامشخص خواهند بود. بدلیل اینکه شما نمیخواهید اشارهگرتان
به مکان نامشخصی اشاره کنند، به آنها مقدار اولیه NULL را میدهید. NULL
مقداری است که کاملاً مشخص است و شما میتوانید با مقایسه آن با مقادیر ممکن دیگر،
بررسی کنید که آیا اشارهگر شما
به مکان معتبری از حافظه اشاره میکند ( اگر با NULLمساوی نباشد) یا نه ( اگر با NULL
مساوی باشد).
گونهاشارهگر * نام متغیر اشارهگر =
NULL; // مقدار دهی اولیه به اشارهگر
بنابراین
یک اشارهگر که
به یک عدد صحیح از نوع int اشاره میکند بصورت زیر اعلان میشود:
int *pInteger = NULL; //اشارهگری که به یک عدد صحیح اشاره
میکند
مانند همه متغیرهایی که تاکنون با آنها آشنا شدهاید، یک اشارهگر نیز درصورتی که مقدار دهی نشده باشد حاوی مقادیر تصادفی و نامعین است. اشارهگرهایی که مقدار آنها نامعلوم باشند خطرناکند، زیرا قرار است یک اشارهگر محتوای آدرسی از حافظه کامپیوتر باشد. اشارهگرهای که مقدار اولیه به آنها داده نشده باشد میتوانند باعث شود تا برنامه شما به مکانهای غیرمجازی از حافظه دسترسی پیدا کند، و چنین چیزی نهایتاً به سقوط برنامه منجر خواهد شد.
متغیرها ابزارهایی هستند که زبان برنامهنویسی (مثل C++)
آن را در اختیار شما قرار میدهد تا بتوانید براحتی با دادههای موجود در حافظه
کامپیوتر کار کنید. این مفهوم بطور مفصل در 3 درس مورد بحث قرار گرفت. اشارهگرها
نیز متغیر هستند، ولی آنها نوع خاصی از متغیرند که صرفاً میتواند آدرسهای حافظه
را در خود ذخیره کنند.
اگر VarName یک متغیر باشد، &VarName
آدرسی از حافظه را مشخص میکند که به VarName
تعلق دارد.
بنابراین
اگر شما یک متغیر را با روشی که بخوبی با آن آشنا شدهاید اعلان کنید، و مثلاً
بنویسد:
int Age = 30;
آنگاه &Age آدرسی از
حافظه است که در درون آن عدد 30 قرار گرفته است. لیست
8.1 مفهوم آدرس متغیری از نوع صحیح را نشان میدهد.
لیست 8.1 تعیین
آدرس دو متغیر، یکی از نوع int و دیگر از نوع double
0: #include
<iostream>
1: using
namespace std;
2:
3: int main()
4: {
5: int Age = 30;
6: const double Pi = 3.1416;
7:
8: //در آن ذخیره شده Age برای یافتن آدرس حافظهای که & استفاده از
9: cout << “Integer Age is at: 0x” << hex << &Age << endl;
10: cout << “Double Pi is located at: 0x” << hex << &Pi << endl;
11:
12: return 0;
13: }
خروجی برنامه▼
Integer Age is at: 0x0045FE00
Double Pi is located at: 0x0045FDF8
تحلیل برنامه▼
توجه کنید
که چگونه از عملگر ارجاع (&) در خطوط 9 و 10 برنامه برای گرفتن آدرس
متغیرهای Age و نیز ثابت Pi استفاده شده. بنا بر عرف،
آدرس مکانهای حافظه بصورت اعدادی در مبنای شانزده نمایش داده میشوند، و به همین
دلیل 0x
به این عبارات اضافه شده که نشان دهد این اعداد در
مبنای 16 هستند و نه در مبنای 10.
شما میدانید که مقدار حافظهای که توسط یک
متغیر اشغال میشود بستگی به گونه آن دارد. لیست 3.4 که در آن از sizeof() استفاده شده بود، نشان میداد که اندازه یک متغیر از گونه int 4 بایت است (البته روی
کامپیوتر و کامپایلری که من استفاده میکنم اینطور نشان میدهد). بنابراین در مثال
قبل که نشان میداد آدرس متغیر Age 0x0045FE00 است، و با توجه به اینکه اندازه یک متغیر int 4 بایت است شما میتوانید
نتیجه بگیرید که خانههای حافظه از آدرس0x0045FE00 الی 0x0045FE03 به متغیر Age تعلق دارند.
عملگر ارجاع (&)، عملگر آدرس نیز نامیده میشود.
...........................................
برای ادامه مطالعه این فصل نسخه
کامل PDF کتاب را تهیه کنید.
تا اینجا
شما یادگرفتید که چگونه برنامههایی را بنویسید که ساختار سادهای دارند و با
اجرای تابع main()
شروع میشوند و شما را قادر میسازد تا متغیرهای محلی، سراسری، و ثابتها را اعلان
کنید، و نیز نحوه اجرای منطقی برنامه خود را به شاخههای مختلفی به نام توابع
تقسیم کنید که میتوانند پارامترهایی را دریافت کرده و مقادیری را بازگردانند.
کلیه این کارها شباهت زیادی به زبانهایی مانند C دارد که از نوع زبانهای رویهای (procedural language)
هستند، و در آنها خبری از مفاهیم شیءگرا نیست. به عبارت دیگر، اگر بخواهید برنامههای خود را به
فرآیندهایی شیءگرا تبدیل کنید، شما باید بتوانید دادهها را سامان دهید، و برای
اینکار باید مِتُدهایی (methode) را به آنها متصل
کنید.
در این
درس شما یا خواهید گرفت که:
§
کلاسها چیستند
§
چگونه کلاسها به شما کمک میکنند
که دادهها را با مِتُدها (که در حقیقت توابع هستند) بستهبندی کنید
§
سازندهها، ”سازندههای کپی“،
و تخریبگرها چه هستند
§
چگونه C++11 میتواند کارایی کلاسها را با ”سازنده انتقال“ بهبود بخشد.
§
اشارهگر this
چیست
§
struct
چیست و تفاوت آن با class چگونه است
فرض کنید شما برنامهای مینویسید که یک انسان را
مُدلسازی میکند. این انسان نیاز دارد تا دارای هویت باشد. این هویت شامل چیزهای
مثل: نام، تاریخ تولد، محل تولد، و جنسیت است. یک انسان میتواند کارهای خاصی را
انجام دهد، از جمله سخن گفتن، معرفی خودش و غیره. اطلاعاتی که بعنوان هویت ذکر
شدند، دادههایی را تشکیل میدهد که درباره انسان است، در حالی که اطلاعات دوم
شامل کارهایی است که انسان میتواند با این دادهها انجام دهد.

شما برای
مدلسازی یک انسان به سازهای نیاز دارید که بتوانید این موارد را در داخل آن دسته
بندی کنید: 1- خصوصیاتی (attributes) که یک انسان را مشخص
میکنند (دادهها) و 2- با خصوصیاتی که یک انسان دارد، چه کارهایی را میتواند
انجام دهد (مِتُدها). به سازهای که بتوان چنین دستهبندی (یعنی، دادهها و متدها)
را در خود جای دهد کلاس (class) میگویند.
اعلان یک کلاس
با کلیدواژه class شروع میشود و بدنبال آن نام
کلاس میآید، و پس از آن یک بلوک {…} قرار میگیرد که در
داخل آن مجموعهای از مشخصهها (دادهها) و متدها قرار میگیرند، در آخر بلوک هم
یک سمیکلون اضافه میشود.
اعلان یک
کلاس شبیه اعلان یک تابع است. این اعلان، کامپایلر را از کلاس و خصوصیات آن با خبر میکند. همانگونه که تعریف یک
تابع موجب نمیشود تا بصورت خودکار اجرا شود، تعریف یک کلاس نیز تفاوتی در روند
اجرای برنامه بوجود نمیآورد، مگر اینکه این کلاس در برنامه مورد استفاده قرار
گیرد.
کلاسی که
یک انسان را مدلسازی میکند شبیه زیر خواهد بود (البته توجه دارید که ما به علت
کمبود جا نمیتوانیم کلیه خصوصیات یک
انسان را در اینجا ذکر کنیم، و این تنها یک مثلا است):
class Human
{
// مشخصات دادهای:
string
Name;
//نام
string DateOfBirth; // تاریخ تولد
string PlaceOfBirth; // محل تولد
string Gender; // جنسیت
// متدها، یا همان کارهایی که انسان میتواند انجام دهد:
void Talk(string TextToTalk); // صحبت کردن
void IntroduceSelf(); // معرفی کرد خود
.
.
.
};
نیازی به گفتن ندارد که مِتُدی مثل IntroduceSelf() (معرفی خود)، از دادههای درون کلاس Human، و نیز متد Talk() (صحبت کردن) استفاده می کند. بنابراین C++ با فراهم کردن کلیدواژه class، روش قدرتمندی برای شما فراهم میکند تا بتوانید گونههایی را ایجاد کنید که دادهها و متدها (یا همان توابع) را باهم بستهبندی [9] (encapsulate) میکند و اجازه میدهد تا این متدها بر روی دادهها عمل کنند. کلیه ویژگیهای خاص یک کلاس، که در مثال فوق شامل Name، DateOfBirth، PlaceOfBirth و Gender میشود، و کلیه توابعی که در داخل آن تعریف شدهاند، مثل Talk() وIntroduceSelf() ، همگی اعضایی از کلاس Human هستند.
بستهبندی عبارت است از توانایی دستهبندی دادهها و متدهایی
که بر روی این دادهها کار میکند. این مفهوم از ارکان اصلی برنامهنویسی شیءگرا
بحساب میآید.
متدها اساساً توابعی هستند که به یک کلاس
تعلق دارند.
کلاس
مانند یک طرح اولیه است، و اعلان کردن یک کلاس بتنهایی هیچ تاثیری بر روی روند
اجرای برنامه ندارد. صورت واقعی یک کلاس پس از ایجاد آن در زمان اجرای برنامه، شیء
(Object)
نام دارد. برای اینکه از کلیه ویژگیهای یک کلاس استفاده کنید، شما معمولاً بر
اساس آن کلاس شیئ را نمونهسازی میکنید (instantiate)، و از آن شیء ایجاد
شده برای دستیابی به دادهها و متدهای کلاس استفاده خواهید کرد.
ایجاد یک
شیء از گونه کلاس Human،
مشابه ایجاد هر گونه دیگری است (مثلاً double):
double Pi = 3.1415; // در پشته double ایجاد
یک متغیر محلی از نوع
//که بعنوان یک متغیر
محلی اعلان شده Human ایجاد یک شیءاز کلاس
Human Tom;
و یا میتوانید
همین کار را بصورت دیگری توسط تخصیصدهی پویا انجام دهید:
//
ایجاد یک عدد صحیح در فضای آزاد که بصورت پویا ایجاد شده
int* pNumber = new int;
delete pNumber; // آزاد سازی حافظه
// در فضای آزاد حافظه Human ایجاد یک شیء از کلاس
Human* pAnotherHuman = new Human();
delete pAnotherHuman; // Humanآزاد سازی فضای اختصاص یافته برای یک
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
برنامهنویسی
شیءگرا بر
پایه چهار اصل مهم بنا شده: بستهبندی (encapsulation)، پنهانسازی (abstraction)، وراثت (inheritance)، و چندریختی (polymorphism). وراثت روش قدرتمندی
برای استفاده مجدد از خصیصهها است و همچنین ورود به مبحث چندریختی از وراثت آغاز
میشود.
در این
درس شما یادخواهید گرفت که:
§
مفهوم وراثت در برنامه نویسی
§
نحوه تعریف وراثت در C++ چگونه است
§
وراثتهای عمومی، خصوصی، و
حفاظت شده چه هستند
§
وراثتهای چندگانه چیست
§
مشکلاتی که در اثر پنهانسازی متدهای کلاس پایه پدید میآید، و نیز ”مشکل بُرش“ چه هستند
فرض کنید
شخصی به نام تام اسمیت (Tom Smith)
وجود دارد. چیزی که این شخص در وحله نخست از نیاکان خود به ارث میبرد، و او را به
یک اسمیت تبدیل میکند، نام خانوادگی او است. بعلاوه او برخی از ارزشهایی که
والدینش به او آموزش دادهاند، و نیز مجسمه سازی را که برای نسلها شغل خانوادگی
آنها بوده، از اجدادش به ارث میبرد. این خصایص روی هم رفته ” تام“ را بعنوان یکی
از اعضای شجرهنامه اسمیت مشخص میکند.
از لحاظ برنامهنویسی، شما اغلب با مؤلفههایی سر
وکار دارید که شباهتهای زیاد، و تفاوتهای اندکی، باهم دارند. یک راه برای حل این
مسئله این است که هر مؤلفه را بعنوان یک کلاس تعریف کنید، که در آن کلیه خصیصهها
تعریف میشوند، حتی آنهایی که در بقیه کلاسها هم وجود دارند. روش دیگر استفاده از
وراثت است
که اجازه میدهد کلاسهایی که شباهت زیادی به هم دارند از یک کلاس پایه (base class) که خصوصیات مشترکی را تعریف میکند منشعب شوند (derive).
در وراثت این امکان نیز وجود دارد که آن دسته از خصوصیاتی که با کلاس پایه متفاوت
هستند را باطل کرد (override) و متناسب با کلاس
جدید دوباره آنها را تعریف کرد. باید گفت که غالباً استفاده از وراثت مقدمتر بر
روشهای مشابه است. به وراثت در جهان برنامهنویسی شیءگرا خوشآمدید.
شکل 10.1 وراثت میان کلاسها
در شکل
10.1، رابطه بین یک کلاس پایه و
کلاسهای منشعب از آن نشان داده شده است. در این مرحله ممکن است تصور این مسئله
دشوار باشد که یک کلاس پایه، و یا کلاسهای منشعب از آن چه میتواند باشند. برای
درک بهتر، سعی کنید تصور کنید که یک کلاس منشعب شده، کلاسی است که از کلاس پایه
ارث بری میکند، و از این نظر خودش نیز یک کلاس پایه است (مانند Tom که یک Smith است و میتواند فرزند نیز
داشته باشد).
در وراثت عمومی
بین یک کلاس منشعب و کلاس پایه، نوعی رابطه ”هستی“[10] وجود دارد، که فقط در مورد این نوع وراثت (وراثت
عمومی) صدق میکند. به منظور اینکه مفهوم وراثت را درک کنید، ما کار خود را با
وراثت عمومی آغاز میکنیم که متداولترین نوع وراثت است، و بعداً به وراثتهای
خصوصی و حفاظت شده میپردازیم.
برای
اینکه این مفهوم را آسانتر درک کنید، فرض کنید کلاسی به نام Bird (پرنده) وجود دارد. چند نمونه
از کلاسهایی که از Bird
منشعب میشوند عبارتند از کلاس Crow
(کلاغها)، کلاس Parrot
(طوطیها)، و کلاس Kiwi
(مرغ کیوی). بیشتر خصوصیات یک
پرنده، از قبیل پر داشتن، بال داشتن، تخم گذاشتن، و اینکه آیا میتواند پرواز کند
یا نه (که البته برای بیشترشان مثبت است)، در کلاس Bird تعریف میشود. کلاسهایی از
قبیل Crow، Parrot، یا Kiwi این خصوصیات را به ارث میبرند
و آنها را متناسب با خودشان تغییر میدهند (برای مثال، بدلیل اینکه مرغ کیوی نمیتواند
پرواز کند، در کلاس Kiwi
هیچگونه پیاده سازی برای مِتُد Fly()
صورت نمیگیرد). جدول 10.1 تعداد بیشتری از این چنین وراثتهایی را نشان میدهد.
جدول
10.1 مثالهایی از وراثت عمومی، که از جهان اطراف اقتباس شده
|
کلاس پایه |
نمونههایی از کلاسهای منشعب شده |
|
ماهیها |
ماهیقرمز، ماهی کَپور، ماهی تُن (تن یک نوع ماهی نیز هست) |
|
پستانداران |
انسان، فیل، شیر، پلاتيپوس[11] (پلاتيپوس یک پستاندار نیز هست) |
|
پرندگان |
کلاغ، طوطی، شترمرغ، کیوی، پلاتيپوس (پلاتيپوس یک پرنده نیز هست!) |
|
اشکال |
دایره، چندضلعی (دایره نیز یک شکل است) |
|
چندضلعیها |
مثلث، هشتضلعی (هشتضلعی یک چندضلعی است، و درنتیجه یک شکل) |
چیزی که این مثالها نشان میدهد این است که اگر از دید برنامهنویسی شیءگرا به چیزهای مختلف نگاه کنید، آنگاه متوجه
خواهید شد که وراثت در
همه اشیا اطراف شما دیده میشود. Fish
یک کلاس پایه برای
Tuna (ماهی تُن[12])
است، زیرا Tuna هم مانند Carp
(ماهیکپور) یک Fish
است و کلیه ویژگیهای یک ماهی، از قبیل خونسرد بودن، را دارا است. ولی ماهی تُن از
جهاتی، مثلاً شکل، طرز شنا کردن، و اینکه یک ماهی آبشور است با ماهی کپور تفاوت
دارد. بنابراین تُن و کپور خصوصیاتی را از یک کلاس پایه مشترک بنام ”ماهی“ به ارث
میبرند، با این حال، به منظور اینکه از هم متمایز باشند برخی از خصوصیات کلاس پایه را تغییر میدهند. این مورد در
شکل 10.2 نشان داده شده است.
شکل 10.2 ارتباط سلسلهمراتبی بین ماهی تُن، ماهی کَپور و ماهیها
یک
پلاتيپوس میتواند شنا کند، با اینحال جانور خاصی است که خصوصیات پستانداران را نیز دارد (چون به بچه خودش
شیر میدهد)، در عین حال نوعی پرنده نیز هست (زیرا تخمگذار است) و همینطور برخی
خصوصیات خزندهگان را هم دارا میباشد (مثلاً سمی است). بنابراین میتوان فرض کرد
که کلاس Platypus
از دو کلاس پایه ارث
برده، یکی از کلاس Mammal
(پستانداران) و دیگری از کلاس Bird
(پرندگان)، و همین باعث میشود تا هم خصوصیات پستانداران، و هم پرندگان، را داشته
باشد. اینگونه وراثت ”وراثت
چندگانه“ (multiple inheritance) نامیده میشود و بعداً در
همین درس به آن خواهیم پرداخت.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
حالا که
با اصول وراثت آشنا
شدید و توانستید سلسله مراثب وراثت را ایجاد کنید، و نیز فهمیدید که وراثت عمومی
اساساً یک رابطه ”هستی“ را مدلسازی میکند، وقت آن است که از آموختههای خود
استفاده کرده و هدف اصلی برنامهنویسی شیءگرا، که چندریختی یا پُلیمورفیسم (polymorphism)
است، را یاد بگیرید.
در این
درس شما یاد خواهید گرفت که:
§
اصولاً چندریختی چه معنای دارد
§
توابع مجازی چه هستند و چگونه
آنها را بکار میبریم
§
کلاسهای پایه مجرد چه هستند و
چگونه اعلان میشوند
§
معنی وراثت مجازی چیست و در چه مواردی بکار میرود
”پلی“ (poly)
در زبان یونانی به معنای ”چندتایی“ است، و ”مورف“ (morph)
به معنای ”شکل“ یا ”ریخت“ است. پلیمورفیسم (چندریختی) یکی از ویژگیهای زبانهای شیءگرا است که اجازه میدهد تا با اشیایی که از
گونههای متفاوتی هستند بطور یکسانی رفتار شود. این درس بر روی آندسته از رفتارهای
چندریختی تمرکز میکند که میتوانند در زبان C++ توسط وراثت تعریف شوند، و به آنها چندریختی زیرگونه (subtype polymorphism)
گفته میشود.
در درس 10
شما دیدید که کلاسهای Tuna
و Carp متد Swim() را بصورت عمومی از
کلاس Fish به ارث بردند (شکل
10.1). ولی از سوی دیگر این امکان برای Tuna و Carp وجود دارد که بتوانند نسخه خودشان از متد Swim() را ارائه دهند، تا مشخص کنند
که ماهی تُن و ماهی کپور بصورت متفاوتی شنا میکنند. با اینحال هر یک از اینها یک Fish نیز هستند، و اگر کاربر نسخهای
از Tuna را در دست داشته باشد
و از گونه کلاس پایه برای
فراخوانی Fish::Swim()
استفاده کند، گرچه نمونه کلاس پایه Fish
هم بخشی از Tuna
است، ولی او نهایتاً Fish::Swim()
را اجراء خواهد کرد و نه Tuna::Swim()
. این مسئله در لیست 11.1 نشان داده شده است.
کلیه مثالهایی که در این درس مطرح میشود
مخصوصاً طوری طرح ریزی شدهاند که نشان دهنده موضوع مورد بحث باشند، و برای اینکه
بهتر خوانده شوند، تا آنجا که امکان داشته
از تعداد خطوط آنها کاسته شده است.
هنگامی که شما برنامهای مینویسید، باید
کلاس خود را با ایجاد سلسهمراتب وراثت طوری برنامه ریزی کنید که ملموس باشد، و
همچنین کاربردهای آتی برنامه را نیز درنظر داشته باشید.
0: #include
<iostream>
1: using
namespace std;
2:
3: class Fish
4: {
5: public:
6: void Swim()
7: {
8: cout << “Fish swims!” << endl;
9: }
10: };
11:
12: class Tuna:public Fish
13: {
14: public:
15: // Fish::Swim تعریف مجدد
16: void Swim()
17: {
18: cout << “Tuna swims!” << endl;
19: }
20: };
21:
22: void MakeFishSwim(Fish& InputFish)
23: {
24: // Fish::Swim فراخوانی
25: InputFish.Swim();
26: }
27:
28: int main()
29: {
30: Tuna myDinner;
31:
32: // Tuna::Swim فراخوانی
33: myDinner.Swim();
34:
35: // Fish بعنوان Tuna فرستادن یک
36: MakeFishSwim(myDinner);
37:
38: return 0;
39: }
خروجی برنامه▼
Tuna swims!
Fish swims!
تحلیل برنامه▼
همانطور
که در خط 12 برنامه دیده میشود، کلاس Tuna با استفاده از وراثت عمومی، کلاس Fish را ویژهسازی[13] (specialize)
میکند. این کلاس همچنین متد Fish::Swim()
را هم مجدداً تعریف میکند. در خط 33 تابع main() یک فراخوانی مستقیم به Tuna::Swim() صورت میگیرد
و سپس myDinner
(که از گونه Tuna
است) را به MakeFishSwim()
میفرستد، و همانطور که در خط 22 دیده میشود، این تابع آن را بعنوان ارجاعی به
گونه Fish تعبیر میکند. به
عبارت دیگر
برای تابع MakeFishSwim(&Fish)
تفاوتی نمیکند که آن شیئی که برای آن فرستاده شده از نوع Tuna باشد، او این پارامتر را
بعنوان Fish فرض میکند و Fish::Swim را فراخوانی میکند.
بنابراین دومین خط خروجی حاکی از این است که شیئی که از نوع Tuna بوده، همان خروجی را تولید
کرده که Fish میکند و از این جهت
هیچگونه ویژهسازی خاصی انجام نشده (این اتفاق میتوانست برای گونه Carp هم رویدهد).
چیزی که
کاربر بصوت مطلوب انتظار دارد این است که یک شیء از گونه Tuna، حتی اگر متد Fish::Swim() بر روی آن فراخوانده
شود، درست مانند یک ماهی تُن رفتار کند. به عبارت دیگر وقتی InputFish.Swim() در خط 25 فراخوانده
میشود، او انتظار دارد که Tuna::Swim()
فراخوانی شود. چنین رفتار چندریختی، که در آن شیئی از یک کلاس شناخته شده (Fish)، بتواند درست مانند کلاس
واقعی خود (Tuna)
رفتار کند، میتواند با تعریف متد Fish::Swim()
بعنوان یک تابع مجازی انجام
گیرد.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
کلیدواژه class نه فقط شما را قادر میکند تا دادهها و متدها را با هم بستهبندی کنید، بلکه اجازه میدهد در کلاس عملگرهایی
را تعریف کنید که بر روی اشیاء این کلاس عمل کنند. درست به همانگونه که عملیاتی
نظیر واگذاری و یا جمع را با اعداد و متغیرهایی از گونه صحیح انجام میدهید، شما
میتوانید از عملگرها استفاده کرده و عملیات مشابهای را با اشیاء کلاس خود انجام
دهید. عملگرها نیز مانند توابع میتوانند سربارگزاری شوند.
در این
درس شما یاد خواهید گرفت که:
§
چگونه از کلیدواژه operator
استفاده کنید
§
عملگرهای یگانی و دوگانی چیستند
§
عملگرهای تبدیل چیستند
§
عملگر انتقال نسبتدهی در C++11 چیست
§
عملگرهایی که نمیتوان آنها را
بازتعریف کرد کدامها هستند
صرف نظر
از اینکه برای عملگرها از کلیدواژه operator استفاده میشود، از
لحاظ نحوی (syntactical) تفاوت اندکی بین یک
عملگر و
تابع وجود دارد. اعلان یک عملگر خیلی به اعلان تابع شباهت دارد:
گونه_بازگشتی operator نماد_عملگر(...فهرست
پارامترها...);
در این
حالت، نماد_عملگر میتواند
هر کدام از علامتهایی باشد که برنامهنویس اجازه تعریف آنها را دارد. برای نمونه،
این علامت میتواند + (جمع)، && (وی
منطقی) و غیره باشد. عملوندها به کامپایلر کمک میکنند که یک عملگر را از دیگری تشخیص دهد.
ولی چرا
درحالی که C++
از توابع پشتیبانی میکند، از عملگرها نیز پشتیبانی میکند؟
برای پاسخ
به سئوال فوق، یک کلاس تسهیلاتی (utility) بنام Date را درنظر بگیرید که روز، ماه،
و سال را در خودش بستهبندی کرده:
Date Holiday (25, 12, 2011); //مقدار 25 دسامبر 2011 داده شده است Holiday به
حالا اگر
شما بخواهید این متغیر به روز بعد (یعنی 26 دسامبر 2011) اشاره کند، در اینصورت
کدام یک از دو روش زیر راحتتر خواهد بود:
§
روش اول (استفاده از عملگرها):
++ Holiday;
§
روش دوم (استفاد از یک تابع):
Holiday.Increment(); // 26th Dec 2011
واضح است
که خیلیها ترجیح میدهند بجای استفاده از متد Increment() از روش
اول استفاده کنند. روشی که بر پایه عملگر بنا شده هم مختصرتر است و هم ملموستر. تعریف عملگر < (کوچکتر) برای کلاس Date، باعث میشود بتوانیم دو
تاریخ را بصورت زیر با هم مقایسه کنیم:
if(Date1 < Date2)
{
// اینکار را انجام بده
}
else
{
// کار دیگری انجام بده
}
کاربرد عملگرها فراتر از چیزهایی مثل ساماندهی تاریخها است. فرض کنید برای کلاسی مانند MyString یک عملگر جمع (+) تعریف شده (به لیست 9.9 رجوع کنید) که شما با استفاده از آن بسادگی میتوانید رشتههای حرفی را به هم الحاق کنید (concatenation):
MyString sayHello (“Hello “);
MyString sayWorld (“world”);
MyString sumThem (sayHello + sayWorld); // چنین چیزی در لیست 9.9 امکان نداشت
فایده تلاش اضافی که شما برای تعریف عملگرها انجام میدهید این است که باعث میشود استفاده از کلاسهایتان سادهتر، و برنامه شما نیز خواناتر شود.
بطور کلی عملگرها در C++ میتوانند به دو نوع تقسیم بندی شوند: عملگرهای یگانی (unary operators)، و عملگرهای دوگانی (binary operators).
همانگونه
که از نام آنها پیداست، عملگرهای یگانی آنهایی هستند که تنها بر روی یک عملوند اعمال میشوند. معمولاً تعریف یک عملگر یگانه با استفاده از یک تابع سراسری (global) و یا یک تابع عضو انجام میشود:
گونه_بازگشتی عملگر گونه_عملگر(گونه_پارامتر)
{
//
... تعریف
}
یک عملگر یگانی که عضوی از یک کلاس است بصورت زیر تعریف میشود:
گونه_بازگشتی عملگر گونه_عملگر()
{
// ... تعریف
}
آن دسته از عملگرهای یگانی که میتوانند سربارگزاری (یا بازتعریف) شوند در جدول 12.1 نشان داده شده است.
|
عملگر |
نام |
|
++ |
افزایش |
|
-- |
کاهش |
|
* |
ارجاعزدایی اشارهگر |
|
-> |
انتخاب عضو |
|
! |
نقیض منطقی |
|
& |
آدرس |
|
~ |
مکمل یک |
|
+ |
مثبتسازی یگانه |
|
- |
منفیسازی یگانه |
|
عملگرهای تبدیل |
عملگرهای تبدیل |
یک عملگر افزایش پیشوندی (++) را میتوان بصورت زیر در داخل اعلان
کلاس تعریف کرد:
Date& operator ++ ()
{
// دستورات مربوط به تعریف
عملگر
return *this;
}
یک عملگر افزایش پَسوندی (++) را میتوان بصورت زیر در داخل اعلان کلاس تعریف کرد:
Date& operator ++ (int)
{
// ذخیره یک کپی از حالت فعلی شیء
پیش از افزایش روز
Date
Copy (*this);
// دستورات مربوط به تعریف عملگر (که این شیء را افزایش میدهد)
// بازگرداندن حالت پیش از اینکه افزایش انجام شود
return Copy;
}
عملگرهای کاهش پیشوندی و پَسوندی نحوه تعریف مشابهای با عملگرهای افزایش پیشوندی و پسوندی دارند، تنها تفاوت آنها این است که در عملگرهای کاهشی بجای ++ ، از -- استفاده میشود. در لیست 12.1 یک کلاس ساده بنام Date، نشان داده شده که اجازه میدهد تاریخها را با استفاده از عملگر (++) افزایش داد.
لیست 12.1 یک کلاس تقویم ساده که روز، ماه، و سال را
در خود نگاه میدارد، و همچنین اجازه میدهد تا با عملگرهای افزایشی و کاهشی، 1 روز
را به یک تاریخ اضافه کنیم و یا از آن کم کنیم
0: #include <iostream>
1: using namespace std;
2:
3: class Date
4: {
5: private:
6: int Day; // محدوده: 1 – 30 (با فرض براینکه همه ماهها 30 روز دارند!)
7: int Month;
8: int Year;
9:
10: public:
11: // سازنده که شیئی را ساخته و روز، ماه، و سال را در آن قرار میدهد
12: Date (int InputDay, int InputMonth, int InputYear)
13: : Day (InputDay), Month (InputMonth), Year (InputYear) {};
14:
15: // عملگر یگانه افزایش (پیشوندی)
16: Date& operator ++ ()
17: {
18: ++Day;
19: return *this;
20: }
21:
22: // عملگر یگانه کاهش (پیشوندی)
23: Date& operator -- ()
24: {
25: --Day;
26: return *this;
27: }
28:
29: void DisplayDate ()
30: {
31: cout << Day << “ / “ << Month << “ / “ << Year << endl;
32: }
33: };
34:
35: int main ()
36: {
37: //به 25 دسامبر سال 2011 Dateساختن و مقدار دهی شیئی از کلاس
38: Date Holiday (25, 12, 2011);
39:
40: cout << “The date object is initialized to: “;
41: Holiday.DisplayDate ();
42:
43: // اعمال عملگر افزایش پیشوندی
44: ++ Holiday;
45:
46: cout << “Date after prefix-increment is: “;
47:
48: // نمایش تاریخ بعد از افزایش آن
49: Holiday.DisplayDate ();
50:
51: -- Holiday;
52: -- Holiday;
53:
54: cout << “Date after two prefix-decrements is: “;
55: Holiday.DisplayDate ();
56:
57: return 0;
58: }
خروجی برنامه▼
The date object is initialized to: 25 / 12 / 2011
Date after prefix-increment is: 26 / 12 / 2011
Date after two prefix-decrements is: 24 / 12 / 2011
تحلیل برنامه▼
عملگرهای
مورد نظر در خطوط 16 تا 27 قرار دارند، و کمک میکنند تا اشیا کلاس Date
به مقدار یک روز افزایش یا کاهش پیدا
کنند ( خطوط 44، 51 و 52 در تابع main()). عملگرهای افزایشی
پیشوندی آنهایی
هستند که اول عمل افزایش را انجام میدهند و یک ارجاع به همان شیء بازمیگردانند.
به منظور اینکه از تعداد خطوط برنامه کاسته
شود و فقط بر روی چگونگی تعریف عملگرها تمرکز کنیم، این نسخه از کلاس Date بصورت حداقلی تعریف شده. در
این راه من فرض را بر این گذاشتهام که همه ماهها دارای 30 روز هستند، همینطور پس
از انجام کاهش یا افزایش، موارد مربوط به تنظیم ماه یا سال را پیادهسازی نکردهام.
برای تعریف عملگرهای پسوندی، کافی است که کد زیر را به کلاس Date اضافه کنید:
// عملگر افزایش
پسوندی
Date& operator ++ (int)
{
// ذخیره یک کپی از
حالت فعلی شیء پیش از افزایش یک روز
Date Copy (Day, Month, Year);
++Day;
// بازگرداندن حالت پیش از انجام عمل افزایش
return Copy;
}
// عملگر کاهش پسوندی
Date& operator -- (int)
{
Date Copy (Day, Month, Year);
--Day;
return Copy;
}
وقتی کلاس شما هم از عملگرهای پیشوندی پشتیبانی کرد و هم از پسوندی، در آن صورت شما قادر خواهید بود تا بنحو زیر از اشیاء کلاس Date استفاده کنید:
Date Holiday (25, 12, 2011); // نمونهسازی و مقدار دهی
++ Holiday;
// استفاده از عملگر ++
پیشوندی
Holiday ++; // استفاده از عملگر ++ پسوندی
— Holiday; //
استفاده از عملگر –-
پیشوندی
Holiday —; // استفاده از عملگر -- پسوندی
همانگونه که در تعریف عملگرهای پسوندی دیده
می شود، قبل از این که عمل کاهش یا افزایش صورت گیرد، یک کپی از وضعیت فعلی شیء گرفته میشود.
به عبارت دیگر،
اگر شما انتخاب این را داشته باشید که فقط برای افزایش دادن شیء از میان
++ object;
object ++;
یکی را انتخاب کنید، شما باید اولی را انتخاب
کنید، تا با جلوگیری از ایجاد یک کپی موقتی، عملکرد برنامه را سریعتر کنید.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
تبدیلِ گونه (type casting) مکانیزمی است که
توسط آن برنامهنویس میتواند تعبیری که کامپایلر از یک شیء دارد را بطور موقتی یا دائم تغییر
دهد. توجه داشته باشید که این به این معنی نیست که برنامهنویس خود شیء را تغییر
میدهد، بلکه فقط تعبیر آن را عوض میکند. عملگرهایی که تعبیر یک شیء را تغییر
میدهند، عملگرهای تبدیل گونه[14] نام دارند.
در این
درس شما یاد خواهید گرفت که:
§
چه نیازی به عملگرهای تبدیل
گونه وجود دارد
§
چرا
تبدیل گونه به سبک-C در میان برخی از برنامهنویسان
C++ خیلی طرفدار ندارد
§
چهار عملگر تبدیل گونه در
C++
§
مفهوم تبدیل بالارونده و
تبدیل پائینرونده
§
چرا عملگرهای تبدیل گونه C++ همه وقت طرفدار ندارد
در جهانی
که همه برنامههای C++
خوب نوشته شده باشند و بتوان گفت که ایمن-گونه (type-safe) و قوی-گونه (type-strong) هستند، آنگاه نه
نیازی به تبدیل گونه وجود دارد و نه عملگر تبدیل گونه. ولی ما در جهانی زندگی میکنیم که ماژولهای
برنامه توسط تعداد زیادی از افراد نوشته میشود که هر یک از ابزارهای گوناگونی
استفاده میکنند، و همه اینها نیاز دارند تا با هم کار کنند. برای این منظور، اغلب
لازم است به کامپایلر گفته
شود که از دادهها به طرق مختلفی تعبیر کند تا این امکان را فراهم آورد که برنامههای
مختلف به شکل درستی کار کنند.
اجازه
دهید تا یک مثال واقعی را برای شما ذکر کنم: گرچه برخی از کامپایلرهای C++ ممکن است بصورت بومی از گونه bool
پشتیبانی کنند، ولی بسیاری از توابع کتابخانهای که هنوز هم از آنها استفاده میشود
به زبان C نوشته شده، و به آن
شکلی که در C++
وجود دارد، ما در زبان C
گونه بولی نداریم. این کتابخانهها که برای کامپایلرهای زبان C ساخته شدهاند، مجبورند برای
دادههای بولی از اعداد صحیح استفاده کنند. بنابراین در چنین کامپایلرهایی یک گونه
بولی به صورت زیر تعریف میشود:
typedef unsigned short BOOL;
تابعی که
یک گونه بولی را بازگرداند بصورت زیر اعلان میشود:
BOOL IsX ();
حالا اگر
بخواهیم این کتابخانه را در برنامهای بکار ببریم که با استفاده از آخرین نسخههای
C++ نوشته شده باشد، باید
برنامهنویس راهی پیدا کند که گونه bool زبان C++ را به گونه BOOL زبان C تبدیل کند. روش انجام اینکار استفاده از تبدیل گونه
است:
bool bCPPResult = (bool)IsX (); // Cتبدیل گونه به سبک
در طول
تکامل زبان C++،
از سوی برخی از برنامهنویسان این نیاز احساس شده که باید عملگرها جدیدی برای
تبدیل گونه در C++
بوجود آید، و این باعث شده تا در میان آنها شکاف بوجود آید: یک دسته از آنها کسانی
هستند که هنوز هم از تبدیل گونه به سبک-C در برنامههای C++ استفاده میکند، و دسته دیگر
آنهایی هستند که به استفاده از کلیدواژههای مخصوص C++ روی آوردهاند. استدلال دسته
اول این است که کاربرد روشهای تبدیل گونه C++ مایه دردسرند، و برخی اوقات حتی عملکرد آنها با آنچه
انتظار میرود فرق میکند. دسته دوم که ظاهراً طرفدار استفاده خالص از C++ هستند، به نقایصی که در تبدیل
گونه به سبک-C
وجود دارد اشاره میکنند.
بدلیل
اینکه در دنیای برنامهنویسی هر دو این رویکردها وجود دارد، مناسب خواهد بود تا با
مطالعه این درس مزايا و کاستیهای هر یک از آنها بدانیم، و انتخاب را به خود شما واگذار
کنیم.
یکی از
چیزهایی که همیشه برنامه نویسان C++
به آن میبالند امنیت گونه (type safety) است. در واقع بیشتر
کامپایلرهای C++
حتی به شما اجازه نمیدهند که عملیاتی شبیه زیر را انجام دهید:
char* pszString = “Hello World!”;
int* pBuf = pszString; // error: cannot convert char*
to int*
... و حق
هم دارند!
با اینحال
کامپایلرهای C++
هنوز نیاز دارند تا با برنامههای قدیمی C سازگار باشند، و بهمین دلیل عباراتی مانند زیر را
مجاز میشمارند:
// یک مشکل را حل میکند، ولی مشکل
دیگری را بوجود میآورد
int* pBuf = (int*)pszString;
ولی تبدیل
گونههای سبک-C
در واقع کامپایلر را
مجبور میکنند که گونه مورد نظر را طوری تعبیر کند که دلخواه برنامهنویس است،
همان برنامهنویسی که بخود زحمت نداده تا فکر کند حتماً برای آن خطایی که کامپایلر
میدهد دلیل خوبی وجود دارد، و تنها کاری که میکند این است که از کار کامپایلر
جلوگیری کرده، و آن را به اطاعت وادار میکند. البته این رویکرد خیلی به مذاق
برنامهنویسان C++
خوش نمیآید، زیرا آنها فکر میکنند چنین روشهایی که به زور هر چیزی را به چیز
دیگری تبدیل میکند، باعث به خطر افتادن امنیت گونههای آنها خواهد شد.
با وجود
اینکه تبدیل گونه کاستیهای دارد، ولی از خود مفهوم تبدیل گونه نمیتوان صرف نظر
کرد. برای حل مشکلات مهم مربوط به سازگاری، تبدیل گونهها هم لازمند و هم معقول.
علاوهبراین، C++
تعدادی عملگر جدید
در اختیار برنامهنویس قرار میدهد که قبلاً در زبان C وجود نداشت.
چهار عملگر تبدیل گونه در C++ عبارتند از:
§ static_cast
§ dynamic_cast
§ reinterpret_cast
§ const_cast
نحوه
استفاده از هر یک از این عملگرها یکسان است:
گونه_نهایی
نتیجه = عملگر <گونه_نهایی> (شیئی_که_باید_تبدیل_شود);
static_cast ساز و کاری است که میتواند
اشارهگرها را به گونههای مرتبط تبدیل کند. این عملگر همچنین میتواند عمل تبدیل گونه را بطور
صریح برای گونههای استاندارد انجام دهد. تا آنجا که به اشارهگرها مربوط میشود static_cast در زمان-کامپایل
بررسی میکند آیا که اشارهگری که باید تبدیل شود حتماً به گونه مقصد مرتبط باشد.
چنین چیزی نسبت به تبدیلات سبک-C،
که اجازه میدهند یک اشارهگر بدون
اینکه اعتراضی کند به هر اشارهگر دیگری تبدیل شود، یک پیشرفت محسوب میشود. با
استفاده از static_cast
یک اشارهگر میتواند به کلاس پایه خود تبدیل شود، که در اینحالت به آن تبدیل بالارونده (upcasting)
میگویند، یا اینکه میتواند به گونه منشعب شده خودش تبدیل شود که در اینحالت تبدیل پایینرونده (downcasting) نامیده میشود. به
نمونههای زیر نگاه کنید.
Base* pBase = new Derived (); // ساخت یک شیء منشعب شده
Derived* pDerived = static_cast<Derived*>(pBase);
// ok!
//هیچ ارتباطی با سلسلهمراتب
وراثت ندارد CUnrelated در خط زیر
CUnrelated* pUnrelated =
static_cast<CUnrelated*>(pBase);// خطا
//تبدیل بالا مجاز نیست زیرا گونهها هیچ ارتباطی با یکدیگر ندارند
تبدیل اشارهگر از
کلاس منشعب به کلاس پایه، تبدیل بالارونده نامیده میشود و میتوان
آن را بدون نیاز به عملگرهای تبدیل گونه انجام داد:
Derived objDerived;
Base* pBase = &objDerived; // ok!
تبدیل اشارهگر از
کلاس پایه به کلاس منشعب، تبدیل پایینرونده نامیده میشود و نمیتواند
بدون ذکر عملگرهای تبدیل گونه انجام شود:
Derived objDerived;
// خط زیر مشکلی ندارد چون بالارونده
است
Base* pBase = &objDerived;
// خط زیر مجاز نیست چون تبدیل پایینروند
باید
// بصورت صریح با استفاده از عملگر انجام شود
Derived* pDerived = pBase;
ولی توجه داشته باشید که static_cast فقط بررسی میکند که اشارهگرها با یکدیگر مربوط باشند، و هیچ گونه بررسی دیگری در زمان اجرا صورت نمیگیرد. بنابراین اگر برنامه نویس از static_cast استفاده کند هنوز هم احتمال دارد برنامه او با اشکال روبرو شود، مثلاً:
Base* pBase = new Base ();
Derived* pDerived = static_cast<Derived*>(pBase);
//خطایی گرفته نمیشود
ولی
دراینجا pDerived
در حقیقت به بخشی از شیء Derived اشاره میکند، زیرا شیئی که به آن اشاره شده در واقع از گونه Base است. بدلیل اینکه static_cast فقط در زمان-کامپایل بررسیهای خود را انجام میدهد و نه در زمان اجرا، یک
فراخوانی که با
pDerived->SomeDerivedClassFunction()
انجام شود بدون مشکل کامپایل خواهد شد، ولی احتمالاً بعداً در زمان اجراء به نتایج
غیرقابل پیشبینی منجر خواهد شد.
گذشته از
اینکه static_cast
در انجام تبدیلبالارونده یا پایینرونده کمک میکند، ولی میتوان از آن برای جلب
توجه خوانندهای که کدهای برنامه را میخواند استفاده کرد تا نشان داده شود در
اینجا تبدیلی صورت گرفته، (تبدیلی که میتواند بدون ذکر هیچ عملگری بصورت ضمنی
انجام شود).
double dPi = 3.14159265;
// صریحاً به تبدیلی اشاره میکند که
میتواند بطور ضمنی انجام شود
int Num = static_cast<int>(dPi);
در خط سوم
کد بالا، اگر بنویسیم Num = dPi;
باز هم برنامه کار میکند و همان تاثیر را دارد. ولی استفاده از static_cast
باعث میشود تا توجه خواننده صریحاً به تبدیل گونه جلب شود.
همانطور
که از نام آن پیداست، تبدیل گونه پویا مخالف تبدیل گونه ایستا است و در واقع در
زماناجرای برنامه انجام میشود. چیزی که در مورد dynamic_cast جالب است این است که
میتوان نتیجه آن را بررسی کرد تا ببینیم آیا تبدیل با موفقیت انجام شده یا نه.
نحوه بکارگیری عملگر dynamic_cast بصورت زیر است:
destination_type* pDest = dynamic_cast
<class_type*> (pSource);
if (pDest) // بررسی موفقیت عمل تبدیل، قبل از بکارگیری اشارهگر
pDest->CallFunc ();
برای
نمونه:
Base* pBase = new Derived();
// انجام یک تبدیل پایینرونده
Derived* pDerived = dynamic_cast <Derived*>
(pBase);
if (pDerived) // بررسی موفقیت عمل تبدیل
pDerived->CallDerivedClassFunction ();
همانطور
که در مثال کوتاه بالا دیده میشود، پس از انجام تبدیل اشارهگر کلاس پایه، برنامهنویس با بررسی اشارهگر
میتواند تائید کند که آیا عمل تبدیل موفقیت آمیز بوده یا نه. توجه کنید در مثال فوق
روشن است که شیء نهایی از گونه Derived
است. بنابراین این مثال صرفاً جنبه نمایشی دارد. با اینحال، همیشه هم اینطور نیست.
برای نمونه هنگامی که اشارهگری از گونه Derived* به تابعی فرستاده میشود که گونه Base* را قبول میکند، تابع میتواند
از dynamic_cast
استفاده کند تا نوع گونه را مشخص کند و سپس بر اساس نتایج آن عملیاتی را انجام
دهد. بنابراین dynamic_cast میتواند در تشخیص گونه در
زمان اجرای برنامه مورد استفاده قرار گیرد و برای تعیین اینکه آیا بکارگیری اشارهگر تبدیل
شده بیخطر هست یا نه از آن استفاده کند. در لیست 13.1 از کلاسهای Tuna و Crap که با کلاس Fish ارتباط دارند، استفاده شده.
در این برنامه تابع DetectFishType()
بصورت پویا تعیین میکند که آیا یک شیء از نوع Fish*، Tuna* یا Crap* است.
این نوع مکانیزم که گونه اشیاء در زمان اجرای
برنامه تشخیص داده میشود [15]RTTIنامیده میشود.
لیست 13.1 استفاده از تبدیلِ گونهِ پویا برای تعیین گونه یک ماهی
0: #include
<iostream>
1: using
namespace std;
2:
3: class Fish
4: {
5: public:
6: virtual void Swim()
7: {
8: cout << “Fish swims in water” << endl;
9: }
10:
11: // base class should always have virtual destructor
12: virtual ~Fish() {}
13: };
14:
15: class Tuna: public Fish
16: {
17: public:
18: void Swim()
19: {
20: cout << “Tuna swims real fast in the sea” << endl;
21: }
22:
23: void BecomeDinner()
24: {
25: cout << “Tuna became dinner in Sushi” << endl;
26: }
27: };
28:
29: class Carp: public Fish
30: {
31: public:
32: void Swim()
33: {
34: cout << “Carp swims real slow in the lake” << endl;
35: }
36:
37: void Talk()
38: {
39: cout << “Carp talked crap” << endl;
40: }
41: };
42:
NOTE
43: void DetectFishType(Fish* InputFish)
44: {
45: Tuna* pIsTuna = dynamic_cast <Tuna*>(InputFish);
46: if (pIsTuna)
47: {
48: cout << “Detected Tuna. Making Tuna dinner: “ << endl;
49: pIsTuna->BecomeDinner(); // calling Tuna::BecomeDinner
50: }
51:
52: Carp* pIsCarp = dynamic_cast <Carp*>(InputFish);
53: if(pIsCarp)
54: {
55: cout << “Detected Carp. Making carp talk: “ << endl;
56: pIsCarp->Talk(); // calling Carp::Talk
57: }
58:
59: cout <<“Verifying type using virtual Fish::Swim: “ << endl;
60: InputFish->Swim(); // calling virtual function Swim
61: }
62:
63: int main()
64: {
65: Carp myLunch;
66: Tuna myDinner;
67:
68: DetectFishType(&myDinner);
69: cout << endl;
70: DetectFishType(&myLunch);
71:
72: return 0;
73:}
خروجی برنامه▼
Detected Tuna. Making Tuna dinner:
Tuna became dinner in Sushi
Verifying type using virtual Fish::Swim:
Tuna swims real fast in the sea
Detected Carp. Making carp talk:
Carp talked crap
Verifying type using virtual Fish::Swim:
Carp swims real slow in the lake
تحلیل برنامه▼
این همان
سلسله مراتب مربوط به Tuna
و Carp و Fish است که شما در درس 10 با آن
آشنا شدید. به منظور وضوح بیشتر، در اینجا دو کلاس منشعب شده نه فقط تابع مجازی Swim() را تعریف کردهاند،
بلکه هر یک از آنها حاوی توابعی هستند که به خودشان تعلق دارد، یعنی Tuna::BecomeDinner() و Carp::Talk(). چیزی که در این مثال
توجه را جلب میکند این است که با داشتن نمونهای از کلاس پایه Base*، شما قادرید بصورت
پویا مشخص کنید که آیا این اشارهگر به
یک Tuna اشاره میکند و یا یک
Carp. این تشخیص دهی گونه
بصورت پویا در تابع DetectFishType() رخ میدهد که در خطوط 43 تا 61 تعریف شده است. در خط 43 از dynamic_cast استفاده شده تا مشخص شود آیا اشارهگر پایه به یک Tuna* اشاره میکند یا نه. اگر این Fish* به یک Tuna* اشاره کند، عملگر یک آدرس معتبر را بازخواهد گرداند، در
غیراینصورت NULL
را بازمیگرداند. بنابراین نتیجه dynamic_cast همیشه باید از نظر
اعتبار بررسی شود. پس از اینکه در خط 46 صحت بررسی معلوم شد، شما مطمئن هستید که
اشارهگر pIsTuna
به یک Tuna اشاره میکند، و در
اینصورت میتوانید با فراخوانی تابع Tuna::BecomeDinner()
از آن استفاده کنید (خط 49). در مورد Carp
شما پس از بررسیهای لازم، تابع Carp::Talk()
را فراخوانی میکنید (خط 56). DetectFishType()قبل از بازگشت خود، با فراخوانی Fish::Swim() صحت عملیات انجام
گرفته را تائید میکند.
همیشه باید مقدار بازگشتی dynamic_cast
از نظر اعتبار مورد بررسی قرار گیرد. اگر این مقدار NULL باشد، دلیل بر شکست تبدیل
است.
در میان
عملگرهای تبدیل گونه در C++،
عملگر reinterpret_cast نسبت همه آنها به
تبدیلات سبک-C نزدیکتر است. صرف نظر از اینکه گونههای تبدیل شده با یکدیگر مرتبط هستند
یا نه، حقیقتاً این عملگر به برنامهنویس اجازه میدهد تا یک شیء از یک گونه را به
گونه دیگری تبدیل کند. بعبارتی، این عملگر باعث میشود تا گونههای نامرتبط بصورت
زیر به یکدیگر تبدیل شود:
Base * pBase = new Base ();
CUnrelated * pUnrelated =
reinterpret_cast<CUnrelated*>(pBase);
// هرچند که کد فوق کامپایل میشود،
ولی بکار بردن آن از نظر برنامهنویسی خوب نیست
در حقیقت reinterpret_cast کامپایلر را
وادار میکند تا کاری را انجام دهد که معمولا static_cast اجازه آن را نمیدهد.
این نوع تبدیل در برنامههای سطح-پایین، مثل برنامههای راهانداز (drivers) که نیاز دارند با
دادههایی کار کنند که از گونههای سادهای هستند، کاربرد دارد. برای نمونه، برخی
از APIها[16] فقط با گونه بایتی (که در حقیقت unsigned char*
است) کار میکنند.
SomeClass* pObject = new SomeClass ();
// نیاز به فرستادن شیء بصورت جریانی
از بایتها
unsigned char* pBytes = reinterpret_cast <unsigned
char*>(pObject);
تبدیل
بکار رفته در کد بالا شکل باینری شیء مبداء را تغییر نداده و بطور موثری کامپایلر را فریب داده تا برنامه نویس بتواند بایتهای
موجود در شیء pObject
را بدست آورد. بدلیل اینکه هیچ نوع عملگر تبدیل گونه دیگری در C++ وجود ندارد تا بتواند چنین
تبدیلی را انجام دهد، کاربرد reinterpret_cast موجب میشود تا
کامپایلر نسبت به ناامن بودن (و غیرقابلحمل[17] بودن) این نوع تبدیل به برنامه نویس هشدار
بدهد.
تا آنجا که امکان دارد باید از کاربرد reinterpret_cast در برنامههای خود پرهیز کنید، زیرا این عملگر اجازه میدهد شما
کامپایلر را مجبور کنید که مثلاً گونه X را مانند گونه Y در نظر
بگیرد، و این رویکرد خوبی در طراحی و پیادهسازی برنامهها بحساب نمیآید.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
تا اینجا
شما باید درک کاملی از اصول برنامهنویسی C++ پیدا کرده باشید و برنامههای نوشته شده بهC++ باید
برایتان قابل فهم باشند. در این مرحله، شما آمادگی دارید تا به مطالعه خصوصیاتی از
این زبان بپردازید که در جهت افزایش کارایی برنامه به شما کمک میکنند.
مطالبی که
در این درس مورد بررسی قرار میگیرند عبارتند از:
§
مقدمهای بر پیشپردازندهها
§
کلید واژه #define و
ماکروها
§
مقدمهای بر الگوها
§
چگونه توابع الگو بنویسیم
§
تفاوت بین ماکروها و الگوها
§
چگونه استفاده از static_assert
در C++11 میتواند به بررسیهای
زمان کامپایل کمک کند
شما
نخستین بار در درس دوم با پیشپردازنده آشنا شدید. همانطور که از نام آن پیداست،
پیشپردازنده چیزی است که پیش از آنکه عمل کامپایل شروع شود اجرا میگردد. به
عبارت دیگر
این پیشپردازنده است که بر اساس آنچه شما مشخص کردهاید تصمیم میگیرد که چه چیزی
کامپایل شود. دستورات پیشپردازده همیشه با علامت # شروع میشوند. برای مثال:
//در اینجا درج شود iostream پیش پردازنده زیر فرمان میدهد که محتوای فایل
#include
<iostream>
// پیش پردازنده زیر یک ثابت را بصورت
ماکرو تعریف میکند
#define
ARRAY_LENGTH 25
int MyNumbers[ARRAY_LENGTH]; // array of 25 integers
// پیش پردازنده زیر یک تابع را بشکل ماکرو تعریف میکند
#define SQUARE(x) ((x) * (x))
int TwentyFive = SQUARE(5);
ما در این درس عمدتاً بر روی دو نوع دستور پیشپردازنده، که در کدهای بالا مورد استفاده قرار گرفته، تکیه میکنیم؛ یکی از آنها استفاده از #define برای تعریف یک ثابت، و دیگری استفاده از #define برای تعریف یک تابع ماکرویی است. هر دو این دستورات، صرف نظر از اینکه چه نقشی را بازی میکنند، در واقع به پیشپردازنده دستور میدهند که در هرجایی که عبارت ARRAY_LENGTH و یا SQUARE آمده، آن را با عباراتی که تعیین شده جایگزین کند.
ماکروها نیز
به جایگزینی متن ارتباط دارند. پیشپردازنده جز اینکه موارد مشخص شده را با متن
دیگری جایگزین کند، هیچ کار هوشمندی دیگری انجام نمیدهد.
نحوه
استفاده از #define
برای تعریف یک ثابت بسیار ساده است:
#define شناسه مقدار
برای
مثال، ثابتی بنام ARRAY_LENGTH
بصورت زیر تعریف میشود:
#define
ARRAY_LENGTH 25
پس از
انجام پیشپردازش، در هر جایی که این شناسه (ARRAY_LENGTH) آمده با 25 جایگزین شده است:
int MyNumbers [ARRAY_LENGTH] = {0};
double Radiuses [ARRAY_LENGTH] = {0.0};
std::string Names [ARRAY_LENGTH];
پس از
اینکه پیشپردازنده کار خود را انجام داد، سه خط بالا از نظر کامپایلر به صورت زیر در خواهد آمد:
int MyNumbers [25] = {0};
double Radiuses [25] = {0.0};
std::string Names [25];
این
جایگزینی در تمام بخشهای برنامه شما انجام میشود، از جمله حلقههایی مانند زیر:
for(int Index = 0; Index < ARRAY_LENGTH; ++Index)
MyNumbers[Index] = Index;
کامپایلر این حلقه for را بشکل زیر میبیند
for(int Index = 0; Index < 25; ++Index)
MyNumbers[Index] = Index;
لیست 14.1
یک نمونه عملی از کاربرد ماکروها را نشان میدهد.
لیست 14.1 اعلان
ماکروها و استفاده از آنهابرای تعریف ثابتها
0: #include
<iostream>
1:
#include<string>
2: using
namespace std;
3:
4: #define ARRAY_LENGTH 25
5: #define PI 3.1416
6: #define MY_DOUBLE double
7: #define FAV_WHISKY “Jack Daniels”
8:
9: int main()
10: {
11: int MyNumbers [ARRAY_LENGTH] = {0};
12: cout << “Array’s length: “ << sizeof(MyNumbers) / sizeof(int) << endl;
13:
14: cout << “Enter a radius: “;
15: MY_DOUBLE Radius = 0;
16: cin >> Radius;
17: cout << “Area is: “ << PI * Radius * Radius << endl;
18:
19: string FavoriteWhisky (FAV_WHISKY);
20: cout << “My favorite drink is: “ << FAV_WHISKY << endl;
21:
22: return 0;
23: }
خروجی برنامه▼
Array’s length: 25
Enter a radius: 2.1569
Area is: 14.7154
My favorite drink is: Jack Daniels
تحلیل برنامه▼
ARRAY_LENGTH،
PI، MY_DOUBLE، FAV_WHISKY چهار ماکروی ثابتی
هستند که در خطوط 3 تا 7 تعریف شدهاند. همانگونه که میبینید اولی در خط 11 برای
تعریف طول یک آرایه بکار
رفته، که صحت کارکرد آن
در خط 12 با استفاده از عملگر sizeof() مورد تایید قرار گرفته است. در خط 15، برای اعلان
متغیری بنام Radius
که از گونه double
است، از MY_DOUBLE استفاده شده، و در خط 17 از PI برای محاسبه مساحت دایره
استفاده شده است. بالاخره در خط 19، برای مقدار دهی شیئی از کلاس std::string از FAV_WHISKY استفاده شده، که
مستقیماً در دستور cout
بکار گرفته شده. همه اینها نشان میدهند که تنها کاری که پیشپردازندهها انجام
میدهند این است که یک متن را با متن دیگری جایگزین کند.
این
جابجایی ”بیتفاوتِ“
متن، که بنظر میرسد در مواردی مثل لیست 14.1 کابرد دارد، دارای اشکالاتی نیز هست.
بدلیل اینکه متنها بشکل بیتفاوتی توسط پیشپردازنده
جایگزین میشوند، این باعث میشود شما خطاهایی را انجام دهید که به چشم نمیآید
(البته نهایتاً کامپایلر متوجه این اشکلات خواهد شد). مثلاً شما میتوانستید FAV_WHISKY در خط 7 را بصورت زیر تعریف کنید:
#define
FAV_WHISKY 42 // “Jack Daniels”
که اینکار باعث میشد کامپایلر برای قراردادن یک عدد صحیح در یک std::string از
شما خطا بگیرد (خط 19). ولی اگر خط 19 وجود نداشت هیچ مشکلی بوجود نمیآید و عبارت زیر چاپ میشود:
My favorite drink is: 42
البته چنین چیزی بیمعنی است، و مهمتر اینکه
اصلاً چنین خطایی پنهان میماند. بعلاوه، شما هیچ کنترلی بر روی ماکرویی که تعریف
کردهاید ندارید، مثلاً در مورد PI، مشخص نیست که آیا این عدد یک
double است و یا float. جواب این است که هیچکدام. از
نظر پیشپردازنده PI تنها یک متن است که با متن
”3.1416“ جایگزین شده. PI هرگز بعنوان یک گونهِ داده
مطرح نبوده است.
ثابتهایی که توسط کلیدواژه const تعریف میشوند برای گونهها
بهتر عمل میکنند. مثلاً، استفاده از عبارات زیر نسبت به موارد قبل بهتر است:
const int ARRAY_LENGTH = 25;
const double PI = 3.1416;
const char* FAV_WHISKY = “Jack Daniels”;
typedef double MY_DOUBLE; //برای نامیدن یک گونه typedef استفاده از
معمولاً
برنامهنویسان C++
کلاسها و توابع خود را در داخل فایلهایی اعلان میکنند که پسوند .h
دارند، و فایل سرآمد (header) نامیده میشوند.
پیادهسازی توابع
در داخل فایلهایی انجام میشوند که پسوند .cpp دارند، و با استفاده
از دستور پیشپردازش #include
، فایلهای سرآمد را در خود درج میکنند، یا بعبارتی آنها را شامل میشوند. اگر فایل سرآمدی بنام class1.h
داشته باشیم که شامل تعریف کلاس دیگری باشد که در فایل class2.h اعلان شده است، پس class1.h نیاز خواهد داشت که class2.h را در خود شامل کند.
اگر طراحی برنامه آنقدر پیچیده باشد که class2.h نیز به class1.h
نیاز داشته باشد، در نتیجه class2.h
نیز باید class1.h را در خود شامل کند!
ولی دو
فایل سرآمد که هر یک دیگری را شامل شود، برای پیشپردازنده مشکلی بوجود خواهد آورد
که ماهیتی تکراری یا بازگشتی (recursive) دارد. برای جلوگیری
از این مشکل شما میتوانید از ماکروهایی استفاده کنید که توسط دستورات پیشپردازش #ifndef و #endif
درست میشود.
برای
مثال، محتوای فایلی بنام header1.h
که شامل فایلی بنام header2.h
میشود بصورت زیر خواهد بود:
#ifndef
HEADER1_H _// جلوگیری در
برابر شمول تکراری
#define
HEADER1_H_ // پیشپردازنده
تنها یکبار این خط و خط بعدی را میخواند
#include
<header2.h>
class Class1
{
// اعلان اعضای کلاس
};
#endif // header1.h پایان فایل
فایل header2.h، که آن نیز لازم است فایل header1.h را در خود شامل کند، مشابه قبلی است ولی از نظر تعریف ماکر کمی با آن فرق میکند:
#ifndef HEADER2_H _// جلوگیری در برابر شمول تکراری
#define
HEADER2_H_ // پیش پردازنده
تنها یکبار این خط و خط بعدی را میخواند
#include
<header1.h>
class Class2
{
// اعلان اعضای کلاس
};
#endif // header2.h پایان فایل
شما میتوانید دستور #ifndef را این طور بخوانید: ”اگر تعریف نشده“. این یک دستور پردازش شرطی است که به پیشپردازنده فرمان میدهد فقط در صورتی خطوط بعدی را پردازش کند که علامت مشخصهای که در جلو آن قرار گرفته قبلاً تعریف شده باشد.
#endif
نقطه پایان این پردازش شرطی را برای پیشپردازنده مشخص میکند.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
اگر
بخواهیم ساده بگوییم، کتابخانه استاندارد الگو (یا STL[18])
مجموعهای از توابع و کلاسهای الگو است که موارد زیر را در اختیار برنامهنویس میگذارد:
§
گُنجانههایی برای مرتب کردن
اطلاعات
§
تکرار کنندههایی (iterator)
برای دستیابی به اطلاعات ذخیره شده
§
الگوریتمهایی برای تغییر
محتوای گُنجانهها
در این
درس شما با این سه اصل STL
آشنا میشوید.
گنجانههای[19] STL کلاسهایی هستند که برای ذخیره دادهها از آنها
استفاده میشود. STL
دو نوع کلاس گنجانه ارائه
میدهد:
§
گُنجانههای متوالی (Sequential containers)
§
گُنجانههای پیوندی (Associative containers)
علاوه بر
این دو مورد، STL
همچنین کلاسهایی بنام رابطهای
گنجانه (Container Adapters) را فراهم میکند که
انواع خاصی از گنجانههای متوالی و پیوندی هستند که از عملکرد آنها کاسته شده و برای
مقاصد خاصی از آنها استفاده میشود.
همانگونه
که از نام آنها پیداست، این نوع از گنجانهها دادههای خود را بشکل متوالی و پشت سر هم
ذخیره میکند. نمونه این نوع گنجانهها آرایهها و لیستها هستند. گنجانههای
متوالی دارای این خصوصیت هستند که درج اطلاعات در آنها سریع صورت میگیرد، ولی
عملیات جستجو در آنها نسبتاً کند است.
گنجانههای
متوالی STL شامل موارد زیر
هستند:
§
std::vector – که
مانند آرایهها عمل میکنند و از انتهای (=عقب) خود رشد میکنند. vector (بردار[20]) را همچون ردیفی در قفسه کتاب
در نظر بگیرید که میتوانید کتابهایی را به آخر آن اضافه کنید و یا بردارید.
§
std::deque – deque یا ”صف دو سر“ مشابه vector است، با این تفاوت که علاوه بر انتها، اجازه میدهد اعضایی به ابتدای آن
اضافه، یا از آن برداشته، شود.
§
std::list – مانند
یک لیست پیوندی-دوگانه (double linked list) عمل میکند. این
مورد را همچون زنجیری در نظر بگیرید که هر شیء مانند یک حلقه زنجیر است. شما میتوانید
در هر نقطه از این زنجیر که بخواهید حلقههایی را بردارید یا به آن اضافه کنید (در
اینجا منظور از حلقهها، همان اشیاء هستند.)
§
std::forward_list – مانند
std::list عمل میکند، با این
تفاوت که یک لیست پیوندی-یگانه است (singly-linked list) که تنها اجازه میدهد
تکرار (iterate) از یک جهت انجام
شود.
کلاس vector، یا بردار، از این
جهت که اجازه دستیابی تصادفی به اعضا را میدهد شباهت زیادی به آرایهها دارد. این
یعنی شما با استفاده از عملگر اندیس ([])،
میتوانید مستقیماً عضوی از بردار را مورد دستیابی قرار دهید و یا مقدار آن را
تغییر دهید. علاوهبراین، بردار یک آرایه پویا نیز
هست و درنتیجه میتواند متناسب با نیازهای برنامه اندازه خود را تغییر دهد. به
منظور اینکه بردار دارای خاصیت دستیابی تصادفی باشد و بتواند توسط یک اندیس مورد
دستیابی قرار گیرد، در بیشتر پیادهسازیهایی که از STL بعمل آمده، کلیه اعضا در مکانهایی
از حافظه قرار میگیرند که در مجاورت یکدیگر قرار دارند. بنابراین هنگامی که بردار
نیاز دارد تا اندازه خود را تغییر دهد، این اغلب باعث میشود تا از سرعت عملکرد
برنامه کاسته شود. شما در درس 4 بصورت مختصر با vector آشنا شدید. ما در درس 17 این
گنجانه را
بصورت مفصلتری مورد بررسی قرار خواهیم داد.
شما میتوانید
لیستهای STL را همچون لیستهای
پیوندی معمولی در نظر بگیرید. هر چند اعضای موجود در یک لیست نمیتوانند مانند vector بصورت تصادفی مورد
دستیابی قرار گیرند، ولی یک لیست میتواند بصورت غیرهمجوار در حافظه ذخیره شود.
بنابراین هنگامی که لازم باشد اندازه std::list
تغییر داده شود، مشکلات کاهش سرعت که vector
با آن روبرو است را نخواهد داشت. ما در درس 18 کلاس لیستهای STL را بصورت مفصل بررسی خواهیم
کرد.
گنجانههای
پیوندی گنجانههایی هستند
که دادهها را بصورت مرتب شده در خود نگاه میدارند، چیزی شبیه به یک فرهنگ لغت (dictionary). چنین خصوصیتی باعث
میشود تا عمل درج کندتر شود، ولی در مقابل مزیتهای فراوانی را برای عملیات جستجو
ارائه میکند.
گنجانههای پیوندی که توسط STL ارائه میشود موارد زیر
هستند:
§
std::set —
مقادیر یکتایی را در گنجانه ذخیره
میکند. این گنجانه در هنگام درج هر عضو جدید مرتب میشود، و عمل درج از پیچیدگی لگاریتمی (logarithmic complexity)
برخوردار است.
§
std::unordered_set — مقادیر یکتایی را در گنجانه ذخیره میکند، این گنجانه در هنگام درج هر
عضو جدید مرتب میشود، و عمل درج از پیچیدگی
تقریباً ثابت (near constant
complexity) برخوردار است. این گنجانه در نسخههای C++11 به بالا در دسترس
است.
§
std::map — جفتهایی
را بصورت کلید-مقدار در گنجانه ذخیره
میکند که بر پایه کلید یکتای آنها مرتب شدهاند. عمل درج از پیچیدگی لگاریتمی برخوردار است.
§
std::unordered_map— جفتهایی را بصورت کلید-مقدار در گنجانه ذخیره میکند که بر پایه کلید یکتای آنها
مرتب شدهاند. عمل درج از پیچیدگی تقریباً ثابت برخوردار است.
§
std::multiset — مشابه با set است. با این تفاوت که قادر است مقادیری را در
خود ذخیره کند که مقدار آنها یکتا نباشد و تکراری باشند.
§
std::unordered_multiset — مشابه unordered_set است، ولی میتواند مقادیری را در خود ذخیره
کند که مقدار آنها یکتا نباشد و تکراری باشند. این گنجانه در نسخههای C++11 به بالا در دسترس است.
§
std::multimap — مشابه map است، ولی میتواند مقادیری را در خود ذخیره کند که
کلید آنها
یکتا نباشد و تکراری باشند.
§
std::unordered_multimap — مشابه unordered_map است، ولی میتواند مقادیری را در خود ذخیره
کند که کلید آنها
یکتا نباشد و تکراری باشند. این گنجانه در نسخههای C++11 به بالا در دسترس است.
معیار
مرتب کردن گنجانههای STL
میتواند توسط یک تابع محمولی (predicate function) که برنامهنویس مشخص
میکند تغییر داده شود.
برخی از پیادهسازیهای STL شامل
گنجانههای پیوندی دیگری نیز هستند، مثلاً hash_set، hash_multiset، hash_map، و hash_multimap. چنین مواردی شباهت زیادی با گنجانههای نوع unordered
دارند که بصورت استاندارد توسط STL پشتیبانی میشود. انواع hash و unordered کاربردهای خود را دارند و هر
کدام (مستقل از تعداد اعضای موجود در گنجانه) میتواند عمل جستجو را در موارد
مختلف سریعتر انجام دهد. معمولاً این گنجانهها دارای متدهای عمومی یکسانی هستند
که مشابه انواع استاندار آنها است، و این باعث میشود تا کار کردن با آنها آسان
باشد.
استفاده از گنجانههای استاندارد باعث میشود
تا برنامه بر روی طیف وسیعی از کامپایلرها و سختافزارها قابل انتقال باشد، و از
این نظر نسبت به دیگر گنجانهها مرجح هستند. همچنین امکان این هست که کاهش لگاریتمی
سرعت در کاربرد گنجانههای استاندارد در برنامههای شما محسوس نباشد.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
کتابخانه استاندارد
الگو (STL) یک کلاس گنجانهای ارائه
میدهد که میتواند در انجام عملیات مربوط به تغییر و پردازش رشتهها به برنامهنویس
کمک کند. کلاس string نه تنها اندازه خود را بصورت پویا تغییر میدهد تا با نیازهای برنامه همساز
شود، بلکه تعدادی توابع کمکی در اختیار برنامهنویس قرار میدهد که میتوانند برای
دستکاری رشتهها مورد استفاده قرار گیرند. بنابراین استفاده از این کلاس باعث میشود
تا برنامهها بصورت استاندارد و قابل انتقال درآیند و برنامه نویس فقط بر روی
مسائل کلیدی تمرکز کند.
در این
درس شما یاد خواهید گرفت که:
§
چه لزومی برای استفاده از کلاسهای
رشتهای وجود دارد
§
چگونه از کلاس رشتهای STL استفاده کنیم
§
چگونه STL به شما
کمک میکند تا رشتههای را به یکدیگر الحاق کنید، و یا عملیات جستجو را بر روی آنها انجام دهید
§
چگونه از شکل الگویی کلاس string
استفاده کنید
در زبان C++، یک رشته از آرایهای از حروف تشکیل شده است. همانگونه که در درس 4 مشاهده کردید،
نمونهای از یک آرایه حرفی
ساده به این شکل است:
char staticName [20];
staticName
نام یک آرایه حرفی
(که رشته نیز نامیده میشود) است، که طول آن ثابت و شامل 20 حرف است (و به همین
دلیل، یک آرایه ایستا نامیده
میشود). همانطور که میبینید این بافر (staticName) میتواند رشتهای با طول محدودی را در خود نگاه دارد و
در صورتی که شما سعی کنید تا رشته بزرگتری را در آن ذخیره کنید لبریز خواهد شد.
تغییر اندازه این آرایه ایستا ممکن نیست. به منظور غلبه بر این محدودیت، C++ روشهایی را بدست میدهد که با
استفاده از آنها میتوان بصورت پویا فضایی از حافظه را به رشتهها اختصاص داد.
بنابراین، شکلی از این رشته حرفی که تاحدی پویاتر است بصورت زیر تعریف میشود:
char* dynamicName = new char [ArrayLength];
dynamicName
یک آرایه حرفی
است که بصورت پویا برای آن حافظه تخصیص یافته و میتواند به اندازهای که توسط ArrayLength، و در زمان اجرای
برنامه تعیین میشود، در آن حروفی را جای داد. بنابراین چنین آرایهای ثابت نیست و
طول آن وابسته به مقدار اولیه ArrayLength
است. ولی درصورتی که شما بخواهید طول آرایه را در زمان اجرا تغییر دهید، اول باید
حافظه تخصیص یافته به آن را آزاد کرده و دوباره به مقدار مورد نیاز به آن حافظهای
را تخصیص دهید.
هنگامی که
از رشتههای char
* بعنوان اعضای یک کلاس استفاده شود، مسائل پیچیدهتر
خواهند شد. در مواقعی که شیئی از این کلاس به شیء دیگری نسبت داده شود، در غیاب
وجود یک سازنده کپی و عملگر نسبت دهی برای این کلاس، هر دو شیء مبداء و
مقصد به یک بافر اشاره خواهند کرد. نتیجه این است که ما دو شیء خواهیم داشته که هر
دو به یک آدرس از حافظه اشاره میکنند. تخریب یکی از این اشیاء باعث میشود تا
اشارهگر دیگر
نامعتبر شود، و چنین چیزی احتمال سقوط برنامه را زیادتر میکند.
کلاسهای
رشتهای کلیه این مشکلات را برای شما حل میکنند. کلاس رشتهای STL، یعنی std::string و std::wstring، در موارد زیر به شما کمک میکنند:
§
سادهتر کردن ایجاد و تغییر
رشتهها.
§
مدیریت داخلی حافظه، که باعث
افزایش پایداری برنامه میشود.
§
در این کلاسها سازنده کپی و عملگر نسبت دهی پیادهسازی شدهاند، و این باعث میشود تا اگر از این
رشتهها بعنوان اعضای کلاسهای دیگر استفاده شود، آنها بدرستی کپی شوند.
§
در این کلاسها تعدادی توابع
کمکی تعریف شده که میتوانند برای عملیاتی مثل کپی کردن، کوتاه کردن (truncating)، جستجو و پاک کردن
مورد استفاده قرار گیرند.
§
عملگرهایی
در این کلاسها ارائه شده که
میتوانند دو رشته را با هم مقایسه کنند.
§
استفاده از این کلاسها باعث
میشود تا برنامهنویس بجای پرداخت به این نوع عملیات، توجه خود را به مسائل
مهمتری معطوف کند.
هم std::string
و هم std::wstring هر دو کلاسهایی هستند که از
ویژهسازی یک کلاس الگوی واحد، یعنی std::basic_string<T> ، بوجود آمدهاند. اگر ما
بجای T char را قرار دهیم std::string، و اگر wchar_t را قرار دهیم std::wstring حاصل میشود. از std::string برای رشتههای حرفی ساده که هر
حرف آن از یک بایت تشکیل شده، و از std::wstring برای رشتههای حرفی یونیکد،
که حروف آن از چند بایت تشکیل شده، استفاده میشود.
هنگانی که کار با یکی از این دو کلاس را یاد
گرفتید، شما میتوانید از همان روشها و متدها برای کار با دیگری نیز استفاده کنید.
شما بزودی
با برخی از توابع کمکی کلاس std::string آشنا خواهید شد.
مهمترین
کارهایی که با رشتهها انجام میشود عبارتند از:
§
کپی کردن آنها
§
الحاق (چسباندن) آنها به یکدیگر
§
یافتن
حروف و رشتههای دیگر در آنها
§
کوتاه کردن (بریدن) آنها
§
معکوس کردن ترتیب آنها، و
تبدیل حروف بزرگ/کوچک، که توسط الگوریتمهای موجود در STL انجام میشود
برای
استفاده از کلاس رشتهای STL
شما باید فایل سرآمد <string>
را در برنامه خود بگنجانید.
کلاس string سازندههای
سربارگزاری شده زیادی دارد و بنابراین میتواند به طرق مختلفی نمونهسازی و مقدار
دهی شود. برای مثال شما میتوانید بسادگی یک رشته لفظی ثابت را به یک شیء از کلاس std::string نسبت دهید:
const char* constCStyleString = “Hello String!”;
std::string strFromConst (constCStyleString);
و یا
std::string strFromConst = constCStyleString;
مورد قبلی
شباهت بسیاری به خط زیر دارد:
std::string str2 (“Hello String!”);
همانطور
که به وضوح دیده میشود، نمونه سازی یک شیء از کلاس string و مقدار دهی آن، نیازی به
مشخص کردن طول رشته و یا جزئیات مربوط به تخصیص حافظه ندارد، زیرا سازنده string اینکارها را بصورت
خودکار انجام میدهد.
بطور
مشابه میتوان از یک شیء string
برای نمونهسازی و مقداردهی به شیء دیگری از این کلاس استفاده کرد:
std::string str2Copy (str2);
همچنین
شما میتوانید به سازنده string
فرمان دهید تا تنها n حرف اول رشته داده شده را بعنوان مقدار قبول کند:
// ساختن یک رشته از روی رشته دیگر، که
تنها 5 حرف اول آن کپی میشود
std::string strPartialCopy (constCStyleString, 5);
شما
همچنین میتوانید نمونهای از یک string
ایجاد
کنید که حاوی تعداد معینی از یک حرف مشخص باشد:
//باشد ‘a’ایجاد و
مقدار دهی یک شیء رشتهای که حاوی 10 عدد حرف
std::string strRepeatChars (10, ‘a’);
در لیست 16.1 برخی از نمونهسازیهای متداول، و نیز
روشهای کپیکردن std::string
مورد بررسی قرار گرفتهاند.
لیست 16.1 نمونهسازی و روشهای کپی کردن در رشتههای STL
0: #include
<string>
1: #include
<iostream>
2:
3: int main
()
4: {
5: using namespace std;
6: const char* constCStyleString = “Hello String!”;
7: cout << “Constant string is: “ << constCStyleString << endl;
8:
9: std::string strFromConst (constCStyleString); // سازنده
10: cout << “strFromConst is: “ << strFromConst << endl;
11:
12: std::string str2 (“Hello String!”);
13: std::string str2Copy (str2);
14: cout << “str2Copy is: “ << str2Copy << endl;
15:
16: // مقدار دهی یک رشته با 5 حرف اول رشتهای دیگر
17: std::string strPartialCopy (constCStyleString, 5);
18: cout << “strPartialCopy is: “ << strPartialCopy << endl;
19:
20: // ‘a’ مقدار دهی یک رشته با 10 حرف
21: std::string strRepeatChars (10, ‘a’);
22: cout << “strRepeatChars is: “ << strRepeatChars << endl;
23:
24: return 0;
25: }
خروجی برنامه▼
Constant string is: Hello String!
strFromConst is: Hello String!
str2Copy is: Hello String!
strPartialCopy is: Hello
strRepeatChars is: aaaaaaaaaa
تحلیل برنامه▼
برنامه
فوق نشان میدهد که شما چگونه میتوانید یک شیء از کلاس string را نمونهسازی کرده و به طرق
مختلفی به آن مقدار اولیه بدهید. constCStyleString
یک رشته سبک-C است که در خط 6 مقداردهی میشود. خط 9 نشان میدهد که چگونه سازنده std::string کار ایجاد کپی از یک
رشته سبک-C را آسان میکند. خط
12 از یک رشته لفظی ثابت
کپی گرفته و آن را در یک رشته std::string
قرار میدهد، و خط 13 نشان میدهد که چگونه با استفاده از سازنده سربارگزاری شده
دیگر std::string
میتوانیم از یک شیء std::string
کپی گرفته و آن را در str2Copy
بگذاریم. خط 17 چگونگی کپی کردن بخشی از رشته را نشان میدهد، و خط 21 نشان میدهد که چگونه یک
رشته میتواند حاوی تعداد معینی از یک حرف تکراری باشد. این برنامه فقط یک نمونه
ساده است که چگونگی ایجاد std::string را توسط سازندههای کپی متعدد آن نشان میدهد، و همچنین برنامهنویس خواهد دید
که ایجاد رشتهها، کپی کردن آنها، و نمایش آنها با استفاده از std::string چقدر سادهتر خواهد شد.
اگر قرار بود تا شما از رشتههای سبک-C
برای ایجاد نمونه دیگری از آنها استفاده کنید، آنگاه خطوط 9 به بعد
در لیست 16.1 بصورت زیر در میآمد:
// برای ایجاد یک کپی ابتدا باید برای
آن فضا اختصاص داد
char * pszCopy = new char [strlen (constCStyleString) +
1];
strcpy (pszCopy, constCStyleString); // مرحله کپی کردن
// pszCopy آزادسازی حافظه با استفاده از
delete [] pszCopy;
همانگونه که میبینید نتیجه این است که بر تعداد خطوط برنامه اضافه شده و احتمال بروز خطا نیز بیشتر میشود، و شما باید به فکر مدیریت حافظه و آزادسازی آن نیز باشید. رشتههای STL همه اینکارها، و کارهای زیاد دیگری را برای شما انجام میدهند!
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
بر خلاف آرایههای
ایستا، آرایههای پویا بدون اینکه نیاز داشته باشند تا حجم دقیق دادهها را
بدانند، برای ذخیره آنها قابلیت انعطاف زیادی را در اختیار برنامهنویس قرار میدهند.
طبیعتاً خیلی از اوقات به آرایههای پویا نیاز پیدا میشود و STL نیز برای آن کلاس std::vector ارائه داده که برنامهنویس
میتواند از آن استفاده کند.
در این
درس شما یاد خواهید گرفت که:
§
خصوصیات کلاس std::vector چیست
§
عملیات معمولی std::vector کدامها هستند
§
مفهوم اندازه و ظرفیت یک vector
§ کلاس
deque در STL
vector[21]، یا بردار، یک کلاس الگو است
که قابلیتهای کلی آرایههای پویا را به برنامهنویس ارائه میدهد و دارای خصوصیات زیر است:
§
اضافه کردن عضو جدید به انتهای
آرایه در
زمان ثابتی انجام میشود، که یعنی درج در انتهای آرایه به اندازه آن بستگی ندارد.
این مسئله در مورد حذف یک عضو از انتهای آرایه نیز صدق میکند.
§
زمان لازم برای درج و یا حذف
یک عضو جدید در وسط آرایه مستقیماً
به تعداد اعضایی که در پشت عضو حذف شده قرار میگیرند بستگی دارد.
§
تعداد اعضایی که در یک بردار قرار دارند میتواند بصورت پویا تغییر کند
و کلاس vector وظیفه مدیریت حافظه را بر عهده دارد.
بردار یک
آرایه پویا است که میتوان آن را به شکلی که در زیر
نشان داده شده تجسم کرد:

شکل 17.1 درون یک vector
برای استفاده از کلاس vector شما باید فایل سرآمد زیر را در برنامه خود بگنجانید:
#include <vector>
خصوصیات رفتاری و اعضا عمومی کلاس std::vector با استانداردهای C++ تعریف میشوند.
درنتیجه، عملیات مربوط به بردارها (یا همان vector) که شما در این درس یاد خواهید
گرفت توسط کامپایلرهای گوناگون پیشتیبانی میشود.
یک بردار یک کلاس الگو است، بنابراین برای نمونهسازی آن لازم است
کلیه تکنیکهایی که برای نمونهسازی کلاسهای الگو با آنها آشنا شدید بکارگرفته شود.
برای نمونهسازی از یک بردار لازم است تا شما گونه اشیایی که قرار است در آرایه پویا ذخیره شوند را مشخص کنید.
std::vector<int>vecDynamicIntegerArray;// حاوی اعداد صحیح
برداری
std::vector<float>vecDynamicFloatArray;//
حاوی اعداد اعشاری برداری
std::vector<Tuna> vecDynamicTunaArray;// حاوی ماهیهای تـُن برداری
برای
اعلان یک تکرارکننده که به عضوی از لیست اشاره کند شما باید به نحو زیر عمل کنید:
std::list<int>::const_iterator iElementInSet;
درصورتی
که به تکرارکنندهای نیاز دارید که بتواند مقادیری را تغییر دهد و یا توابع
غیر-ثابتی را فراخوانی کند، شما بجای const_iterator،
باید از iterator
استفاده کنید.
با توجه
به اینکه std::vector
سازندههای سربارگزاری شده اندکی دارد، شما انتخاب این را دارید که تعداد اعضای
اولیه و مقادیر آنها را مشخص کنید، و یا اینکه میتوانید برای مقداردهی یک بردار،
از بخشی از یک بردار دیگر استفاده کنید.
در لیست 17.1 برخی از نمونهسازیهای کلاس vector نشان داده شده است.
لیست 17.1 اشکال
مختلف نمونهسازی std::vector : با مشخص کردن اندازه، مقدار اولیه، و یا کپی از نمونه دیگری از vector.
0: #include
<vector>
1:
2: int main
()
3: {
4: std::vector <int> vecIntegers;
5:
6: // که درابتدا دارای 10 عضو است (بعداً میتواند بزرگتر شود) vector نمونهسازی از یک
7: std::vector <int> vecWithTenElements (10);
8:
9: // که دارای 10 عضو است و به هریک از آنها مقدار 90 داده شده است بردار نمونهسازی از یک 90
10: std::vector <int> vecWithTenInitializedElements (10, 90);
11:
12: // و مقداردهی آن توسط دیگری بردار نمونهسازی از یک
13: std::vector <int> vecArrayCopy (vecWithTenInitializedElements);
14:
15: // بردار استفاده از تکرارکننده برای مقداردهی یک
16: std::vector <int> vecSomeElementsCopied ( vecWithTenElements.cbegin ()
17: , vecWithTenElements.cbegin () + 5 );
18:
19: return 0;
20: }
تحلیل برنامه▼
برنامه
فوق ویژهسازی الگویی
کلاس vector برای اعداد صحیح را
نمایش میدهد. به عبارت دیگر
این برنامه یک بردار از
اعداد صحیح را نمونهسازی میکند. این بردار که vecIntegers نامیده میشود، از سازنده پیشفرضی استفاده میکند که در حالتی که
اندازه اولیه گنجانه درست
معلوم نیست بسیار مفید است (یعنی شما نمیدانید که چه تعداد از اعداد صحیح باید در
آن نگاه داده شوند). در نمونهسازیهای دوم و سوم که در خطوط 10 و 13 دیده میشوند، برنامهنویس میداند به یک بردار نیاز دارد
که حداقل بتواند 10 عدد صحیح را در خود جای دهد. توجه کنید تعداد اعضایی که میتوانند
در این گنجانه جا داده شوند به 10 محدود نیست، بلکه این عدد تنها نشان دهنده
انداره اولیه آن است. چهارمین شکل نمونهسازی که در خطوط 16 و 17 دیده میشود، از
یک بردار دیگر برای مقداردهی بردار فعلی استفاده میکند، به عبارت دیگر برداری
ایجاد میشود که کپی دیگری، یا کپی بخشی از آن، است. از چنین سازهای میتوان برای
نمونهسازی کلیه گنجانههای STL
استفاده کرد. در این فرم از نمونهسازی، از تکرارکنندهها استفاده شده است. vecSomeElementsCopied حاوی 5 عضو اول vecWithTenElements است.
از چهارمین شکل نمونهسازی تنها وقتی میتوان
استفاده کرد که گونه دو شیء مبداء و مقصد یکسان باشد. بنابراین شما تنها میتوانید
از vecArrayCopy برای نمونهسازی یک بردار از اعداد صحیح استفاده کنید. اگر گونه
یکی از آنها متفاوت باشد (مثلا برداری از float باشد)، برنامه کامپایل نمیشود.
آیا شما در کامپایل برنامه فوق برای کاربرد cbegin() و cend() با خطا مواجه میشوید؟
درصورتی که شما این برنامه را با کامپایلرهای
قدیمی که با C++11 سازگار نیستند کامپایل کنید
با خطا مواجه میشوید. در اینصورت به جای آنها از begin() و end() استفاده کنید.
cbegin() و cend() کمی از begin() و end() متفاوتتر (و بهتر) هستند ولی توسط کامپایلرهای قدیمی پشتیبانی
نمیشوند.
واضح است
که قدم بعدی پس از ایجاد یک بردار، درج عضوهای جدید در آن است. عمل درج در یک
بردار، از سوی عقب[22] آن صورت میگیرد، و اعضا توسط تابع push_back() به سمت عقب ”کشیده“
میشوند:
vector <int> vecIntegers; // اعلان یک بردار از اعداد صحیح
// درج اعضای جدید در بردار
vecIntegers.push_back (50);
vecIntegers.push_back (1);
لیست 17.2 استفاده از push_back() برای درج اعضای جدید در یک std::vector ، که بصورت پویا انجام میگیرد، را نشان میدهد.
لیست 17.2 استفاده
از push_back() برای درج اعضای جدید در یک بردار
0: #include
<iostream>
1: #include
<vector>
2: using namespace std;
3:
4: int main ()
5: {
6: vector <int> vecIntegers;
7:
8: // vector درج اعداد صحیح در
9: vecIntegers.push_back (50);
10: vecIntegers.push_back (1);
11: vecIntegers.push_back (987);
12: vecIntegers.push_back (1001);
13:
14: cout << “The vector contains “;
15: cout << vecIntegers.size () << “ Elements” << endl;
16:
17: return 0;
18: }
خروجی برنامه▼
The vector contains 4 Elements
تحلیل برنامه▼
همانگونه که در خطوط 12-9 برنامه دیده میشود، push_back() یکی از
متدهای عضو کلاس vector
است که اشیاء را در انتهای آرایه پویا درج میکند. به کاربرد تابع size() دقت کنید که
تعداد اعضای نگاه داشته شده در بردار را بازمیگرداند.
C++ 11
لیستهای مقداردهی
C++ 11 از طریق کلاس std::initialize_list<> از لیستهای مقداردهی پشتیبانی
میکند. این ویژگی شما را قادر میکند تا اعضای یک vector را به شکلی که به آرایههای ایستا شباهت دارد مقداردهی کنید:
vector<int> vecIntegers = {50, 1, 987, 1001};
// یا بصورت دیگر
vector<int> vecMoreIntegers {50, 1, 987, 1001};
چنین فرمی باعث میشود تا برنامهای که در
لیست 17.2 آمده بود 3 خط کوتاهتر شود. با اینحال، به دلیل اینکه هنوز بسیاری از
کامپایلرها از آن پشتیبانی نمیکنند ما در اینجا از کاربرد آن خودداری کردیم.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
کتابخانه
استاندارد الگو (STL)، کلاس std::list را در اختیار برنامهنویس
قرار میدهد که در حقیقت پیادهسازی لیستهای
دوپیوندی (Doubly
linked list) هستند. عمدهترین مزیت یک لیست پیوندی این است که درج
و حذف اعضا در زمان ثابتی انجام میگیرد. با شروع C++11، شما همچنین میتوانید از
لیستهای تکپیوندی، که در کلاس std::forward_list
پیادهسازی شده، استفاده کنید. این نوع لیستها تنها از یک جهت پیمایش میشوند.
در این
درس شما یاد خواهید گرفت که:
§
چگونه یک list و forward_list
را نمونهسازی کنید
§
چگونه عملیات درج و حذف را در
کلاسهای لیستی STL
انجام دهید
§
چگونه اعضا را معکوس کرده و
آنها را مرتب کنیم
یک لیست پیوندی گردایهای از گرهها (node)
است که هر گره، علاوه براینکه حاوی مقدار یا شیء مورد نظر است، به
گره بعدی در گردایه نیز
اشاره میکند؛ این یعنی همانطور که در شکل 18.1 دیده میشود، هر گره با گره بعدی
و پیشین پیوند خورده است.

شکل 18.1 تجسم یک لیست دوپیوندی
پیادهسازی STL از لیستهای دوپیوندی در کلاس list اجازه میدهد تا عمل درج
اعضای جدید در ابتدا، انتها، و میان لیست، در زمان ثابتی انجام گیرد.
برای استفاده از کلاس list باید فایل سرآمد آن را در برنامه خود شامل کنید:
#include <list>
برای
استفاده از کلاس list
اول از همه باید فایل سرآمد آن،یعنی <list>، را در برنامه خود
شامل کنید. کلاس الگوی list
که در فضایاسمی std
قرار دارد یک پیادهسازی عام است. به همین دلیل قبل از اینکه بخواهید از
توابع عضو آن استفاده کنید باید بصورت الگویی نمونهای از آن را ایجاد کنید.
برای
نمونهسازی الگویی یک لیست لازم است تا گونه شیئی که باید در گردایه ذخیره شود را مشخص کنید. بنابرای نمونهسازی
یک لیست میتواند بشکل زیر باشد:
std::list<int> listIntegers; // لیستی حاوی اعداد صحیح
std::list<float> listFloats; // لیستی حاوی اعداد اعضاری
std::list<Tuna> listTunas; //
Tuna لیستی حاوی اشیایی از
گونه
برای
اعلان تکرارکنندهای که به یک عضو از list
اشاره میکند، شما باید بصورت زیر عمل کنید:
std::list<int>::const_iterator iElementInSet;
اگر به
تکرارکنندهای نیاز دارید که بتواند محتوای اعضای یک لیست را تغییر دهد و یا
بتواند اعضای غیر-ثابت آن را فراخوانی کند، شما باید بجای استفاده از const_iterator از iterator استفاده کنید.
با توجه
به اینکه پیادهسازی std::list،
سازندههای سربارگزاری شده زیادی را فراهم آورده، شما میتوانید لیستهایی را
بسازید که پس از ایجاد، مقادیری را که شما مشخص میکنید بعنوان مقدار اولیه در خود
داشته باشند. چگونگی این مسئله در لیست 18.1 نشان داده شده است.
لیست 18.1 اشکال مختلف ایجاد std::list، با مشخص کردن تعداد اعضا و
مقادیر اولیه آنها
0: #include
<list>
1: #include
<vector>
2:
3: int main
()
4: {
5: using namespace std;
6:
7: // ایجاد یک لیست خالی
8: list <int> listIntegers;
9:
10: // ایجاد لیستی از 10 عدد صحیح
11: list<int> listWith10Integers(10);
12:
13: // ایجاد لیستی از 4 عددصحیح که مقدار اولیه هر کدام از آنها 99 است
14: list<int> listWith4IntegerEach99 (4, 99);
15:
16: // ایجاد یک کپی از یک لیست موجود
17: list<int> listCopyAnother(listWith4IntegerEach99);
18:
19: // ایجاد برداری با 10 عضو از اعداد صحیح و با مقدار اولیه 2011
20: vector<int> vecIntegers(10, 2011);
21:
22: // ایجاد یک لیست با استفاده از مقادیر موجود در یک گنجانه دیگر
23: list<int> listContainsCopyOfAnother(vecIntegers.cbegin(),
24: vecIntegers.cend());
25:
26: return 0;
27: }
تحلیل برنامه▼
این
برنامه هیچ خروجی را تولید نمیکند و تنها سازندههای مختلف کلاس std::list را نشان میدهد. در
خط 8 شما یک لیست خالی را ایجاد کردهاید، در حالی که در خط 11 شما لیستی از 10 عدد
صحیح را ایجاد کردهاید. در خط 14 لیستی به نام listWith4IntegersEach99 ایجاد شده که حاوی 4
عدد صحیح است که به هر کدام از آنها مقدار اولیه 99 داده شده. خط 17 ایجاد یک کپیِ
دقیق از لیست دیگر را نشان میدهد. خطوط 24-20 عجیب و جالب هستند! در آنجا شما
برداری را ایجاد کردهاید که حاوی 10 عدد صحیح است، و هر کدام دارای مقدار 2011
هستند، و سپس در خط 23 اعضای این بردار توسط یک تکرار کننده ثابت (که توسط vector::cbegin() و vector::cend() بدست میآیند) به
داخل لیستی بنام listContainsCopyOfAnother
کپی شده است. لیست 18.1 همچنین نشان میدهد که چگونه تکرار کنندهها میتوانند برای
نمونهسازی گنجانههای مختلف از روی یکدیگر مورد استفاده قرار گیرند.
آیا در هنگام استفاده از cbegin و cend کامپایلر از شما خطا میگیرد؟
درصورتی که بخواهید برنامه فوق را با
کامپایلرهایی که با C++11 سازگار نیستند کامپایل کنید،
باید بجای cend و cbegin از end و begin استفاده کنید. cend و cbegin در کامپایلرهای سازگار با C++11 در
دسترس است و از این نظر که میتوانند تکرار کنندههای ثابتی را
بازگردانند مفید هستند.
با مقایسه لیست 18.1 با لیست 17.1 که به نمونهسازی بردارها مربوط بود، شما خواهید دید که شباهت قابل ملاحظهای میان این دو گنجانه از نظر نمونهسازی وجود دارد. همانطور که با گنجانههای دیگر STL آشنا میشوید، شما خواهید دید که این الگو تکرار میشود، و از این نظر کار با آنها سادهتر میشود.
مشابه با لیست
دوسر (deque)، درج در جلو (که بسته به تجسم شما به آن
بالا هم میگویند) با استفاده از متد push_front() انجام میگیرد. درج در عقب بوسیله متد push_back() انجام میشود. این دو مِتُد، تنها یک
پارامتر ورودی میگیرند، و آن هم مقداری است که باید در گنجانه درج شود:
listIntegers.push_back (-1);
listIntegers.push_front (2001);
لیست 18.2
تاثیر استفاده از این دو متد بر روی لیستی از اعداد صحیح را نشان میدهد.
لیست 18.2 درج اعضا در لیست با استفاده از متدهای push_front() و
push_back()
0: #include
<list>
1: #include
<iostream>
2: using namespace std;
3:
4: template <typename T>
5: void DisplayContents (const T& Input)
6: {
7: for (auto iElement = Input.cbegin()
8: ; iElement != Input.cend()
9: ; ++ iElement )
10: cout << *iElement << ‘ ‘;
11:
12: cout << endl;
13: }
14:
15: int main ()
16: {
17: std::list <int> listIntegers;
18:
19: listIntegers.push_front (10);
20: listIntegers.push_front (2011);
21: listIntegers.push_back (-1);
22: listIntegers.push_back (9999);
23:
24: DisplayContents(listIntegers);
25:
26: return 0;
27: }
خروجی برنامه▼
2011 10 -1 9999
تحلیل برنامه▼
خطوط
22-19 استفاده از push_front() و push_back()را نشان میدهد. مقادیری که بعنوان پارامتر
به تابع push_front()
داده میشوند پس از درج در فهرست، مکان نخست را در لیست به خود اختصاص میدهند،
درحالی که مقادیری که به push_back()
داده میشوند مکان آخر را به خود اختصاص میدهند. تابع عام DisplayContents محتوای لیست را
بترتیب نمایش میدهد، خروجی این تابع نشان میدهد که ترتیب آنها به صورتی که اول
وارد شدهاند نیست.
آیا در هنگام استفاده از auto کامپایلر از شما خطا میگیرد؟
درصورتی که بخواهید برنامه 18.2 را با
کامپایلرهایی که با C++11 سازگار نیستند کامپایل کنید،
باید بجای cend و cbegin
از end و begin
استفاده کنید. همچنین از کلید واژه auto نیز برای اعلان تکرار کنندهها استفاده نکنید.
در این مثال و مثالهای بعدی، بجای استفاده
از auto، شما باید صریحاً گونه
متغیرها را مشخص کنید.
بنابراین تعریف تابع DisplayContents برای کامپایلرهای قدیمی به شکل زیر خواهد بود:
template <typename T>
void DisplayContents (const T& Input)
{
for(T::const_iterator iElement=Input.begin()
; iElement != Input.end ()
; ++ iElement )
cout << *iElement << ‘ ‘;
cout << endl;
}
تابع DisplayContents() در لیست 18.2، شکل عامتر تابع DisplayVector() است که در لیست 17.6 آمده بود (به فهرست پارامترهای این دو توجه کنید). DisplayContents نه تنها میتواند برای نمایش مقادیر ذخیره شده در
بردارها مورد استفاده قرار گیرد، بلکه از آن میتوان برای بقیه گنجانهها نیز استفاده کرد.
شما میتوانید با دادن یک لیست و یا بردار به تابع DisplayContents آن را فراخوانی کنید.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
STL کلاسهای گنجانهای را در اختیار برنامهنویس قرار میدهد که میتوانند در
برنامههایی مورد استفاده قرار گیرند که غالباً در آنها به جستجوهای سریع نیاز
است. کلاسهای std::set
و std::multiset برای ذخیره مجموعهای از اعضای مرتب شده بکار میروند و به شما این امکان را
میدهند که عمل جستجوی یک عضو را در زمان لگاریتمی انجام دهید. همتاهای نامرتب
آنها، این امکان را ارائه میکنند که عملیات جستجو و درج در زمان ثابتی انجام
گیرد.
در این
درس شما یاد خواهید گرفت که:
§
چگونه گنجانههایی نظیر set ، multiset، unordered_set، unordered_multiset میتوانند به شما کمک کنند
§
درج، حذف و جستجوی اعضا در این
نوع گنجانهها
§
مزايا و کاستیهای استفاده از
این نوع گنجانهها
مجموعه (set) و مجموعهتکراری (multiset) گنجانههایی هستند
که کار جستجوی سریع کلیدهایی (key) که در آنها ذخیره
شده را تسهیل میبخشند. کلیدها مقادیری هستند که در یک گنجانه یکبعدی ذخیره میشوند. تفاوت میان set و multiset در این است که دومی اجازه میدهد
مقادیر تکراری در آن ذخیره شود ولی اولی تنها میتواند مقادیر یکتا را در خود
ذخیره کند.
شکل 19.1 فقط جنبه نمایشی دارد و حاکی از این است که
یک set از اسامی فقط حاوی اسامی منحصر به فرد است، در
حالی که multiset
اجازه میدهد نامهای تکراری نیز در آن ذخیره شوند. بدلیل اینکه این دو کلاس از نوع
گنجانههای عام STL هستند، درنتیجه میتوانند هر چیزی، از رشتهها گرفته تا اعداد، structureها، و یا اشیایی از کلاسهای مختلف را درخود ذخیره
کنند.
شکل 19.1 تجسم یک مجموعه (set) و مجموعهتکراری (multiset) که از رشتهها تشکیل شدهاند
به منظور
تسهیل بخشیدن به جستجوی سریع، set و multiset
طوری در STL پیادهسازی شدهاند که به درخت دودویی (binary tree) شباهت دارد. این یعنی،
اعضا درست در همان زمانی که درج میشوند، مرتب هم میشوند تا امکان جستجوی سریع در
آنها وجود داشته باشد. این ویژگی حاکی از این نیز هست که برخلاف بردار که در آن میتوانستید مقدار یک عضو را تغییر
دهید، شما نمیتوانید مقدار عضوی از مجموعه را تغییر دهید. دلیل این مسئله هم روشن است زیرا
اعضای ذخیره شده در مجموعهها (یا مجموعههای تکراری) بر حسب مقداری که دارند در
یک مکان بخصوص از درخت دودویی ذخیره میشوند، و درنتیجه این امکان وجود ندارد که
بتوان هر مقداری را در هر جایی از این درخت ذخیره کرد.
برای استفاده از کلاس std::set یا std::multiset، شما باید فایل سرآمد آن را
در برنامه خود شامل کنید:
set
و multiset کلاسهای الگو هستند، درنتیجه پیش از اینکه شما از متدهایی
آنها استفاده کنید، نیاز است تا آنها را برای گونه خاصی ویژهسازی کنید.
نمونهسازی
از یک مجموعه یا مجموعهتکراری نیاز دارد تا کلاس الگوی std::set یا std::multiset
برای گونه خاصی ویژهسازی شوند:
std::set <int> setIntegers;
std::multiset <int> msetIntegers;
برای
اینکه یک مجموعه (یا
مجموعهتکراری) را تعریف کنید که حاوی اشیایی از کلاس Tuna باشد شما باید
به شکل زیر عمل کنید:
std::set <Tuna> setIntegers;
std::multiset <Tuna> msetIntegers;
برای
اعلان تکرارکنندهای که به عضوی در مجموعه اشاره کند شما به نحوه زیر عمل میکنید:
std::set<int>::const_iterator iElementInSet;
std::multiset<int>::const_iterator
iElementInMultiset;
درصورتی
که نیاز دارید تا تکرارکننده بتواند
مقادیر را تغییر دهد و یا توابع غیر-ثابتی را فراخوانی کند، باید بجای const_iterator از iterator استفاده کنید.
با توجه
به اینکه set و multiset هر دو گنجانههایی
هستند که اعضا را در هنگام درج مرتب میکنند، درنتیجه برای مرتب کردن نیاز به
معیار دارند، و اگر شما برای اینکار معیاری را تعیین نکنید، آنها از محمولِ پیشفرض
std::less استفاده میکنند. این
باعث میشود تا مجموعه شما حاوی اعضایی باشد که به ترتیب صعودی مرتب شدهاند.
به منظور
اینکه مجموعه یا
مجموعهتکراری از
معیار دیگری برای مرتب کردن اعضای خود استفاده کند، شما باید کلاسی را تعریف کنید
که در آن عملگر () تعریف
شده باشد، و دو مقدار از گونهای را بگیرد که در گنجانه زخیره میشوند، و برحسب اینکه معیار مرتب
شدن شما چه باشد مقدار true را باز گرداند. برای مثال اگر
بخواهیم ترتیب صعودی را به ترتیب نزولی تغییر دهیم بصورت زیر عمل میکنیم:
// set /
multiset استفاده از
پارامترهای الگویی در نمونهسازی
template <typename T>
struct SortDescending
{
bool operator()(const T& lhs, const T& rhs) const
{
return (lhs > rhs);
}
};
حالا شما میتوانید این محمول را در هنگام ویژهسازی یک set یا multiset بصورت یکی از پارامترهای ویژهسازی ارائه دهید:
// یک
مجموعه و مجموعهتکراری از اعداد صحیح که برای مرتب
//
استفاده میکنند SortDescending شدن از
set <int, SortDescending<int> >
setIntegers;
multiset <int, SortDescending<int> >
msetIntegers;
علاوه بر
موارد ذکر شده، شما همیشه میتوانید مجموعهای را ایجاد کنید که از مجموعه دیگری، یا از محدوده خاصی از آن، کپی شده
باشد. برای بررسی این موارد به لیست 19.1 رجوع کنید.
لیست 19.1 نمونهسازیهای مختلف یک مجموعه و مجموعهتکراری
0: #include
<set>
1:
2: // set /
multiset استفاده از
پارامترهای الگویی در نمونهسازی
3: template <typename
T>
4: struct SortDescending
5: {
6: bool operator()(const T& lhs, const T& rhs) const
7: {
8: return (lhs > rhs);
9: }
10: };
11:
12: int main ()
13: {
14: using namespace std;
15:
16: //از اعدادصحیح که برای مرتب کردن اعضای خود set / multiset یک
// از محمول پیش فرض استفاده میکند
17: set <int> setIntegers1;
18: multiset <int> msetIntegers1;
19:
20: //از اعدادصحیح که برای مرتب کردن اعضای خود set / multiset یک
//استفاده میکند SortDescending از محمول
21: set<int, SortDescending<int> > setIntegers2;
22: multiset<int, SortDescending<int> > msetIntegers2;
23:
24: //ایجاد یک مجموعه از روی دیگری، یا بخشهایی از دیگری
25: set<int> setIntegers3(setIntegers1);
26: multiset<int> msetIntegers3(setIntegers1.cbegin(), setIntegers1.cend());
27:
28: return 0;
29: }
تحلیل برنامه▼
این
برنامه هیچ خروجی ندارد ولی نمونهسازیهای مختلف set و multiset را نشان میدهد. در خطوط 17 و
18 شما نمونهسازی سادهای را میبینید که هیچ پارامتری به غیر از گونه مورد نظر
(یعنی int)
در آن بچشم نمیخورد. این باعث میشود تا اعضای این گنجانه به ترتیب پیشفرض
(یعنی صعودی) مرتب شوند. درصورتی که شما بخواهید شکل پیشفرض مرتب سازی را تغییر
دهید، همانطور که در خطوط 10-3 دیده میشود، باید برای این منظور یک محمول تعریف کنید، و از این محمول در تابع main() برای نمونهسازی
استفاده کنید (خطوط 21 و 22). این باعث میشود تا ترتیب مرتب سازی به نزولی تغییر
کند. بالاخره خطوط 25 و 26 روشهایی دیگری برای نمونهسازی از مجموعهها را نشان
میدهد که توسط آنها شما میتوانید از یک مجموعه کپی بگیرید و یا قسمتی از آن را در دیگری
کپی کنید. البته مهم نیست که این گنجانهای که از آن کپی میگیرید حتما یک مجموعه
باشد، بلکه میتواند یک بردار، یک لیست، و یا هر نوع گنجانه دیگر STL باشد که تکرارکنندههایی را
بازگرداند که بتوان با استفاده از آنها یک محدوده را مشخص کرد.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
کتابخانه
استاندارد الگو (STL) گنجانههایی را در اختیار
برنامهنویس قرار میدهد که میتوانند در برنامههایی مورد استفاده قرار گیرند که
غالباً در آنها به جستجوهای سریع نیاز است.
این درس
موارد زیر را پوشش میدهد:
§
کلاسهای گنجانهایmap ، multimap،unordered_map و unordered_multimap از چه طریقی میتوانند
برای شما مفید باشند.
§
درج، حذف و جستجو در این نوع
گنجانهها.
§
چگونگی ارائه یک محمولِ سفارشی
برای مرتب کردن اعضا.
§
اصول کارکرد جداول هَش.
نِگاشت ((map و نِگاشتتکراری (multimap) گنجانههایی هستند
که اعضای آن را جفتهای کلید-مقدار (key-value) تشکیل میدهند و
خاصیت عمده آنها این است که اجازه میدهند تا برحسب یک کلید، مقادیری در آنها
جستجو شود. تجسم یک map در شکل 20.1 نشان داده شده است.
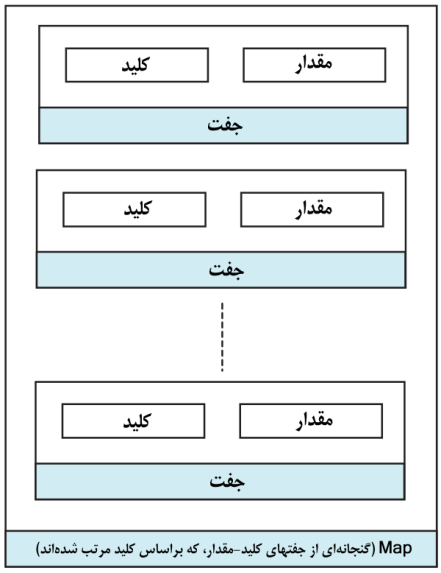
شکل 20.1 تجسم گنجانهای از جفتها، که هر جفت حاوی
یک کلید و
یک مقدار است.
تفاوت
میان map و multimap این است که دومی
اجازه میدهد تا کلیدهای تکراری در گنجانه ذخیره شود، درحالی که در اولی تنها کلیدهایی ذخیره میشوند
که یکتا و غیرتکراری باشند.
برای تسهیل جستجوهای سریع، STL این کلاسها را بصورت داخلی
به شکل درختهای دودویی پیادهسازی کرده
است. این یعنی اعضای درج شده در یک map
یا multimap در زمان درج مرتب میشوند.
همچنین، این حاکی از این نیز هست که برخلاف بردارها، که میتوان مقدار اعضای آن را
با مقدار دیگری تغییر داد، اعضای موجود در یک نگاشت را نمیتوان با مقدار جدیدی
جایگزین کرد که با مقدار فعلی متفاوت باشد. دلیل آن هم این است که نگاشت برای
بهینه کردن عملکرد خود نیاز دارد تا مقادیر گوناگون را در مکانهای مختلفی از درخت
دودویی ذخیره کند.
برای استفاده از std::map و یا std::multimapشما باید فایل سرآمد آن
را در برنامه خود شامل کنید:
#include<map>
گنجانههای
نگاشت و نگاشتتکراری STL از نوع کلاسهای الگو هستند و قبل از استفاده از آنها، لازم است تا برای
گونه خاصی ویژهسازی شوند.
برای
نمونهسازی یک map
یا multimap، که کلید آن را اعداد صحیح و مقدار آن را رشتهها
تشکیل میدهند، باید کلاس الگوی std::map
یا std::multimap
ویژهسازی شوند.
برای ویژهسازی کلاس map
برنامه نویس باید گونهِ کلید و گونهِ مقدار را مشخص کند. همچنین او میتواند بصورت
اختیاری محمولی را مشخص کند که برای مرتب کردن اعضا از آن استفاده شود. بنابراین
نحوه نمونهسازی map
میتواند بصورت زیر باشد:
#include
<map>
using namespace std;
...
map<keyType, valueType, Predicate=std::less
<keyType> > mapObject;
multimap<keyType,valueType,Predicate=std::less <keyType> > mmapObject;
نوشتن پارامتر سوم اختیاری است، و هنگامی که شما تنها گونهِ کلید و گونهِ مقدار را برای پارامتر اول و دوم مشخص میکنید و از ذکر پارامتر سوم صرف نظر میکنید، کلاسهای std::map یا std::multimap از الگوی پیشفرض std::less<> برای مشخص کردن معیار مرتب کردن اعضا استفاده میکنند. پس یک map یا multimap که یک عدد صحیح را به یک رشته مرتبط میکند (به عبارتی نگاشتی از آنها بوجود میآورد) بصورت زیر اعلان میشود:
std::map <int, string> mapIntToString;
std::multimap <int, string> mmapIntToString;
لیست 20.1
نمونهسازی این گنجانهها را
با جزئیات بیشتری نشان میدهد.
لیست 20.1 نمونهسازی شیئی از کلاس map و multimap که یک کلید از
گونه int
را به یک رشته مرتبط میکند.
0:
#include<map>
1:
#include<string>
2:
3:
template<typename KeyType>
4: struct ReverseSort
5: {
6: bool operator()(const KeyType& key1, const KeyType& key2)
7: {
8: return (key1 > key2);
9: }
10: };
11:
12: int main ()
13: {
14: using namespace std;
15:
16: // ایجاد یک نگاشت و یک نگاشت تکراری که اعداد صحیج را به رشتهها مرتبط میکند
17: map<int, string> mapIntToString1;
18: multimap<int, string> mmapIntToString1;
19:
20: //بصورت کپی یکدیگر تعریف شدهاند map و multimap در اینجا
21: map<int, string> mapIntToString2(mapIntToString1);
22: multimap<int, string> mmapIntToString2(mmapIntToString1);
23:
24: //بصورت بخشی از یکدیگر تعریف شدهاند map و multimap در اینجا
25: map<int, string> mapIntToString3(mapIntToString1.cbegin(),
26: mapIntToString1.cend());
27:
28: multimap<int,string> mmapIntToString3 (mmapIntToString1.cbegin(),
29: mmapIntToString1.cend());
30:
31: // با محمولی که ترتیب اعضا را معکوس میکند map and multimap ایجاد
32: map<int, string, ReverseSort<int> > mapIntToString4
33: (mapIntToString1.cbegin(), mapIntToString1.cend());
34:
35: multimap<int, string, ReverseSort<int> > mmapIntToString4
36: (mapIntToString1.cbegin(), mapIntToString1.cend());
37:
38: return 0;
39: }
تحلیل برنامه▼
ابتداء بر
روی main() تمرکز کنید که در
خطوط 39-12 تعریف شده. در خطوط 21 و 22 برنامه سادهترین شکل تعریف map و multimap دیده میشود که
از نگاشت اعداد صحیح به رشتهها تشکیل شده. خطوط 28-25 ایجاد یک نگاشت و یک نگاشتتکراری را نشان میدهد که در آن معیار ترتیب توسط
شما تعیین شده. توجه داشته باشید که در ایجاد نمونههای قبلی، این معیار بصورت پیشفرش
std::less<T>
بود، که باعث میشد اعضا بصورت صعودی مرتب شوند. اگر شما بخواهید این ترتیب را تغییر دهید
باید محمولی را برای اینکار ارائه دهید، که این محمول بصورت یک class
یا یک struct
است که در آن operator()
پیادهسازی شده.
در اینجا این محمول struct ReverseSort است که در خطوط 10-4 تعریف شده و در خطوط 32 و 35 برای ایجاید یک map و multimap از آن استفاده شده است.
آیا برای کامپایل cbegin() و cend()کامپایلر
از شما خطا میگیرد؟
اگر میخواهید این برنامه را با کامپایلرهای
قدیمی C++ که با C++11 سازگار نیستند کامپایل کنید، باید بجای cbegin() و cend()
از begin() و end() استفاده کنید.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
شیء تابعی (Function object) یا تابعگر (functor) ممکن است چیز عجیب یا
ترسناکی بنظر برسد، ولی شما قبلاً
هم با آن سر و کار داشتهاید، هرچند ممکن است زیاد به آنها توجه نکرده باشید.
در این
درس شما یاد خواهید گرفت که:
§
مفهوم اشیاِ تابعی چیست
§
استفاده از اشیا تابعی بعنوان محمول
§
چگونه محمولاتِ یگانه و دوگانه
توسط اشیا تابعی تعریف
میشوند
از لحاظ
مفهومی، ”اشیا تابعی“ اشیایی هستند که مانند توابع عمل میکنند. ولی از لحاظ
تعریف، اشیا تابعی اشیایی از یک کلاس هستند که در آن عملگر ()
پیادهسازی شده.
گرچه میتوان خود توابع، و نیز اشارهگرهایی که به توابع اشاره میکنند، را نیز
بعنوان اشیا تابعی طبقهبندی کرد. ولی چیزی که درباره تابعگرهایی که بصورت کلاس
تعریف میشوند مهم است، توانایی اعضای آنها است که هم میتوانند عملگر ()
را تعریف کنند و هم وضعیت (state) خاصی را در خود
ذخیره کنند. منظور از وضعیت، مقداری است که در اعضای کلاس ذخیره شده، و همین ویژگی
است که باعث میشود این اشیا در الگوریتمهای STL کاربرد بیشتری داشته باشند.
آن دسته از اشیا تابعی که توسط یک برنامهنویس C++
در هنگام کار با STL مورد استفاده قرار میگیرند، معمولاَ میتواند به دو دسته زیر تقسیم بندی شود:
§
توابعِ یگانه – یعنی توابعی که یک آرگومان میگیرند؛ مثلاً f(x) یک تابع یگانه است. هنگامی که تابع یگانه یک مقدار بولی را
بازگرداند، به آن یک محمول (predicate) میگویند.
§
توابعِ دوگانه – یعنی تابعی که دو آرگومان میگیرد؛
مثلاً f(x,y)
یک تابع دوگانه است. هنگامی که تابع دوگانه یک مقدار بولی را بازگرداند، به
آن یک محمول دوگانه (binary
predicate) میگویند.
معمولاً
از اشیا تابعی که
یک مقدار بولی را بازمیگردانند در الگوریتمهایی استفاده میشود که نیاز به تصمیم
گیری دارند. یک شیء تابعی که
دو شیء تابعی را با هم ترکیب کند،
یک شیء تابعی قابل تطبیق (adaptive function object)
نامیده میشود.
امکان این
هست که صدها صفحه درباره اشیا تابعی مطلب
نوشت و کارکرد آنها را از لحاظ نظری توضیح داد. ولی این امکان هم وجود دارد که
بتوان با استفاده از چند برنامه ساده چگونگی کارکرد آنها را درک کرد. بنابراین
اجازه دهید تا ما هم رویکرد عملی را انتخاب کنیم و مستقیماً به سراغ کاربرد اشیا
تابعی (یا تابعگرها) در جهان برنامهنویسی C++
برویم!
توابعی که
بر روی یک پارامتر عمل میکنند، توابع یگانه هستند. یک تابع یگانه میتواند کار
خیلی سادهای را انجام دهد، مثلاً میتواند مقدار یک عضو را روی صفحه نمایش دهد.
چنین تابعی میتواند بصورت زیر تعریف شود:
// یک تابع یگانه
template <typename elementType>
void FuncDisplayElement (const elementType &
element)
{
cout << element << ‘ ‘;
};
تابع FuncDisplayElement تنها یک پارامتر الگویی بنام elementType قبول میکند و آن را با استفاده از دستور خروجی کنسول ((std::cout بر روی صفحه نمایش میدهد. همچنین میتوان این تابع را به روش دیگری، و با پیادهسازی عملگر () در یک class یا struct، پیادهسازی کرد:
//که
میتواند مانند یک تابع یگانه رفتار کند structیک
template <typename elementType>
struct DisplayElement
{
void operator () (const elementType& element) const
{
cout << element << ‘ ‘;
}
};
توجه داشته باشید که DisplayElement یک struct است. درصورتی که یک class بود، عملگر () باید بصورت عمومی در این کلاس تعریف شود. یک struct مانند یک class است، با این تفاوت که اعضای آن بصورت پیشفرض دارای دسترسی عمومی هستند.
هر دو این
پیادهسازیها میتواند با الگوریتم for_each بکار گرفته شود و محتوای یک گنجانه را روی روی صفحه نمایش دهد. مثالی از چنین کاربردی
در لیست 21.1 نشان داده شده.
لیست 21.1 نمایش محتوای یک گنجانه بر روی صفحه با استفاده از یک تابع یگانه
0: #include
<algorithm>
1: #include
<iostream>
2: #include
<vector>
3: #include
<list>
4:
5: using namespace std;
6:
7: // که مانند یک شیء تابعی یگانه عمل میکندstruct یک
8: template <typename elementType>
9: struct DisplayElement
10: {
11: void operator () (const elementType& element) const
12: {
13: cout << element << ‘ ‘;
14: }
15: };
16:
17: int main ()
18: {
19: vector <int> vecIntegers;
20:
21: for (int nCount = 0; nCount < 10; ++ nCount)
22: vecIntegers.push_back (nCount);
23:
24: list <char> listChars;
25:
26: for (char nChar = ‘a’; nChar < ‘k’; ++nChar)
27: listChars.push_back (nChar);
28:
29: cout << “Displaying the vector of integers: “ << endl;
30:
31: // نمایش آرایهای از اعداد صحیح
32: for_each ( vecIntegers.begin () // شروع محدوده نمایش
33: , vecIntegers.end () // پایان محدوده نمایش
34: , DisplayElement <int> () ); // شیء تابعی یگانه
35:
36: cout << endl << endl;
37: cout << “Displaying the list of characters: “ << endl;
38:
39: // نمایش لیستی از حروف
40: for_each ( listChars.begin () // شروع محدوده نمایش
41: , listChars.end () // پایان محدوده نمایش
42: , DisplayElement <char> () );// شیء تابعی یگانه
43:
44: return 0;
45: }
خروجی برنامه▼
Displaying the vector of integers:
0 1 2 3 4 5 6 7 8 9
Displaying the list of characters:
a b c d e f g h i j
تحلیل برنامه▼
در خطوط
15-8 یک شیء تابعی بنام
DisplayElement
تعریف میشود، که عملگر () در آن پیادهسازی شده است. در خطوط 34-32، کاربرد این شیء
تابعی در الگوریتم std::for_each
دیده میشود. for_each
سه پارامتر میگیرد: اولی شروع محدوده، دومی پایان محدوده، و سومی نام تابعی است
که باید برای هر عضو موجود در این محدوده فراخوانی شود. به عبارت دیگر، این برنامه برای هر عضو موجود در
بردار vecIntegers،
تابع DisplayElement::operator()
را فراخوانی میکند. توجه داشته باشید که شما میتوانید بجای کاربرد struct DisplayElement، از تابع FuncDisplayElement هم که در آغاز
این بخش تعریف شد استفاده کنید، که در واقع همین کار را برای شما انجام میدهد. در
خطوط 42-40 از همین عملکرد برای نمایش حروف موجود در یک لیست استفاده شده است.
C++11 عبارات لاندایی را ارائه میدهد که در
واقع اشیا تابعی بینام هستند.
در لیست 21.1 اگر بخواهیم بجای struct از یک عبارت لاندا استفاده کنیم، برنامه خیلی کوتاهتر میشود:
// نمایش محتوای یک آرایه عددی
توسط عبارت لاندا
for_each ( vecIntegers.begin () // شروع محدوده
,
vecIntegers.end () // پایان
محدوده
, [](int&
Element) {cout << element << ‘ ‘; } ); // عبارت لاندا
بنابراین اضافه شدن عبارات لاندا به C++ پیشرفت قابل ملاحظهای برای آن محسوب میشوند، و شما باید حتماً درس 22 که مربوط به آنهاست را مطالعه کنید. لیست 22.1 استفاده از توابع لاندا را برای نمایش محتوای یک گنجانه نشان میدهد.
مزیت اصلی
استفاده از یک شیء تابعی که
بصورت struct
تعریف شده هنگامی آشکار میشود که بتوانید از اعضای struct برای ذخیره اطلاعات
استفاده کنید. این چیزی است که تابع FuncDisplayElement
نمیتواند آن را انجام دهد، زیرا یک struct علاوه بر داشتن عملگر () میتواند دارای اعضای دیگری نیز باشد، و این اعضا
میتوانند اطلاعات اضافی را در خود ذخیره کنند. نسخهای از برنامه فوق که تاحدی
تغییر داده شده و در آن از اعضای struct استفاده میشود بصورت
زیر است:
template <typename elementType>
struct DisplayElementKeepCount
{
int
Count;
DisplayElementKeepCount () // سازنده
{
Count = 0;
}
void operator () (const elementType& element)
{
++ Count;
cout << element << ‘ ‘;
}
};
در برنامه کوتاه فوق، DisplayElementKeepCount نسخه اصلاح شده struct قبلی است. در اینجا بدلیل اینکه عملگر () عضو Count را تغییر میدهد دیگر یک تابع ثابت نیست. عضو Count شمار دفعاتی را در خود نگاه میدارد که این تابع فراخوانی میشود. این تعداد بصورت عضو عمومی Count در دسترس است. مزیت استفاده از چنین شیء تابعی این است که وضعیت موجود را در خود ذخیره کند[23]. چگونگی اینمورد در لیست 21.2 نمایش داد شده است.
لیست 21.2 استفاده از یک شیء تابعی برای نگاه داری وضعیت (State)
0: #include<algorithm>
1:
#include<iostream>
2:
#include<vector>
3: using
namespace std;
4:
5: template<typename elementType>
6: struct DisplayElementKeepCount
7: {
8: int Count;
9:
10: // سازنده
11: DisplayElementKeepCount() : Count(0) {}
12:
13: // عضو را نمایش بده، تعداد آنها را نگهدار!
14: void operator()(const elementType& element)
15: {
16: ++ Count;
17: cout << element<< ‘ ‘;
18: }
19: };
20:
21: int main()
22: {
23: vector<int> vecIntegers;
24: for(int nCount = 0; nCount< 10; ++ nCount)
25: vecIntegers.push_back(nCount);
26:
27: cout << “Displaying the vector of integers: “<< endl;
28:
29: // نمایش محتوای یک بردار
30: DisplayElementKeepCount<int> Result;
31: Result = for_each( vecIntegers.begin() // شروع محدوده
32: , vecIntegers.end() // پایان محدوده
33: , DisplayElementKeepCount<int>() );// شیء تابعی
34:
35: cout << endl<< endl;
36:
37: //آن را بازگردانده بود for_each استفاده از وضعیتی که
38: cout << “‘“ << Result.Count << “‘ elements were displayed!”<< endl;
39:
40: return 0;
41: }
خروجی برنامه▼
Displaying the vector of integers:
0 1 2 3 4 5 6 7 8 9
‘10’ elements were displayed!
تحلیل برنامه▼
عمدهترین
تفاوتی که بین این برنامه و برنامه قبلی وجود دارد استفاده از DisplayElementKeepCount() بعنوان مقدار بازگشتی for_each() است. عملگر ()
که در struct
DisplayElementKeepCount تعریف شده، توسط الگوریتم for_each() بر روی کلیه اعضای
گنجانه فراخوانی
میشود. این تابع هر بار میتواند عضوی را نمایش دهد و شمارشگر درونی که در متغیر
Count ذخیره شده را یک واحد
افزایش دهد. هنگامی که کار for_each() به پایان رسید، شما در خط 38 از این شیء (Result) برای نمایش تعداد دفعاتی که
شیء تابعی فراخوانی
شده استفاده میکنید. توجه داشته باشید که اگر قرار بود بجای تابعی که در struct
پیاده سازی شده است از توابع معمولی برای این کار استفاده شود، امکان این وجود
نداشت که بتوان بصورت مستقیم چنین ویژگی را در برنامه پیاده کرد، هرچند با روشهای
دیگری میتوان به همین نتیجه دست یافت.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
عبارات
لاندا روشهایی برای کوتاه کردن تعریف
”اشیا تابعی بدون
نام“ هستند. این نوع عبارات جدیدند و با شروع C++11
به این زبان اضافه شدهاند.
در این
درس شما یادخواهید گرفت که:
§
چگونه یک عبارت لاندا را تعریف کنید
§
چگونه از عبارات لاندا بعنوان
محمول استفاده
کنیم
§
چگونه عبارات لاندایی را تعریف
کنیم که بتواند وضعیت را
در خود نگاه دارد و آن را تغییر دهد
عبارت لاندا (Lambda Expression)
را میتوان نسخه کوتاه
شده و بینام یک struct یا class محسوب کرد
که در آن عملگر () بصورت عمومی
تعریف شده است. در این حالت، یک عبارت لاندا کار همان اشیا تابعی را انجام میدهد که قبلاً در درس 21 با آنها
آشنا شدید. پیش از اینکه به تجزیه و تحلیل توابع لاندا بپردازیم، نمونهای از یک شیء تابعی را در نظر بگیرید (مثلاً موردی که در لیست
21.1 آمده بود):
//که مانند یک تابع یگانه عمل میکند struct یک
template <typename elementType>
struct DisplayElement
{
void operator () (const elementType& element) const
{
cout << element << ‘ ‘;
}
};
این شیء تابعی عضوی را بر روی صفحه نمایش میدهد و ما قبلاً از آن در الگوریتم std::for_each استفاده کردیم:
// نمایش
اعضای یک آرایه
for_each ( vecIntegers.begin () // شروع محدوده
,
vecIntegers.end () // پایان محدوده
,
DisplayElement <int> () ); // شیء تابعی یگانه
یک عبارت لاندا میتواند کلیه تعاریف مربوط به یک شیء تابعی و بکارگیری آن را در سه خط خلاصه کند:
// نمایش
آرایهای از اعداد با استفاده از یک عبارت لاندا
for_each ( vecIntegers.begin () // شروع محدوده
, vecIntegers.end
() // پایان محدوده
, [](int& Element) {cout << element << ‘ ‘; } ); // عبارت لاندا
عبارت لاندا در کد فوق به شکل زیر است:
[](int Element) {cout << element << ‘ ‘; }
و هنگامی
که کامپایلر به
آن برخورد میکند، عبارت لاندا را بصورت خودکار به struct معادلِ آن تبدیل میکند:
DisplayElement<int>:
struct NoName
{
void
operator () (const int& element) const
{
cout << element << ‘ ‘;
}
};
تعریف یک عبارت لاندا باید با یک یک جفت کروشه [] شروع شود. اساساً کاری که این کروشهها انجام میدهند این است که شروع یک عبارت لاندا را به کامپایلر اطلاع میدهند. پس از آنها فهرست پارامترها قرار میگیرد، که در واقع با آن فهرستی که در پیادهسازی عملگر () در یک struct آمده بود، تفاوتی ندارد.
آن نسخهای
از عبارات لاندا که میتواند بعنوان یک تابع یگانه مورد استفاده قرار گیرد بشکل
زیر تعریف میشود:
[](گونه نام
پارامتر) {// عبارت لاندا در اینجا قرار میگیرد ;}
توجه
داشته باشید اگر بخواهید، میتوانید پارامتر را بوسیله ارجاع بفرستید:
[](گونه & نام
پارامتر) {// عبارت لاندا در اینجا قرار میگیرد ;}
به منظور
درک بهتر کاربرد توابع لاندا، به برنامهای که در لیست 22.1 آمده نگاه کنید.
لیست 22.1 نمایش اعضای موجود در یک گنجانه که بجای شیء تابعی، از عبارات لاندا در
الگوریتم for_each استفاده شده است.
0: #include
<algorithm>
1: #include
<iostream>
2: #include
<vector>
3: #include
<list>
4:
5: using namespace std;
6:
7: int main ()
8: {
9: vector <int> vecIntegers;
10:
11: for (int nCount = 0; nCount < 10; ++ nCount)
12: vecIntegers.push_back (nCount);
13:
14: list <char> listChars;
15: for (char nChar = ‘a’; nChar < ‘k’; ++nChar)
16: listChars.push_back (nChar);
17:
18: cout << “Displaying vector of integers using a lambda: “ << endl;
19:
20: // نمایش آرایهای از اعداد صحیح
21: for_each ( vecIntegers.begin () // Start of range
22: , vecIntegers.end () // End of range
23: , [](int& element) {cout << element << ‘ ‘; } ); تابع لاندا
24:
25: cout << endl << endl;
26: cout << “Displaying list of characters using a lambda: “ << endl;
27:
28: // نمایش لیستی از حروف
29: for_each ( listChars.begin () // Start of range
30: , listChars.end () // End of range
31: , [](char& element) {cout << element << ‘ ‘; } ); //تابع لاندا
32:
33: cout << endl;
34:
35: return 0;
36: }
خروجی برنامه▼
Displaying vector of integers using a lambda:
0 1 2 3 4 5 6 7 8 9
Displaying list of characters using a lambda:
a b c d e f g h i j
تحلیل برنامه▼
در اینجا
دو عبارت لاندا وجود دارد، یکی در خط 23 و دیگری در خط 31.
آنها شباهت زیادی با هم دارند و تنها تفاوت آنها در گونهِ پارامتری است که میگیرند.
اولی یک پارامتر از گونه int میگیرد و از آن برای چاپ
عضوی از بردار استفاده
میکند، در حالی که دومی یک char
میگیرد و از آن برای چاپ اعضای که در
یک std::list ذخیره شدهاند
استفاده میکند.
اینکه این برنامه و برنامهای که در لیست
22.1 آمده خروجی یکسانی را بیرون میدهند تصادفی نیست. در واقع این برنامه نسخه
لاندای برنامهای است که در لیست 21.1 آمده بود و در آن بجای عبارت لاندا از شیء تابعی DisplayElement<T> استفاده شده بود.
با مقایسه این دو شما متوجه خواهید شد که
توابع لاندا چه توانایهایی در سادهتر کردن، و نیز کوتاهتر کردن، برنامههای C++ میتوانند داشته باشند.
در برنامهنویسی،
”محمول“ چیزی است که کمک میکند تا تصمیمی گرفته شود. محمولِ یگانه، یک تابع یگانه
است که مقدار بازگشتی آن از گونه بولی و میتواند true یا false
باشد. عبارات لاندا نیز میتوانند مقادیری را بازگردانند. برای نمونه، اگر ورودی
زیر یک عدد زوج باشد، عبارت لاندا مقدار true را بازمیگرداند:
[](int&
Num) {return ((Num % 2) == 0); }
ماهیت عبارت بازگشتی (یعنی ((Num
% 2) == 0)) به کامپایلر میگوید که عبارت لاندای فوق یک گونه بولی را بازمیگرداند.
شما میتوانید
از عبارات لاندایی که محمول یگانه هستند، در الگوریتمهایی
نظیر std::find_if() استفاده کنید، و مانند آنچه در لیست 22.2 نشان داده
شده، طوری آنها تعریف کنید که مثلاً بتوانند اعداد زوج را در یک گنجانه پیدا کنند.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
بخش مهمی
از کتابخانه استاندارد
الگو (STL) مجموعهای از توابع عمومی
است که در فایل سرآمد <algorithm>
قرار دارند و به برنامهنویس کمک میکنند تا محتوای گنجانهها را تغییر دهد و یا آنها را دستکاری کند.
در این
درس شما یاد میگیرید که:
§
چگونه برای کاستن از حجم برنامهها
از الگوریتمهای STL استفاده کنیم
§
آشنایی با آن دسته از توابع
عام STL
که میتوانند در عملیاتی نظیر جستجو، حذف، افزودن و غیره به شما کمک کنند
یافتن،
جستجو کردن، حذف کردن، و شمارش نمونهای از عملیات عام (یا
عمومی = جِنریک =generic) هستند که برنامهنویس
در بیشتر برنامهها با آن برخورد میکند. STL بیشتر این عملیات، و نیز موارد زیاد دیگری را، بصورت توابع الگویی عام (generic template functions)
در اختیار برنامه نویس قرار میدهد تا عملیات مورد نظر را با استفاده از
تکرارکنندهها بر روی گنجانهها انجام
دهد. به منظور اینکه کاربر بتواند از الگوریتمها استفاده کند، قبل از هر چیز باید
فایل سرآمد آن، یعنی <algorithm>، را در برنامه خود
شامل کند.
اگرچه بیشتر الگوریتمها عملیات خود را
بوسیله تکرارکنندهها بر روی گنجانهها انجام میدهند، ولی لزوماً همه الگوریتمها
برای انجام عملیات بر روی گنجانهها طراحی نشدهاند، و در نتیجه همه الگوریتمها به تکرارکننده نیاز ندارند. برخی از آنها، نظیر swap()،
تنها دو مقدار میگیرند و آنها را با هم عوض میکنند. بطور مشابه، الگوریتمهایی
مانند min() و max() مستقیماً بر روی مقادیر کار
میکنند و نیازی به تکرارکننده ندارند.
کلاً
الگوریتمهای STL
را میتوان به دو دسته تقسیم بندیکرد: 1- الگوریتمهای
تغییر ندهنده (non-mutating
algorithms) 2- الگوریتمهای
تغییردهنده (mutating algorithms).
الگوریتمهایی
که نه ترتیب، و نه محتوای، گنجانهها را تغییر دهند ”الگوریتمهای تغییر ندهنده“ نامیده
میشوند. در جدول 23.1 برخی از مهمترین الگوریتمهای تغییر ندهنده نشان داده شده
است.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
کتابخانه
استاندارد
الگو (STL) گنجانههایی را ارائه میدهد
که بنظور اینکه رفتار پشته و صف را
شبیهسازی کنند، گنجانههای دیگر را تعدیل میکنند. این نو از گنجانهها که از نظر درونی از گنجانههای دیگر استفاده
میکنند و رفتار متمایزی نسبت به آنها نشان میدهند گنجانههای انطباقی (adaptive containers)
معروفند.
در این
درس شما موارد زیر را یادمیگرید:
§
خصوصیات پشتهها و صفها
§
استفاده از پشتههای STL
§
استفاده از صف های STL
§
استفاده از صفهای اولویتدار STL
پشتهها (stacks) و صفها (queues)
خیلی به آرایهها و لیستها شباهت دارند، ولی برای درج، حذف، و دستیابی به اعضا،
محدودیتهایی را اعمال میکنند. خصوصیات رفتاری آنها دقیقاً در زمان درج یا حذف اعضا معلوم میشود.
پشتهها نوعی ساختار داده را تشکیل میدهند که به
آنها LIFO میگویند (یعنی، هرچه آخر آمده اول از همه خارج میشود).
در این نوع ساختارها اعضا میتوانند در بالا درج شوند و از همانجا نیز حذف شوند.
یک پشته را میتوان مانند ستونی از بشقابها تصور کرد که بر روی هم چیده شده.
آخرین بشقابی که به بالای این ستون اضافه میشود، اولین بشقابی خواهد بود که از آن
برداشته میشود. شما نمیتوانید بشقابهایی که در میانه و یا تَه این ستون قرار
دارند را بردارید[24]. این روش سازماندهی که مستلزم ”اضافه کردن و
برداشتن اعضا از بالا است“ در شکل 24.1 نشان داده شده است.
شکل 24.1 عملیات بر روی یک پشته
این رفتار
در گنجانه std::stack
شبیهسازی شده است.
برای استفاده از کلاس std::stack
باید فایل سرآمد آن را در برنامه خود شامل کنید:
#include <stack>
صفها نوعی ساختار داده را تشکیل میدهند که به
آنها FIFO (هرچه اول آمده، اول از همه خارج میشود) میگویند.
در این نوع ساختارها اعضا میتوانند پشت سر هم درج شوند، و آن عضوی که اول از همه
درج شده، اول از همه نیز حذف میشود. یک صف (نرمافزاری) را میتوان مانند صفی از مردم تصور کرد
که منتظر خرید بلیط هستند. کسی که اول از همه به این صف وارد شده، اول از همه بلیط
خود را گرفته و از صف خارج میشود. این روشِ سازماندهی اعضا، که مستلزم ”اضافه شدن
از پشت و خارج شدن از جلو است“ در شکل 24.2 نشان داده شده است.

شکل 24.2 عملیات بر روی یک صف
رفتار
پشته در گنجانه std::queue
شبیهسازی شده است.
برای استفاده از کلاس std::queue
باید فایل سرآمد آن را در برنامه خود شامل کنید:
#include <queue>
کلاس پشته
STL یک کلاس الگویی است
که برای استفاده از آن باید فایل سرآمد < stack>
را در برنامه خود شامل کنید. stack
یک کلاس عام است
که اجازه درج و حذف اعضا از بالا را میدهد ولی اجازه دسترسی و بازبینی اعضا از
وسط گنجانه را
نمیدهد. از این نظر رفتار std::stack
شباهت زیادی با ”ستون بشقابها“ دارد.
در برخی
از پیادهسازیهای STL، کلاس std::stack بصورت زیر تعریف شده است:
template <
class elementType,
class Container=deque<Type>
> class
stack;
پارامتر elementType گونه اعضایی را مشخص میکند که در پشته ذخیره میشوند. پارمتر دوم الگو، یعنی Container، گنجانه اصلی را مشخص میکند که پشته بر اساس آن ساخته میشود، که پیشفرض آن std::deque است، و اطلاعات در این نوع گنجانه ذخیره میشوند. این پارامتر میتواند std::vector یا std::listنیز باشد. بنابراین نمونه سازی یک پشته از اعداد صحیح بصورت زیر خواهد بود:
std::stack <int> stackInts;
شما میتوانید
پشتهای را ایجاد کنید که از هر نوع شیئی باشد، برای نمونه برای ایجاد پشتهای از
کلاس Tuna باید بصورت زیر عمل کنید:
std::stack <Tuna> stackTunas;
برای
ایجاد یک پشته که بر پایه گنجانه دیگری
(مثلاً vector)
بنا شده بصورت زیر عمل کنید:
std::stack <double, vector <double> >
stackDoublesInVector;
...........................................
برای ادامه مطالعه این فصل نسخه
کامل PDF کتاب را تهیه کنید.
بیتها میتوانند
روش موثری برای ذخیرهسازی اطلاعات مربوط به تنظیمات و نیز نشانهها باشند.
کتابخانه استاندارد
الگو (STL) کلاسهایی را ارائه میدهد
که میتوانند اطلاعات بیتی را سازماندهی کرد و یا آنها را تغییر دهند.
در این
درس شما با موارد زیر آشنا خواهید شد:
§ کلاس
bitset
§ گنجانه vector<bool>
کلاس std::bitset یکی از کلاسهای STL است که برای ساماندهی اطلاعاتی
طراحی شده که بصورت بیتی ذخیره میشوند. بدلیل اینکه std::bitset نمیتواند اندازه خود را
تغییر دهد، جزیی از گنجانههای STL
محسوب نمیشود. bitset
یک کلاس تسهیلاتی است
که طوری بهینه شده که بتواند با دنبالهای از بیتها که طول آنها ثابت است کار
کند.
برای استفاده از کلاس bitset شما باید فایل سرآمد آن را در برنامه خود شامل کنید:
#include
<bitset>
برای
نمونهسازی این کلاس الگویی لازم است شما یک پارامتر به آن بدهید. این پارامتر
تعداد بیتهایی را مشخص میکند که باید عملیات بر روی آنها انجام گیرد:
bitset <4> fourBits; // 0000 4 بیت که همه
دارای مقدار صفر هستند
شما میتوانید
نمونهای از bitset
ایجاد کنید که مقدار آن توسط یک رشته حرفی مشخص میشود، و حاوی دنبالهای از صفرها
و یکها است:
bitset <5> fiveBits (“10101”); // 10101 5 بت با مقدار
ایجاد یک bitset از روی دیگری بسادگی
انجام میگیرد:
bitset <8> eightBitsCopy(eightbits);
برخی از
نمونهسازیهای bitset
در لیست 25.1 نمایش داده شدهاند.
لیست 25.1 ایجاد یک std::bitset
0: #include
<bitset>
1: #include
<iostream>
2: #include
<string>
3:
4: int main ()
5: {
6: using namespace std;
7:
8: // bitset نمونهسازی یک شیء از کلاس
9: bitset <4> fourBits; // 4 bits initialized to 0000
10: cout << “Initial contents of fourBits: “ << fourBits << endl;
11:
12: bitset <5> fiveBits (“10101”); // 5 bits 10101
13: cout << “Initial contents of fiveBits: “ << fiveBits << endl;
14:
15: bitset <8> eightbits (255); // 8 بیت که محتوای آنها را مقدار دودویی عدد 255 تشکیل داده
16: cout << “Initial contents of eightBits: “ << eightbits << endl;
17:
18: //از روی دیگری bitset ایجاد یک
19: bitset <8> eightBitsCopy(eightbits);
20:
21: return 0;
22: }
خروجی برنامه▼
Initial contents of fourBits: 0000
Initial contents of fiveBits: 10101
Initial contents of eightBits: 11111111
تحلیل برنامه▼
برنامه
چهار روش مختلف برای ایجاد یک شیء از کلاس bitset را نمایش میدهد. همانطور که در خط 9 دیده میشود،
سازنده پیشفرض
به بیتهای دنباله مقدار 0 میدهد. در خط 12،
برای مقدار دهی یک bitset
از یک رشته سبک-C
استفاده شده که حاوی دنبالهای از صفرها و یکها است. توجه داشته باشید که در هر
یک این نمونهسازیها شما باید بعنوان پارامتر الگویی، تعداد بیتهایی را که bitset قرار است در خود نگاه
دارد مشخص کنید. این عدد در زمان کامپایل تعیین میشود و ثابت است، و درنتیجه پویا
نیست. در بردارها، شما میتوانید اعضایی را در آنها درج کنید که تعدادشان بیشتر از
اندازهای است که در زمان کامپایل برای بردار مشخص شده، ولی در مورد bitset نمیتوانید بیتهای
بیشتری از آنچه در برنامه مشخص کردهاید را در آن بگنجانید.
کلاس bitset متدهایی را ارائه میدهد
که کمک میکنند تا بیتها را در آن درج کنید، بیتها را روشن یا خاموش کنید، مقدار
آنها را بخوانید، و یا آنها را دریک جریان خروجی بنویسید. این کلاس همچنین عملگرهایی را ارائه
میدهد که کمک میکنند محتوای یک bitset
نمایش داده شود و عملیات منطقی مختلف را بر روی آنها انجام شود.
در درس 12
شما با عملگرها آشنا شدید، همچنین یادگرفتید که مهمترین نقشی که عملگرها در یک
کلاس بر عهده دارند بالا بردن سهولت استفاده از کلاس است. کلاس std::bitset نیز تعدادی عملگر ارائه میدهد، که همانطور که در جدول 25.1
نشان داده شده، کار با این کلاس را واقعاً ساده میکنند. کاربرد این عملگرها با
استفاده از یک bitset
بنام fourBits
توضیح داده میشوند.
جدول
25.1 عملگرهایی که کلاس std::bitset از آنها پشتیبانی میکند
|
توضیحات |
عملگر |
|
متنی که نشان دهنده دنبالهایی از بیتها است را در جریان خروجی درج میکند: cout << fourBits; |
operator<< |
|
رشتهای را در یک شیء bitset درج میکند: “0101” >> fourBits; |
operator>> |
|
عمل وَی منطقی را انجام میدهد: bitset <4> result
(fourBits1 & fourBits2); |
operator& |
|
عمل یای منطقی را انجام میدهد: bitset <4> result
(fourBits1 | fourBits2); |
operator| |
|
عمل یای انحصاری منطقی را انجام میدهد: bitset <4> result
(fourBits1 ^ fourBits2); |
operator^ |
|
عمل نقیض منطقی را انجام میدهد: bitset <4> result
(~fourBits1); |
operator~ |
|
عمل انتقال بیتی به سمت راست را انجام میدهد: fourBits >>= (2);
// دو بیت را به سمت راست انتقال میدهد |
operator>>= |
|
عمل انتقال بیتی به سمت چپ را انجام میدهد: fourBits <<= (2);
// دو بیت را به سمت چپ انتقال میدهد |
operator<<=| |
|
ارجایی به بیت nام دنباله بازمیگرداند: fourBits [2] = 0; // مقدار بیت سوم را
برابر 0 قرار میدهد bool bNum = fourBits
[2]; // مقدار بیت سوم را میخواند |
operator [N] |
علاوه بر موارد ذکر شده، std::bitset همچنین عملگرهایی
نظیر |=، &=، ^=، و ~= را ارائه میدهد که در انجام عملیات بیتی بر
روی یک شیء bitset
کمک میکنند.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
برنامهنویسان
C++
الزاماً نیازی به کاربرد اشارهگرهای معمولی برای مدیریت حافظه آزاد (heap) ندارند؛ آنها میتوانند برای
این منظور از اشارهگرهای هوشمند استفاده
کنند.
در این
درس شما یاد خواهید گرفت که:
§
اشارهگرهای هوشمند چیستند و چرا به آنها نیاز داریم
§
اشارهگرهای هوشمند چگونه پیادهسازی میشوند
§
گونههای مختلف اشارهگرهای
هوشمند
§
چرا از اشارهگر std::auto_ptr که حالا تقبیح شده
نباید استفاده کرد
§
اشارهگر هوشمند جدید C++11
: std::unique_ptr
§
کتابخانههای محبوب اشارهگرهای
هوشمند
اگر
بخواهیم خیلی ساده بگوئیم،
یک اشارهگر هوشمند
کلاسی است با عملگرهای سربارگزاری شده، که مانند یک اشارهگر معمولی رفتار میکنند.
با اینحال، اشارهگرهای هوشمند تضمین
میدهند که دادههایی که بصورت پویا تخصیص حافظه یافتهاند به نحو مناسب و به
موقعی تخریب شوند.
برخلاف
دیگر زبانهای بنامهنویسی جدید که بیشتر کارها بدون نظارت برنامهنویس و بصورت
خودکار انجام میشود، C++ کلیه مدیریتهای
مربوط به حافظه، از قبیل تخصیص و آزادسازی، را کلاً در اختیار برنامهنویس قرار
میدهد. متاسفانه این انعطافپذیری حالت یک شمشیر دو لبه را دارد. از یک سو این
توانایی موجب قدرتمندتر بودن زبان C++ میشود، و از سوی دیگر به برنامهنویس اجازه میدهد تا مشکلاتی را ایجاد
کند که به تخصیص حافظه مربوط هستند. عمدهترین این مشکلات نَشتِ حافظه است. این
مشکل زمانی بروز میکند که حافظهای که بصورت پویا تخصیص یافته، پس از مصرف درست
آزاد نشود.
برای
مثال:
CData *pData = mObject.GetData ();
/*
تخصیص داده شده؟ newبصورت پویا توسط بهآن
اشاره میکند، pData سوالات: آیا شیئی که
چه
کسی عمل حذف را انجام میدهد: کسی که تابع را فراخوانی کرده یا چیزی که فراخوانی
شده؟
جواب: اصلاً معلوم نیست!
*/
pData->Display ();
در کد بالا هیچ راهی نیست که بتوان به یکی از سئوالات زیر در مورد حافظهای که pData به آن اشاره میکند پاسخ داد:
§ آیا حافظه تخصیص یافته از قسمت فضای آزاد
(یا هیپ) تخصیص یافته، و نهایتاً باید آزاد گردد؟
§
آیا این وظیفه فراخوان است که
حافظه را آزاد کند؟
§
آیا حافظه توسط تخریبگر شیء
بصورت خودکار آزاد میشود؟
هر چند
میتوان این ابهامات را با برنامهنویسی بهتر، و درج توضیحات تا حدی برطرف کرد، ولی این مانع نمیشود که
کلیه مشکلاتی که بواسطه سوء استفاده از اشارهگرها پدید میآید برطرف شوند.
با توجه
به مشکلاتی که در استفاده از اشارهگرهای معمولی برای مدیریت حافظه وجود دارد،
باید به این نکته اشاره کرد که اگر برنامهنویس حافظهایی را در هیپ مدیریت میکند،
مجبور نیست از این نوع اشارهگرها و یا روشهای قدیمی استفاده کند. در اینجا برنامهنویس
با استفاده از اشارهگرهای هوشمند میتواند
از روشهای هوشمندتری برای تخصیص و مدیریت دادههای پویا بهره ببرد:
smart_pointer<CData> spData = mObject.GetData ();
// استفاده از یک اشارهگر هوشمند
درست مانند یک اشارهگر معمولی!
spData->Display ();
(*spData).Display
();
// لازم نیست نگران آزادسازی باشید
// (زیرا تخریبگر اشارهگر هوشمند این کار را برای شما انجام میدهد)
بنابراین اشارهگرهای هوشمند مانند اشارهگرهای معمولی (که حالا به آنها اشارهگرهای خام گفته میشود) رفتار میکنند. ولی آنها با عملگرهای سربارگزاری شده و تخریبگرهایی که ارائه میدهند، تضمین میکنند که دادههایی که بصورت پویا تخصیص یافتهاند، بنحو مناسبی آزاد خواهند شد.
بجای جواب
به این سئوال، فعلاً میتوان سئوال سادهتری را مطرح کرد و پرسید ” اشارهگرهای
هوشمند چگونه
میتوانند مانند اشارهگرهای معمولی عمل کند؟“ جواب این است: به منظور اینکه
برنامهنویس بتواند اشارهگرهای هوشمند را مانند اشارهگرهای معمولی بکار ببرد،
کلاسهای مربوط به آنها عملگر ارجاعزدایی
(*) و نیز
عملگر انتخاب عضو (->) را سربارگزاری میکنند. سربارگزاری عملگرها قبلاً
در درس 12 شرح داده شد.
علاوه
براین، به منظور اینکه شما این توانایی را داشته باشید تا گونه مورد نظر خود را در
هیپ مدیریت کنید، تقریباً تمام کلاسهای اشارهگرِ هوشمند بصورت کلاسهای الگویی
تعریف میشوند که عملکرد کلی آنها را دربر دارد. الگویی بودن آنها باعث میشود که
انعطاف بیشتری داشته باشند و بتوانند از طریق ویژهسازی، اشیا مورد نظر را به نحو
بهتری مدیریت کنند.
در لیست
26.1 نمونهای از یک اشارهگرِ هوشمندِ ساده پیادهسازی شده است.
لیست 26.1 حداقل اجزاء اساسی که یک کلاس اشارهگر هوشمند باید دارا باشد
0: template
<typename T>
1: class
smart_pointer
2: {
3: private:
4: T* m_pRawPointer;
5: public:
6: smart_pointer (T* pData) : m_pRawPointer (pData) {} //سازنده
7: ~smart_pointer () {delete pData;}; // تخریبگر
8:
9: // سازنده کپی
10: smart_pointer (const smart_pointer & anotherSP);
11: // عملگر کپی نسبت دهی
12: smart_pointer& operator= (const smart_pointer& anotherSP);
13:
14: T& operator* () const //عملگر ارجاعزدایی
15: {
16: return *(m_pRawPointer);
17: }
18:
19: T* operator-> () const //عملگر انتخاب عضو
20: {
21: return m_pRawPointer;
22: }
23: };
تحلیل برنامه▼
کلاس
اشارهگر هوشمندی
که در بالا تعریف شده، پیاده سازی دو عملگر *
و -> را نشان میدهد که به
ترتیب در خطوط 17-14 و 22-19 تعریف شدهاند. این دو عملگر باعث میشوند تا این
کلاس مانند یک ”اشارهگر“ عمل کند. برای نمونه، به منظور اینکه از اشارهگر هوشمند
بر روی گونهای از کلاس Tuna
استفاده کنید، کافی است تا نمونهای از آن را بصورت زیر ایجاد کنید:
smart_pointer <Tuna> pSmartTuna (new Tuna);
pSmartTuna->Swim();
//
Alternatively:
(*pSmartDog).Swim
();
کلاس فوق
چیزی نمایش نمیدهد و هنوز هم هیچگونه عملکرد خاصی در آن پیادهسازی نشده
تا نسبت به اشارهگرهای معمولی مزیتی داشته باشد. همانطور که در خط 6 دیده میشود،
سازنده این
کلاس بعنوان پارامتر یک اشارهگر میگیرد،
و بطور داخلی از آن بعنوان اشارهگر اصلی خود استفاده میکند. این اشارهگر توسط
تخریبگر آزاد میشود، و این به معنی آزادسازی خودکارِ فضای اختصاص داده شده است.
اگر یک کلاس ادعا کند که یک اشارهگر
”هوشمند“ است، حداقل چیزهای که باید در آن پیاده سازی شده باشند این موارد است:
سازنده کپی، عملگر نسبت دهی، و تخریبگر. هنگامی که یک اشارهگر هوشمند به تابعی فرستاده
میشود، یا هنگامی که به دیگری نسبت داده میشود، و یا وقتی که از حوزه خارج میشود
(یعنی وقتی تخریب میشود)، عملگرهای ذکر شده رفتار اشارهگر هوشمند را تعیین میکنند.
بنابراین قبل از اینکه به موضوع پیادهسازی کامل اشارهگرهای هوشمند بپردازیم،
بهتر است با انواع مختلف آنها آشنایی پیدا کنید.
چیزی که
کلاسهای اشارهگرهِ هوشمند را از هم متمایز میکند مدیریت منابع حافظه است.
هنگامی که اشارهگرهای هوشمند کپی
میشوند، و یا به دیگری نسبت داده میشوند، در همان موقع تصمیم میگیرند که با
منابعی که به آن اشاره میکنند چه کاری را انجام دهند. اگر اشارهگر خیلی ساده پیادهسازی شده باشد، اغلب این باعث کاهش سرعت آن میشود،
درحالی که آنهای که از نظر سرعت بهینه شدهاند ممکن است برای تمام برنامهها مناسب
نباشند. نهایتاً، پیش از اینکه اشارهگر هوشمندی در برنامه بکار گرفته شود، این با
برنامهنویس است که از عملکرد آن درک مناسبی داشته باشد.
معمولاً
طبقه بندی اشارهگرهای هوشمند بر
اساس روشهایی است که آنها منابع خودشان را مدیریت میکنند، و عبارتند از:
§
کپی عمقی
§
کپی درهنگام نوشتن (Copy on Write (COW))
§
شمارش ارجاع
§
ارجاع پیوندی
§
کپی مخرب
پیش از
اینکه بسراغ اشارهگر هوشمند
C++
در STL، یعنی std::unique_ptr، برویم اجازه دهید تا
نگاه مختصری به هر یک از این روشها بیاندازیم.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
شما در
سراسر این کتاب از جریانها استفاده کردهاید، حتی در درس اول هم که پیام ”Hello World“ را روی صفحه نمایش
دادید، از جریان std::cout استفاده کردید. حالا وقت آن فرا رسیده که این بخش از زبان C++
را مورد بررسی قرار دهیم و از نقطه نظر عملی با جریانها آشنا شویم.
در این
درس شما یاد خواهید گرفت که:
§
جریانها چیستند و چگونه بکار
میروند
§
چگونه بوسیله جریانها فایلها
را بخوانیم و یا در داخل آنها بنویسیم
§
عملیات مفید جریانی در C++
شما در
بیشتر اوقات نیاز دارید تا برنامهای بنویسید که اطلاعاتی را از دیسک بخواند، دادههایی
را روی صفحه نمایش بنویسد، اطلاعاتی را که کاربر توسط صفحه کلید وارد میکند بخواند، و یا دادههایی را روی
دیسک ذخیره کند. آیا مفید نخواهد بود اگر شما بتوانید کلیه فعالیتهای خواندن و
نوشتن اطلاعات را، صرف نظر از اینکه اطلاعات از چه دستگاهی خوانده یا نوشته میشوند،
به روشی انجام دهید که از یک الگوی یکسان پیروی کنند؟ این دقیقاً همان چیزی است که
جریانها برای شما فراهم میکند!
جریانهای
C++،
پیادهسازی عام خواندن و نوشتن (بعبارتی ورودی و خروجی)
هستند که شما را قادر میکنند تا با پیروی از الگوهای یکسان، اطلاعات را بخوانید
یا بنویسید. صرفنظر از اینکه شما اطلاعات را از یک دیسک میخوانید یا از یک صفحهکلید،
یا دادهها را روی صفحه مینویسید یا روی دیسک، این الگوها یکسان هستند. تنها کاری
که باید انجام دهید انتخاب نوع درست ”کلاسِ جریان“ است، و بقیه کارها توسط خود
کلاس انجام خواهد شد.
اجازه
دهید تا اولین خطی که شما در لیست 1.1 این کتاب با آن روبرو شدید را در نظر
بگیریم:
std::cout << “Hello World!” << std::endl;
درست است،
std::cout یک شیء جریانی از
کلاس ostream است که برای خروجی
کنسول از آن استفاده میشود. برای استفاده از std::cout شما باید فایل سرآمد <iostream>شامل کنید. در این فایل کلیه عملکردهای
مختلف این جریان، و نیز عملکردهای دیگری نظیر std::cin، که اجازه میدهد شما از داخل
جریان اطلاعاتی را بخوانید، تعریف شدهاند.
ولی وقتی
من میگویم ”جریانها اجازه میدهند از طریق الگوی یکسانی، که به نوع دستگاه بستگی
ندارد، اطلاعات را خواند یا نوشت“ منظور من چیست؟ اجازه دهید برای روشنتر شدن
مطلب مثالی را بیاورم: اگر شما بخواهید رشته “Hello World!”
را در یک جریانِ فایلی بنام fsHW
بنویسید، باید به نحو زیر عمل کنید:
fsHW << “Hello World!” << endl; //در یک جریان فایلی “Hello World!” نوشتن
همانطور
که میبینید، وقتی شما نوع درستی از جریان را انتخاب میکنید، نوشتن رشته “Hello
World!” در یک فایل با نوشتن آن در صفه نمایش تفاوت زیادی نمیکند.
عملگر (<<) هنگامی بکار میرود که بخواهیم در
جریان بنویسیم. در اینجا نام آن ”عملگر درج در جریان“ است. برای نوشتن در صفحهنمایش،
فایلها، و ... نیز از همین عملگر استفاده میشود.
عملگر (>>) هنگامی بکار میرود که بخواهیم
جریان را بخوانیم. در اینجا نام آن ”عملگر استخراج از جریان“ است. شما از همین عملگر
برای خواندن از صفحه کلید، فایلها، و ... استفاده میکنید.
با این
مقدمه، در این درس ما جریانها را از جنبه عملی بررسی میکنیم.
زبان C++
مجموعهای از کلاسها و فایلهای سرآمد را در اختیار شما قرار میدهد که میتوانند
در انجام بسیاری از عملیات مهم I/O (ورودی/خروجی) به شما
کمک کنند. جدول 27.1 فهرست کلاسهایی را نشان میدهد که غالباً از آنها استفاده میشود.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
از عنوان
این درس پیداست که موضوع آن چیست: بر طرف کردن شرایط غیر عادی، که روند اجرای
برنامه را متوقف میکنند. درسهایی که تا به حال ارائه کردیم رویکرد مثبتی به
اوضاع داشت، ما همیشه فرض میکردیم که تخصیص حافظه بدون هیچ مشکلی انجام میشود،
فایلهای مورد نظر همیشه پیدا میشوند، و غیره. ولی واقعیت چیز دیگری است.
در این
درس شما یاد خواهید گرفت که:
§
یک اعتراض چیست
§
چگونه به اعتراضات رسیدگی کنیم
§
چگونه رسیدگی به اعتراضات موجب میشود تا برنامههای شما پایدارتر
شوند
شما
برنامهای مینویسید که بصورت پویا تخصیص حافظه میکند، و یا عملیات سنگین خواندن
و نوشتن بر روی فایلها را انجام میدهد، و یا کارهایی مشابهی را انجام میدهد. همه
چیز در محیط کاری شما بدون نقص و اشکال کار میکند. برنامهتان میتواند با یک
گیگا بایت از حافظه کار کند،
و حتی به اندازه یک بایت هم هدردهی حافظه (leak) ندارد، و این باعث
افتخار شما است! بعداً برنامه خود را در اختیار مصرف کنندهای قرار میدهید که
دارای هزار ایستگاه کاری (workstation) است. برخی از این
کامپیوترها نسبتاً قدیمی هستند، و برنامه شما روی آنها به کندی پیش میرود، و حتی
متوقف میشود. طولی نمیکشد که سر و کله اولین شکایتها در صندوق پستی شما پیدا
شود. برخی از این شکایتها حاکی از این هستند که کامپیوتر به آنها خطای دسترسی
غیر مجاز داده (Access Violation)، و برخی نیز خطای اعتراض رسیدگی نشده (Unhandled Exception) را دریافت کردهاند.
معلوم است
که برنامه شما روی کامپیوترهای خودتان بخوبی کار میکرد، پس در اینجا کلماتی مثل
”اعتراض“ و یا ”رسیدگی نشده“ چه معنی میدهند؟
واقعیت
این است که دنیای بیرون بسیار ناهمگن است. هیچ دو کامپیوتری، حتی کامپیوترهای که
از نظر سخت افزاری دارای پیکرهبندی (configuration) واحدی هستند، مثل
یکدیگر نیستند. زیرا چیزی که تعیین میکند چه منابعی آزادند و میتوان از آنها
استفاده کرد، وضعیت فعلی
دستگاه و نیز نرمافزارهایی است که بر روی هر کدام از این دستگاهها در حال اجرا
هستند. بنابراین، احتمالاً به همین دلیل است که تخصیص حافظهای که بخوبی روی
کامپیوتر شما کار میکند، در محیط دیگر درست کار نمیکند.
چنین نقصهایی
نادر هستند، ولی با اینحال اتفاق میافتند. این نقصها به چیزی منجر میشوند که ”اعتراض“ (exception)
نام دارد.
اعتراضات
روند عادی اجرای برنامه را مختل میکنند. هر چه باشد، اگر حافظه کافی وجود
نداشته باشد، هیچ راهی وجود نخواهد داشت تا برنامه شما کاری را که برای آن طرح ریزی
شده انجام دهد. ولی با اینحال این امکان وجود دارد تا برنامه شما به
اعتراض پیش آمده رسیدگی کند، پیام مناسبی را برای کاربر نمایش دهد، و اگر ممکن باشد،
برخی اقدامات جایگزین را انجام دهد و نهایتاً بصورت برازندهای خارج شود.
رسیدگی به
اعتراضات میتواند
به شما کمک کند تا دیگر ایمیلهایی با مضمون ”Access Violation“یا ”Unhandled Exception“ را دریافت نکنید.
اجازه دهید تا ببینیم C++ چه ابزارهایی را برای رسیدگی
به اعتراضات در اختیار شما قرار میدهد.
اعتراضات
میتواند به عوامل خارجی، مثل کمبود منابع، یا به عوامل داخلی، مثل استفاده از یک
اشارهگر نامعتبر
و یا تقسیم یک عدد بر صفر، ربط داشته باشد. برخی از ماجولها طوری طرح ریزی شدهاند
که هنگامی که با چنین خطاهایی روبر میشوند از خود اعتراض بروز دهند.
برای اینکه در برنامههای خود از بروز اعتراضات
جلوگیری کنید، باید اصتلاحاً به آنها رسیدگی (handle) کنید، و گرنه این اعتراضات
به کاربرِ برنامه منتقل خواهد شد.
در میان
کلیدواژههای C++،
try
و catch از مهمترینها بحساب میآیند، زیرا برای جلوگیری از اعتراضات از آنها
استفاده میشود. شما برای اینکه از بروز اعتراض در عبارات جلوگیری کنید، باید آنها را در
داخل یک بلوک try
محصور کنید و بلافاصله در یک بلوک catch که بدنبال آن
میآید دستوراتی را که مربوط به رسیدگی به اعتراضات هستند قرار دهید. چنین ترکیبی بصورت زیر
است:
void SomeFunc()
{
try
{
int* pNumber = new int;
*pNumber = 999;
delete pNumber;
}
catch(...) // کلیه اعتراضات را بگیر و در زیر به آنها رسیدگی کن
{
cout << “Exception in SomeFunc(), quitting” << endl;
}
}
بخاطر
دارید در درس 8 من اشاره کردم که شکل پیشفرض new درصورتی که تخصیص
حافظه با موفقیت انجام شود یک اشارهگر معتبر به مکان تخصیص یافته بازمیگرداند، و اگر
عملیات با شکست روبرو شود یک اعتراض از
خود بروز میدهد. لیست 28.1 برنامهای را نشان میدهد که در آن شما میتوانید با
رسیدگی به اعتراض، عمل تخصیص حافظه را ایمن کنید.
لیست 28.1 استفاده از try و catch برای رسیدگی به اعتراض مربوط به تخصیص حافظه
0: #include <iostream>
1: using
namespace std;
2:
3: int main()
4: {
5: cout << “Enter number of integers you wish to reserve: “;
6: try
7: {
8: int Input = 0;
9: cin >> Input;
10:
11: // درخواست حافظه و بازگرداندن آن
12: int* pReservedInts = new int [Input];
13: delete[] pReservedInts;
14: }
15: catch (...)
16: {
17: cout << “Exception encountered. Got to end, sorry!” << endl;
18: }
19: return 0;
20: }
خروجی برنامه▼
Enter number of integers you wish to reserve: -1
Exception encountered. Got to end, sorry!
تحلیل برنامه▼
برای این
مثال، من مخصوصاً عدد (1-) را برای مقدار حافظهای که باید کنار گذاشته شود انتخاب کردهام. این مقدار مضحک است، ولی
باید توجه داشته باشید که کاربران همیشه بطور ناخواسته کارهای مضحکی را انجام میدهند!
در غیاب بلوکی که به اعتراضات رسیدگی میکند، برنامه با پایان ناخوشآیندی روبرو
میشود. ولی به لطف این بلوک (بلوک catch) شما پیام ”Got to end, sorry!“ را دریافت میکنید.
اگر شما این برنامه را در ویژوآل استودیو و
در حالت debug اجرا کنید، ممکن است با پیامی شبیه به آنچه در شکل 28.1
نشان داده شده مواجه شوید:
شکل 28.1: تاکید بر نامعتبر بودن میزان حافظه درخواست شده
در اینحالت دکمه Ignore را فشار دهید تا بلوک مربوط به رسیدگی به اعتراض که شما در برنامه نوشتهاید وارد کار شود. این پیام جنبه اشکالزدایی دارد، ولی رسیدگی به اعتراضات باعث میشود برنامه شما در
حالت release هم پایان تمیزی داشته باشد.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
شما در
این کتاب با اصول برنامهنویسی C++ آشنا شدید. در حقیقت
یادگیری شما از جنبه نظری فراتر رفت و فهمیدید که چگونه STL و الگوها میتوانند برای نوشتن برنامههای
کارآمدتر و کوتاهتر به شما کمک کنند. حالا وقت آن رسیده تا ببینیم از نظر سرعت و
عملکرد، چه شیوههایی میتواند برای برنامهنویسی مناسبتر باشد.
در این
درس شما یاد خواهید گرفت که:
§
پردازندههای امروزی چه تفاوتی
با گذشته دارند
§
چگونه برنامه C++
شما میتواند بهترین بهره را از پردازنده کسب کند
§
ریسمانها و چندریسمانی
§
بهترین شیوهها در برنامه نویس
C++
§
توسعه مهارتهای C++
فرای این کتاب
تا چندی پیش، عملکرد کامپیوترها فقط توسط پردازندهها
افزایش مییافت، پردازندههایی که هر سال بر سرعت پردازش آنها افزوده میشد. این
سرعت بر حسب هرتز (Hz)،
مگاهرتز (Mhz)، و یا گیگاهرتز (GHz) اندازهگیری میشود. برای
مثال پردازنده 8086 (که در شکل 29.1 دیده میشود) یک پردازنده
16-بیتی بود که با سرعتی معادل 10 MHz در سال 1978به بازار
آمد.

شکل 29.1 پردازنده اینتل 8086
آن زمان، دورانی بود که هر ساله بر سرعت پردازندهها
افزوده میشد و در نتیجه سرعت عملکرد برنامههای C++
شما هم افزایش مییافت. آن موقع برای بهبود عملکرد برنامه تنها کافی بود که منتظر
نشست تا سر و کله سختافزارهای سریعتری پیدا شوند. هرچند امروزه نیز پردازندهها
سریعتر میشوند، ولی بهبود واقعی، نه در میزان سرعت، بلکه در زیادتر شدن تعداد
هستههایی است که یک پردازنده میتواند در خود داشته باشد. در هنگام نگارش این
کتاب، شرکت اینتل پردازندهها 64-بیتی به بازار داده که دارای 8 هسته هستند و سرعت
آنها به 4 گیگا هرتر میرسد، و هر چه جلوتر میرویم، گرایش به زیادتر شدن تعداد
هستهها افزایش مییابد. در شکل 29.2 یک پردازنده چند هستهای اینتل دیده میشود.
در واقع، حتی تلفنهای هوشمند نیز دارای پردازندههای چند هستهای هستند.

شکل 29.2 یک پردازنده چند هستهای اینتل
شما میتوانید
یک پردازنده چند هستهای را مانند چیپ (chip) تنهایی تصور کنید که
در آن چندین پردازنده قرار گرفته که بصورت موازی با هم کار میکنند. هر پردازنده
برای خود دارای یک کش L1 (L1
cache) است و میتواند مستقل از بقیه کار کند.
طبیعی است که با افزایش سرعت پردازنده، سرعت عملکرد
برنامه شما هم افزایش یابد. ولی پردازندههای چند هسته چه نقشی میتوانند در این
مورد داشته باشند؟ واضح است که هر هسته میتواند بصورت موازی با بقیه، یک برنامه
را اجرا کند، ولی این باعث نمیشود تا سرعت اجرای برنامه شما سریعتر شود. برنامههای
تک-ریسمانی (Single-threaded)
C++
که تاکنون با آنها سر و کار داشتید، از قافله عقبند و نمیتوانند از قابلیتهای
پردازندههای چند-هستهای استفاده کنند. در شکل 29.3 شما یک برنامه تک-ریسمانی را
میبینید که تنها از یک هسته استفاده میکند، ولی برنامههای چند-ریسمانی میتوانند
از چندین پردازنده بهره ببرند.
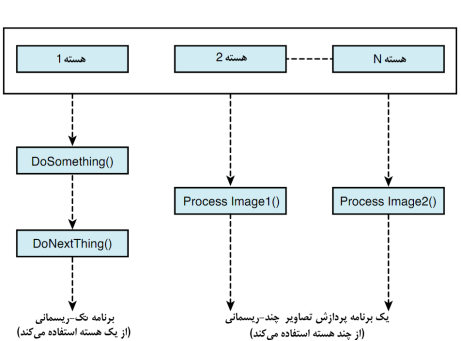
شکل 29.3 یک برنامه تک-ریسمانی که در یک پردازنده
چند هستهای اجرا شده است.
اگر
برنامه شما طوری طراحی شده باشد که در آن عملیات مختلف بصورت سریالی و متوالی
انجام گیرند، در این صورت احتمالاً سیستم عامل (OS) به شما همانقدر فرصت میدهد
که به برنامههای دیگری که در صف منتظر
هستند.
این نوع برنامهها تنها یک هسته را اشغال میکنند. به عبارت دیگر، اجرای این نوع برنامهها بر روی یک
پردازنده چند هستهای، تفاوتی با دوران قدیم و پردازندههای تک هستهای نخواهد
داشت.
...........................................
برای ادامه مطالعه این فصل نسخه کامل PDF کتاب را تهیه کنید.
[1] - vi برنامه استاندارد کُنسولی ویرایش متن در سیستمهای مبتنی بر یونیکس و لینوکس است (مترجم).
[2]
- به دستورات پیشپردازنده، راهنما یا هادی پیشپردازنده هم میگویند. (مترجم)
[3]
- به صفحه نمایشهای ساده قدیمی، و یا پنجرههای غیر گرافیکی، که تنها میتوانند
متن را در خود نمایش دهند کنسول (console) میگویند. کنسول
همچنین میتواند به دستگاه (یا برنامهای) اشاره کند که بیشتر از کیبورد برای ورود
اطلاعات استفاده میشود و در آنها ابزارهایی مثل ماوس بکار نمیرود، و یا اگر هم
میرود کاربرد آن خیلی محدود است
(مترجم).
[4]
- در زبانهای مبتنی بر C (C++، #C ...) این امکان وجود دارد که تابع مقداری را
بازنگرداند برای اینکار باید قبل نام تابع ”void“
را قید کرد. توضیحات بیشتر
در ادامه خواهد آمد (مترجم).
[5]
- در بیشتر کامپایلرهای جدید توضیحات برنامه میتوانند به هر زبانی (از جمله فارسی) نوشته
شود. اگر در متن برنامه از زبان فارسی استفاده میکنید، تنها مسئلهای که باید به
آن توجه کرد نوع فرمت ذخیره برنامه است، که معمولاً این فرمت باید UTF8 باشد (مترجم).
[6] - Random
Access Memory (حافظه
دستیابی تصادفی).
[7]
- درمقابل آرایههای ایستا، ما آرایههای پویا (dynamic) را داریم که نه
تعداد عضوهای آن از ابتدا مشخص است، و نه مکان و میزان حافظهای که مصرف میکنند. در
درسهای آتی توضیحات مفصلتری
در مورد آرایههای پویا خواهد آمد (مترجم).
[8]
- در بعضی از کتابها پیشنمونه را
”نمونه اولیه“ هم ترجمه کردهاند (مترجم).
[9]
- در برخی از کتابها Encapsulation را کپسولهبندی و لفافهبندی هم ترجمه کردهاند
که بنظر مترجم لغت ”ادغام سازی“
نسبت به آنها گویاتر است.
[10]
- منظور از ”رابطه هستی“ این است که مثلاً بگوئیم ”یک انسان یک پستاندار است“،
یا بگوئیم ”کبوتر یک پرنده است“، که در اینجا رابطه بین انسان و
پستاندار، و یا کبوتر و پرنده، یک ”رابطه هستی“ (is-a relationship) است. در جدول 10.1
نیز کلیه چیزهایی که در کلاسهای منشعب قرار دارند نوعی از کلاس پایه هستند، و در نتیجه رابطه هستی بین آنها برقرار است
(مترجم).
[11]
- Platypus یا ”نوکاردکی“، پرنده
پستانداری است که در جنوب استرالیا زندگی میکند (مترجم).
[12]
- خواننده توجه دارد که در اینجا منظور از تُن، کنسرو ماهی نیست. تُن گونهای از
ماهی است، و آنچه به ”تُن ماهی“ معروف است از گوشت این ماهی گرفته میشود (مترجم).
[13]
- ویژهسازی یعنی
تغییر دادن چیزی، بصورتی که بتوان از آن برای کار بخصوصی (ویژهای) استفاده کرد.
ما در وراثت یک
کلاس پایه را
برای این منشعب میکنیم که بتوانیم با هر یک از زیرکلاسهای منشعب شده کار ویژهای
انجام دهیم که قبلاً توسط کلاس پایه امکان آن وجود نداشت. بنابراین میتوان گفت که
هر یک از کلاسهای منشعب شده، کلاس پایه خود را ویژهسازی میکنند.
[14]
- تبدیل گونه را در بعضی کتابها قالببندی هم ترجمه کردهاند.
[15] - RunTime Type Identificationor = RTTI (تشخیص گونه زماناجراء)
[16]
- API مخفف Application
programming interface، به معنای رابط برنامهنویسی
نرمافزار است، و شامل کلیه توابع و ساختارهایی است که در یک محیط نرمافزاری بزرگ
(مثل یک سیستمعامل) در اختیار توسعه دهندگان قرار میگیرد تا با استفاده از آنها
برنامههای خود را بسازند (مترجم).
[17]
- وقتی گفته میشود یک برنامه غیرقابل حمل است، این به این معنی است که نمیتوان
آن را روی سیستمعاملهای و یا سختافزارهای دیگر منتقل کرد و انتظار داشت کارایی
موجود خود را حفظ کند.
[18] - STL= Standard Template Library
[19]
- گُنجانه (continer) در برخی از کتابها
محفظه، ظرف، و کانتینر نیز ترجمه شده. کلاً یک گنجانه را میتوان بصورت چیزی تصور
کرد که اشیایی در آن گذاشته، یا به عبارتی گنجانده، میشوند (مترجم).
[20]
- برای توضیح بیشتر درمورد کاربرد لغت بردار به زیرنویس صفحه دوم از فصل 17 رجوع کنید.
[21]
- همانطور که ممکن است بسیاری از خوانندگان بدانند، لغت vector
در علوم ریاضی و فیزیک به معنای بردار است و در هر یک از این حوزهها نیز تعریف خاص خود را
دارد. متاسفانه کاربرد این لغت برای نامیدن آرایههای پویا در C++ انتخاب مناسبی نبوده، زیرا شباهتهای اندکی بین مفهوم
بردار و آرایههای پویا وجود دارد. تنها شباهتی که میان یک آرایه و یک بردار میتواند وجود داشته باشد، در
تعریف بردارهای ردیفی (Row vector)
بعنوان یک ماتریس یک بعدی است که میتوان آن را به یک آرایه شبیه دانست. بنابراین
هرجا در این کتاب به لغت بردار اشاره میشود، منظور آن مفهومی است که در C++ دارد و نه معنی متداول آن در فیزیک و ریاضی (مترجم).
[22]
- منظور از عقب آرایه انتهای
آن است (یعنی جای که آخرین عضو قرار گرفته). به همین ترتیب، هر جا به جلو آرایه
اشاره شود منظور ابتدای آن است
(یعنی جای که اولین عضو قرار گرفته). (مترجم)
[23]
- در این مثال ساده، وضعیت فقط
شامل تعداد دفعاتی است که تابع فراخوانی میشود. اما در برنامههای عملی وضعیت (یا
حالت) میتواند شامل موارد دیگری نیز باشد که به ماهیت
برنامه بستگی دارند (مترجم).
[24]
- البته انسان میتواند چنین کاری بکند و از وسط یا ته یک ستون از بشقابها یکی را
بردارد، ولی اصلاً چرا باید چنین کاری را انجام دهد؟ اگر قرار بود بتواند هر
بشقابی را که خواست بردارد، و یا در لابلای این ستون بشقابی را بگذارد، در آنصورت
آنها را بصورت افقی میچیدند و نه به صورت ستونی! حتی در برنامه نویسی هم میتوان
با ترفندهای خاصی از وسط یا ته یک پشته اطلاعاتی را استخراج، و یا درج کرد. ولی
همانگونه که انجام چنین کارهای برای بشقابها موجب خرابکاری میشود، در مورد پشتههای
نرمافزاری نیز همینطور است، یعنی اگر کسی بخواهد رفتار برنامه را تغییر دهد، میتواند
پشته آن را دستکاری کند. در واقع یکی از روشهایی که برای هِک کردن برنامهها وجود
دارد دستکاری پشته است. (مترجم)